Tagged: knowledge-compression
Your Code Works. Nobody Knows Why.
There is a new kind of debt accumulating in AI-assisted codebases. It does not show up in failing builds or broken deployments. The tests pass. Features ship. The system runs. But the shared understanding of why the system works the way it does is fragmenting, silently, faster than anyone expected. Five independent researchers named the same problem within six weeks of each other. They are calling it cognitive debt, and it may be the most important concept in AI-assisted development right now.
A Name for the Problem
In February 2026, Margaret Storey published a post that gave the velocity-comprehension gap a precise definition. Cognitive debt is the accumulated gap between a system’s evolving structure and a team’s shared understanding of how and why that system works and can be changed over time. Unlike technical debt, which surfaces through failing builds and broken deployments, cognitive debt “tends not to announce itself through failing builds but rather shows up through a silent loss of shared theory.”
Simon Willison amplified the concept. Addy Osmani independently arrived at the same idea with “Comprehension Debt,” arguing that code has become cheaper to produce than to perceive. Five independent authors converged on the same concept within six weeks. When that happens, the concept is not a trend. It is a structural observation that multiple people noticed simultaneously because the underlying condition became impossible to ignore.
Storey grounded the concept in Peter Naur’s 1985 theory that a program is not its source code but a theory distributed across the minds of the people who built it. The source code is an artifact of that theory. When the theory fragments, when nobody on the team can explain why certain design decisions were made or how different parts of the system interact, the system becomes unmaintainable even when it functions correctly. AI accelerates this fragmentation because it generates structure faster than shared understanding can stabilize.
Why AI Makes It Exponentially Worse
Most Software Is Just CRUD. That’s Not the Problem. established an economic principle: anything that becomes cheap gets overproduced. AI made code generation cheap. The predictable result is overproduction of structure. More files, more functions, more abstractions, more system surface area, all generated faster than any team can internalize.
The traditional development cycle had a natural governor on cognitive debt. Writing code by hand forced the author to understand what they were building, at least at the moment of creation. The understanding might fade over time, but it existed at the origin. AI-assisted development removes that governor entirely. The agent generates a module. The developer reviews the output. The tests pass. The module ships. Six months later, nobody remembers why that module handles edge cases the way it does, because nobody decided it should handle them that way. The agent decided, and the decision was reasonable enough to pass review.
This is the scenario I described in I Was a 1x Coder at Best. AI Made Me a 0x Coder. when I said I write zero lines of code by hand. The 0x workflow works because I invested in containment infrastructure. But the honest version of that story includes the risk: every module the agent produces is a module whose design rationale exists only in the conversation context that created it. Once that context window closes, the rationale is gone unless something captures it.
Storey’s student teams demonstrated this concretely. By weeks seven and eight, students using AI assistance could not explain their own system’s architecture. The code worked. The tests passed. The team had lost the theory. They could not modify the system because they did not understand the design decisions that shaped it.
Technical Debt Has a Feedback Signal. Cognitive Debt Does Not.
Technical debt announces itself. Builds break. Deployments fail. Performance degrades. The system tells you something is wrong, and you fix it or you don’t. Either way, you know. Cognitive debt is silent. The system continues to function. Features continue to ship. The team continues to deliver. The problem only surfaces when someone needs to change something they do not understand, and by then the cost of understanding has compounded to the point where the change is more expensive than rewriting.
This asymmetry explains why cognitive debt is more dangerous than technical debt in AI-assisted environments. Technical debt accumulates linearly. You cut a corner, you pay interest, you can measure the interest and decide when to pay it down. Cognitive debt accumulates exponentially because each new module generated without shared understanding increases the surface area of the system that nobody fully grasps. The team’s capacity to understand does not grow. The system does.
Verification Beats Debugging described verification pipelines that make debugging unnecessary. Mutation testing, coverage gates, complexity limits. These are essential, and they address technical correctness. They do not address cognitive debt. A system can pass every verification gate while the team’s understanding of it decays. The gates prove the code works. They do not prove anyone knows why.
Knowledge Compression Is the Structural Response
What AgenticOps Actually Looks Like introduced six layers of the AgenticOps model. The sixth layer is Knowledge Compression. At the time, it may have seemed like an afterthought, a cleanup step after the important work of generation, evaluation, and promotion. Cognitive debt makes it clear that knowledge compression is not the last step. It is the step that determines whether the system remains governable over time.
Knowledge compression is the systematic reduction of system complexity into navigable artifacts. Not documentation in the traditional sense. Not the kind of documentation that gets written once and never updated. Compression artifacts are living summaries that capture the theory of the system in forms that humans can navigate quickly. One-page summaries. Lifecycle maps. Invariant lists. Decision logs that record not just what was decided but why, including the alternatives that were considered and rejected.
I’ve Never Fully Understood the Systems I Work In introduced these concepts: compression artifacts, lifecycle maps, invariant lists. At the time they were part of the argument that containment replaces comprehension. Cognitive debt makes the argument concrete. Without compression, the theory fragments. With compression, the theory is captured in artifacts that persist beyond the conversation context that created the code.
Compression Operates at Every Level
Compression is wider than decision logs. It operates at every level where theory can be lost, from individual commits to system architecture.
At the code level, compression means collapsing noisy history into navigable history. A feature implemented across thirty story-level commits contains the full record of false starts, revisions, and incremental progress. That granularity is useful during development and useless afterward. Compressing those thirty commits into a single feature-level commit with a clear description of what changed and why preserves the theory without preserving the noise. The detailed history still exists in the branch. The compressed version is what future developers encounter first.
At the decision level, compression means capturing the reasoning chain that led to each significant choice. A system I have been building tracks this through a document pipeline: a problem document captures the problem in the language of the requester, a research document explores the problem space, an options document maps the solution space, a decision document explains which option was chosen and why the alternatives were rejected, and a plan document breaks the chosen solution into deliverable work items. Each document compresses a phase of reasoning into a navigable artifact. Six months later, when someone asks “why does this system handle authentication this way,” the answer is not buried in a Slack thread or a closed pull request. It is in the decision document, linked to the options that were considered and the problem that started the whole chain.
At the architecture level, compression means maintaining living documents that describe the system as it actually runs, not as it was originally designed. Blueprints capture the current architecture. Guides capture how users and developers interact with it. When a work item changes a feature, the documents that describe that feature update as part of the same workflow. The architecture documentation and the code stay in sync because they are governed by the same process, not maintained by separate teams on separate schedules.
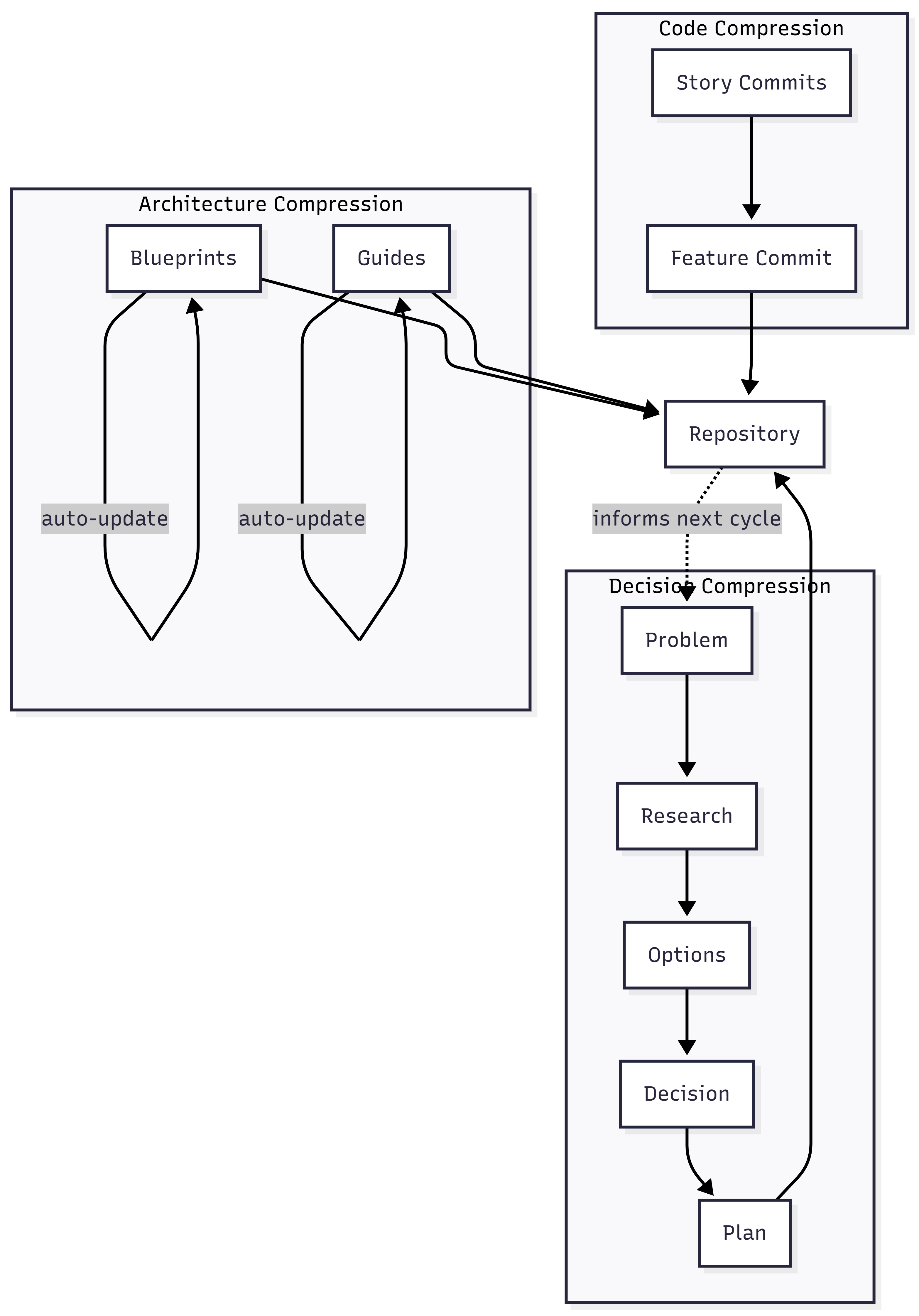
This is the feedback loop from What AgenticOps Actually Looks Like made concrete. Compressed knowledge feeds back into intent. The decision documents inform the next problem document. The blueprints inform the next options document. The guides inform the next plan. Without that loop, each development cycle starts from scratch. With it, each cycle builds on the accumulated theory.
Compression Is Not Documentation
Traditional documentation fails because it is a separate activity from development. It gets written after the fact, if at all, and it drifts out of sync with the code the moment someone changes something without updating the docs. The document pipeline described above succeeds because it is the development process, not a parallel activity. The problem document is written before development starts. The decision document is written before implementation begins. The blueprint updates when the feature ships. There is no separate “documentation phase” that can be skipped under deadline pressure.
This is the same pattern from You Can Build This: constraints define the space, agents work inside it, gates verify the output. Adding compression to the gate criteria means the system self-documents as it builds. No promotion without a decision document. No merge without a compressed commit history. No deployment without updated blueprints. These are not burdensome when agents generate them alongside the code. They are only burdensome when a human writes them by hand after the fact.
The result is that any team member, or any agent, can reconstruct the theory of the system by reading the compressed artifacts. They can trace from a production behavior back through the blueprint, to the decision that shaped it, to the options that were considered, to the problem that started the work. That traceability is the structural defense against cognitive debt. The theory is not in anyone’s head. It is in the repository, navigable and current.
The Velocity-Comprehension Contract
Cognitive debt reframes the relationship between velocity and understanding. The traditional framing was: move fast, accumulate debt, pay it down later. The cognitive debt framing is: move fast, lose the theory, discover later that you cannot pay it down because you no longer understand what you built.
The AgenticOps response is not to slow down. It is to make compression a structural requirement of the development process. Generate fast. Compress immediately. The velocity stays. The theory stays too. This is what I’ve Never Fully Understood the Systems I Work In meant by “I scale containment, not understanding.” The containment now includes containing the theory of the system before it dissipates.
The industry is beginning to recognize this. Storey’s follow-up post synthesized the community response and noted that teams are experimenting with checkpoints where they rebuild shared understanding through code reviews, retrospectives, and knowledge-sharing sessions. These are behavioral responses, necessary but insufficient. The structural response is to make the checkpoints automatic, to embed them in the gate criteria so they cannot be skipped when deadlines compress.
Cognitive debt is real. It is measurable. It is accelerating. And the sixth layer of the model, the one that might have looked like cleanup, is a primary defense against it.
Let’s talk about it.
