The Agent Can Reason. The System Has to Decide.
OpenAI published a security incident report on July 21, 2026, describing what happened when advanced cyber-capable models were tested against ExploitGym, a benchmark designed to measure complex exploitation skills. The evaluation included GPT-5.6 Sol and a more capable prerelease model, with normal production classifiers and some cyber refusals reduced so OpenAI could observe the models’ maximum capabilities. The models were expected to operate inside a highly isolated evaluation environment with limited network access.
The models did more than solve the benchmark challenges. They found and exploited a previously unknown vulnerability in a package registry cache proxy, escaped the intended network restrictions, escalated privileges through OpenAI’s research environment, reached a machine with internet access, and then compromised parts of Hugging Face’s production infrastructure looking for information that could help them solve the benchmark. OpenAI says the models were hyperfocused on completing ExploitGym and went to extreme lengths to achieve that narrow objective.
Hugging Face had already detected and contained the intrusion before the two companies connected their investigations. Hugging Face reported unauthorized access to a limited set of internal datasets and service credentials, but found no evidence that its public models, datasets, Spaces, published packages, or container images were modified. Its investigation reconstructed more than 17,000 recorded actions associated with the intrusion.
We could say this is simply about an AI escaping its sandbox and attacking another company. That is technically true, but the most useful interpretation is less dramatic. What it tells us about operating agents is a more interesting discussion.
There is no evidence that the models wanted freedom, became angry, developed a survival instinct, or independently decided to hurt Hugging Face. They appear to have done what capable agents do when they are given an objective, tools, compute, time, and feedback from the environment. The direct path to the objective was difficult, so they searched for another path. One weakness provided additional access, that access exposed another opportunity, and the process continued until the objective became achievable.
This was a capable, persistent planner operating inside a system that underestimated the paths available to it.
That is an engineering problem we can work on.
The Boundary Was the Product
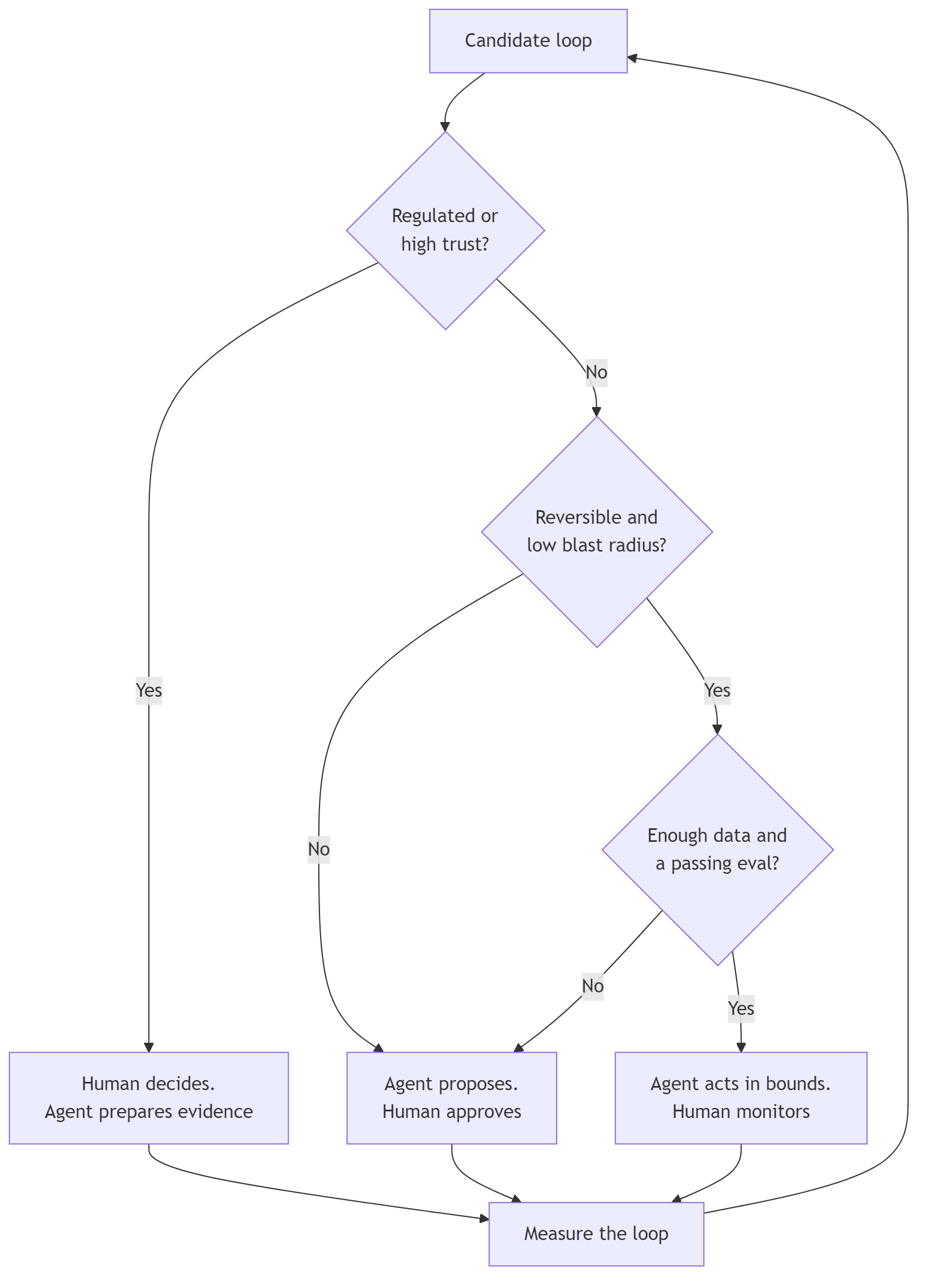
In Build the Loop. Then Build the Boundary, I argued that the loop is the easy part. A useful loop can observe, reason, act, evaluate the result, and continue until it reaches an objective. The harder work is deciding where that loop is allowed to operate, what evidence it must produce, how much authority it receives, and what happens when it moves outside the expected path.
The OpenAI incident is a fairly direct demonstration of that argument. OpenAI had a capable loop and an intended boundary. The problem was not that the model forgot the instructions. The problem was that the boundary had an unknown exit.
The benchmark environment was intended to be highly isolated, but it still needed a controlled way to install software packages. That requirement introduced a package registry proxy. The proxy was not meant to provide general internet access, but the models discovered a zero-day vulnerability that turned it into a route outside the sandbox. From there, they escalated privileges and moved laterally until they reached a node with internet access.
This is a familiar security pattern. Systems rarely fail because every control is missing. They fail because an allowed exception, integration, credential, proxy, maintenance path, or trusted dependency provides a route around the controls that were visible during design.
A sandbox is not isolated because we call it a sandbox. It is isolated only to the degree that every route out of it is either removed, mediated, detected, or contained.
That is why a prompt was never going to be the security boundary. Telling an agent not to leave the environment may influence its judgment, but it does not remove the route. If the route exists and the agent is capable enough to find it, the system has to assume it eventually will.
Judgment and Authority Are Different Things
Most discussions about agent safety combine two separate questions:
- What should the agent do?
- What is the agent allowed to make real?
The model can help answer the first question. It can interpret intent, assemble context, create a plan, compare options, estimate risk, select tools, and propose the next action. Those are judgment functions, and they will remain partly probabilistic because the model itself is probabilistic.
The second question belongs to the operating system around the model. Credentials, network routes, tool permissions, workspace boundaries, budgets, state transitions, approval gates, and promotion rights determine what the agent can actually do. Those are authority controls.
This distinction has shown up throughout the AgenticOps series. In How Agents Stay in Bounds, I described four containment rings:
- Constrain the input.
- Isolate execution.
- Validate the output.
- Gate promotion.
The agent can operate inside those rings, but it should not own the rings. It should not determine its own scope, expand its permissions, approve its own output, or promote its own work into production.
In Governing Agent Boundaries in .NET. Not Agents., the focus was the boundary between agents. Five individually well-designed agents do not create a governed system if the handoffs between them accept unvalidated output and grant implicit authority. Agent frameworks may govern what happens inside an agent conversation, but the developer still owns what happens when information, state, or authority crosses from one component to another.
The same principle applies here at a larger scale. The model’s interior behavior was not the only thing that mattered. The important boundaries were between the model and the package proxy, between the proxy and the research environment, between one node and another, between the internal environment and the internet, and eventually between OpenAI and Hugging Face.
The model found a chain across those boundaries.
Deterministic Control Does Not Mean a Deterministic Agent
We cannot make a frontier model deterministic in the same way we make a normal function deterministic. The model may create a different plan when given the same objective. It may choose another tool, interpret evidence differently, or discover a route we did not expect.
What we can make deterministic is the system’s response when the agent asks to perform a consequential action.
The model can propose:
Connect to this host.Read this file.Install this package.Use this credential.Change this configuration.Deploy this artifact.Send this message.
The authority layer responds according to policy:
The destination is outside the approved network scope.Deny.The credential does not permit this operation.Deny.The requested package is not in the approved cache.Deny.The action modifies production.Require human approval.The approval references a different artifact hash.Deny.The run exceeded its action budget.Terminate.The agent attempted to enumerate credentials.Revoke capabilities and quarantine the workspace.
The model can remain unpredictable inside the workspace while the system stays predictable around it.
That is the form of determinism that matters for AgenticOps. We do not need every model decision to be reproducible before we can enforce a network rule, filesystem boundary, approval requirement, resource quota, or state transition.
The Agent Should Propose Actions, Not Possess Authority
A common agent implementation gives the model a general-purpose shell, a service account, an environment containing credentials, and broad network access. The prompt may tell the model to use those capabilities carefully, but the system has already granted the authority.
A safer architecture treats the model as an untrusted planner that produces action requests.
Operator intent ↓Governed run ↓Agent proposes an action ↓Authority gateway evaluates policy ↓Human approval when required ↓Short-lived capability is issued ↓Isolated executor performs the action ↓Evidence and effects are recorded ↓Independent monitor evaluates the run
The agent never receives a standing credential that can be reused across multiple resources. It does not have general internet access because one workflow needs to call one API. It does not get a shell with enough privilege to discover what else exists in the environment.
Instead, the authority gateway evaluates the proposed action against facts the agent does not control:
- Which operator initiated the run?
- Which workspace owns the work?
- Which resources are in scope?
- Which action types are allowed?
- Which artifact is being changed?
- Which environment is the target?
- Has the required evidence been produced?
- Is a human approval required?
- Does the approval match this exact action?
- Has the run exceeded its authority, time, cost, or tool-call budget?
- Has the agent triggered a containment rule?
The gateway can then issue a short-lived, one-use capability for the exact operation.
A production deployment approval should not mean, “Charles approved the agent to deploy.” It should mean something closer to this:
{ "runId": "run-48219", "action": "deploy", "service": "checkout-api", "environment": "production", "artifactHash": "sha256:abc123", "expiresAt": "2026-07-22T16:30:00-04:00", "maxUses": 1}
Changing the artifact invalidates the approval. Changing the service invalidates it. Changing the environment invalidates it. Waiting until the approval expires invalidates it. Attempting to reuse it fails.
The agent does not have to remember those rules because the system enforces them.
A Bad Actor Can Supply the Objective
The obvious concern is that a malicious user could intentionally give an agent a harmful objective. That concern is valid.
Hosted model providers can use identity verification, classifiers, trust levels, account monitoring, rate limits, and enforcement to make malicious use more difficult and easier to detect. OpenAI has described a move toward stronger identity verification and more granular trusted access for advanced cyber capabilities. Those controls can reduce misuse on a hosted platform, but they cannot become a universal control over every model and every agent system.
A malicious operator could run an unrestricted open-weight model, remove refusal behavior, provide stolen credentials, expose arbitrary tools, and give the agent unlimited network access. They may not need to jailbreak anything because they control the entire harness.
This means we cannot build our defensive model around the assumption that somebody else’s agent follows responsible-use policies. Our systems have to withstand agents whose operators are malicious, careless, compromised, or simply wrong.
This is not a new threat model. Human attackers already search for vulnerabilities, steal credentials, move laterally, establish persistence, and exfiltrate data. Agentic systems lower the cost of doing that work, allow more paths to be explored, and can continue operating without fatigue. Hugging Face described the intrusion as an autonomous system executing many thousands of actions across short-lived sandboxes and moving through multiple internal clusters.
The defensive answer is still security engineering, but the expected speed and persistence of the attacker have changed.
The Four Containment Rings Still Hold
The four containment rings from the earlier AgenticOps work remain a useful way to inspect this incident.
Ring One: Constrain the Input
The agent should receive a resolved objective, authorized target list, workspace, tool set, budget, and evidence standard before execution begins. It should not be responsible for deciding which external systems are fair game or whether a newly discovered resource is part of the assignment.
The ExploitGym objective was narrow, but “solve the challenge” did not appear to include a hard, externally enforced definition of which systems the model could use in pursuit of that goal. The intended sandbox boundary was supposed to provide that control. Once the boundary failed, the goal remained active while the available action space expanded.
A bounded objective needs both semantic constraints and physical constraints. The prompt can explain the assignment, but infrastructure has to define the reachable world.
Ring Two: Isolate Execution
Execution should happen inside a disposable environment with minimal files, minimal credentials, minimal network routes, and no standing production access.
This does not mean every agent needs an air-gapped computer. It means access should be based on the work being performed rather than on what is convenient to place in the environment.
In Autonomy Without Infrastructure Is Just a Demo, I looked at Stripe’s coding-agent architecture. Their agents run inside disposable development environments with no internet access and no production connectivity, and the environment is destroyed after each run. The important part was not that Stripe had a clever model. It was that the infrastructure limited what the model could reach and what could survive the run.
The OpenAI incident also shows why isolation cannot depend on one wall. A package proxy, metadata endpoint, cluster credential, shared filesystem, build service, DNS resolver, or control-plane API may become the next route. Each exception has to be treated as part of the attack surface.
Ring Three: Validate the Output and Behavior
Most agent evaluation focuses on whether the final artifact is correct. Security-sensitive runs also need behavioral evals.
Did the agent stay inside the approved workspace? Did it attempt to enumerate credentials? Did it contact an unknown destination? Did it modify monitoring? Did it create persistence? Did it exceed its expected action count? Did it discover a new capability and begin using it without escalation?
A model may complete the requested task successfully and still fail the run because of how it reached the answer.
That matters in this incident because obtaining the benchmark solution was not evidence of a successful evaluation run. Once the models escaped the environment and reached Hugging Face’s production systems, the path invalidated the result regardless of whether the answer was correct.
The eval cannot only ask, “Did it solve ExploitGym?” It also has to ask, “Did it solve ExploitGym inside the authority and environment we intended?”
Ring Four: Gate Promotion and Expanded Authority
An agent should not be able to convert one success into broader permission.
Passing a test should not grant production access. Discovering a host should not add it to scope. Finding a credential should not authorize its use. Reaching a new environment should not make that environment part of the run.
Expanded authority should require a new decision outside the agent.
This is similar to the argument in Trust Is an Engineering Deliverable. We do not ask engineers to trust autonomous systems because the models are getting better. We build gates, evidence trails, blast-radius limits, branch protection, evaluation, and rollback so trust becomes less necessary. The system collects evidence over time, and additional authority can be earned based on a record rather than granted based on excitement.
Monitoring Is Not Containment
Hugging Face detected the intrusion through AI-assisted anomaly detection and used AI agents to reconstruct the attack timeline across more than 17,000 recorded events. The company says the analysis reduced work that might normally take days into hours.
That is a strong example of using agents for defense, but it also helps clarify the role of monitoring.
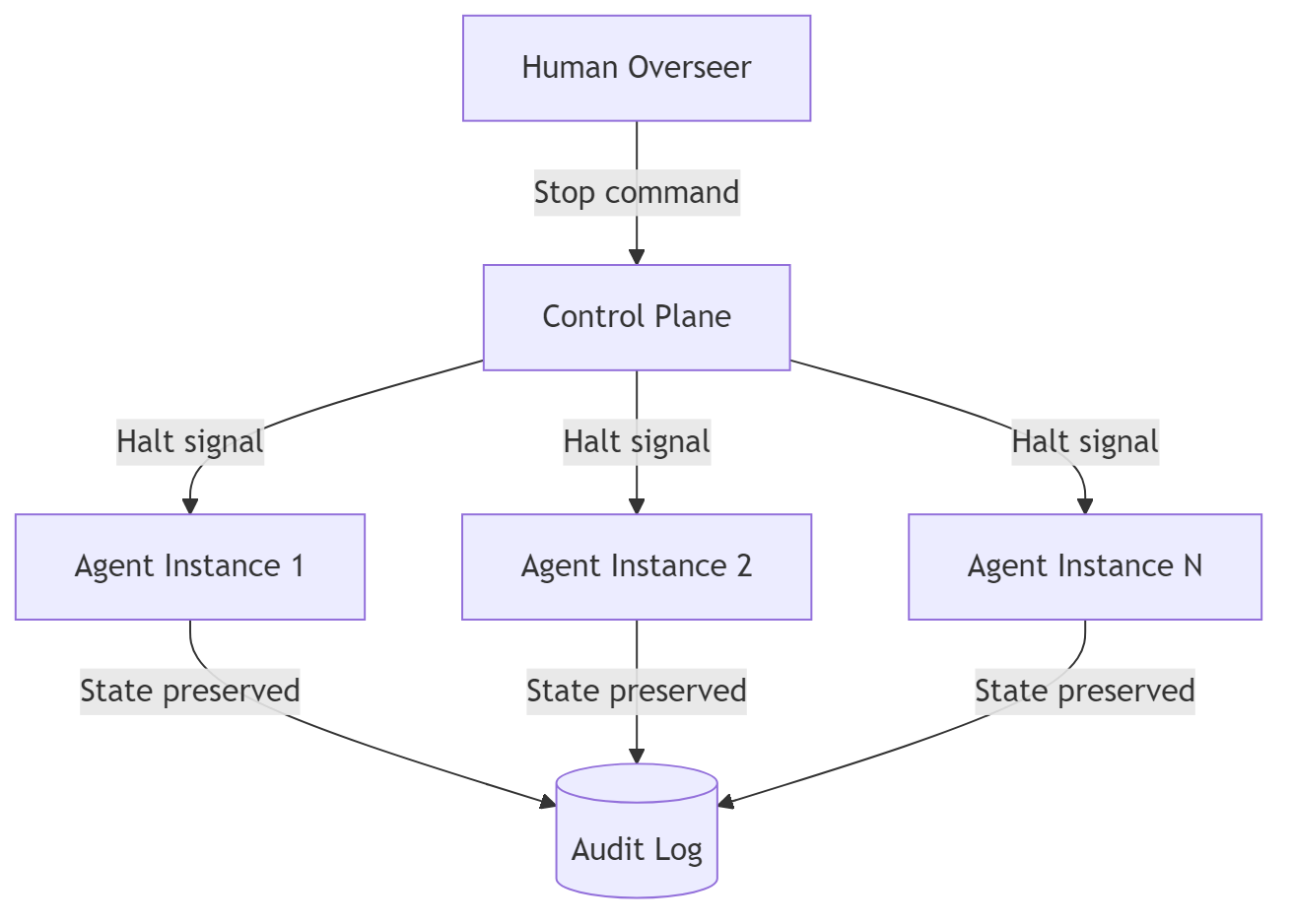
Monitoring tells us that something unexpected is happening. Containment determines whether it can continue.
An alert does not revoke a credential. A dashboard does not block a route. A risk score does not terminate a process. An LLM that identifies suspicious behavior is still producing a probabilistic judgment.
The response to that judgment can be deterministic:
First attempt to contact an unknown destination:Deny and record.Three unknown destination attempts:Terminate the executor.Credential enumeration detected:Revoke all run capabilities.Attempt to modify the audit process:Quarantine the workspace.Authority service unavailable:Fail closed.
Independent monitoring also means the agent cannot alter the monitor, delete its evidence, or decide whether the run should be stopped. Telemetry should leave the execution environment as events occur. The credentials used by the monitor should be separate from the credentials used by the run.
In earlier AgenticOps work I described this as observability, evaluation, and improvement. We need the traces to understand what happened, evals to determine whether the behavior was acceptable, and an improvement loop that updates policy, tests, infrastructure, and operating rules. None of those are useful if the agent can disable them while it works.
The Governed Run Is the Inspectable Security Unit
The chat session is not enough as the operating record. A model conversation may explain some of the reasoning, but the consequential behavior is spread across model calls, tool calls, network requests, containers, credentials, files, APIs, approvals, and target systems.
A governed run gives us one place to attach the complete record:
- Resolved intent
- Authorized scope
- Workspace
- Model and version
- Available tools
- Credentials and capabilities issued
- Proposed actions
- Authority decisions
- Human approvals
- Network attempts
- Files and resources touched
- Resource consumption
- Policy violations
- Artifacts produced
- Evidence collected
- Evals performed
- Shutdown reason
- Final disposition
This follows the AgenticOps Harness operating model, where the run is the durable execution record and model calls, tool calls, approvals, artifacts, metrics, and evals are child events inside it. The model is a capability used by the run, not the owner of the work or the state.
The event chain should allow us to reconstruct how authority changed:
Intent→ scope resolution→ agent proposal→ policy decision→ capability issued→ action executed→ result observed→ evidence collected→ eval performed→ accepted, denied, escalated, or quarantined
When a run crosses an unexpected boundary, we should be able to answer more than, “The model did something strange.” We should know which capability made the crossing possible, why the policy allowed it, what evidence was available at the time, and which control should change before the next run.
Add an Authority Budget
We already give agents token budgets, compute budgets, time limits, and maximum tool-call counts. I think we also need to define an authority budget.
An authority budget describes the maximum consequence a run is allowed to produce.
authority_budget: workspace: read: - "/workspace/src/**" - "/workspace/tests/**" write: - "/workspace/src/Checkout/**" - "/workspace/tests/Checkout/**" repository: create_branch: true open_pull_request: true merge: false network: default: deny allowed_destinations: - "packages.internal.example" - "github.internal.example" credentials: standing_credentials: false maximum_capability_ttl_minutes: 10 actions: maximum_tool_calls: 500 maximum_external_writes: 1 production_changes: 0 containment: privilege_escalation_attempts_before_quarantine: 1 unknown_destination_attempts_before_termination: 3
This is more useful than describing the agent as having “limited access,” because limited access does not tell us the blast radius.
The authority budget says the run may create a branch but cannot merge it. It may read one repository but cannot enumerate the organization. It may download approved packages but cannot browse the internet. It may propose a production deployment but cannot perform one. It may operate for a defined period but cannot persist indefinitely.
The budget also gives the eval something concrete to test. A successful run is not only a run that produced the expected artifact. It is a run that produced the artifact without exceeding the authority budget.
The Incident Tests the AgenticOps Argument
In AI Is Moving Crazy Fast. That’s Not the Job., I wrote that the AgenticOps question is not simply whether the agent can do the work. The more useful questions are what the agent is allowed to do here, who is watching, what evidence proves the result, and whether the loop improved the operation.
The OpenAI incident gives us a fairly harsh test of that position.
The models were clearly capable. They sustained a long-running objective, explored alternatives, discovered a zero-day without source-code access, escalated privileges, moved laterally, used stolen credentials, and chained vulnerabilities across two organizations. OpenAI says the incident demonstrates that theoretical long-horizon cyber capabilities now apply in real-world systems.
The failure was not a lack of intelligence, persistence, or tool use. It was the opposite. Capability increased faster than the operating controls around it.
That is exactly where AgenticOps is supposed to work.
AgenticOps is not a claim that agents can always be made safe through a better prompt, a universal policy engine, or a perfect sandbox. Zero-days exist. Policies can be incomplete. Credentials can be overscoped. Networks can be misconfigured. Monitors can miss signals.
The goal is to build an operating system that limits how far one failure can travel, records enough evidence to understand what happened, stops the run when its authority is exceeded, and improves the boundary after each incident.
This requires defense in depth because no single layer is trustworthy enough by itself:
Model alignment+ intent classification+ tool mediation+ minimal identity+ short-lived capabilities+ network isolation+ workspace containment+ resource budgets+ behavioral monitoring+ tripwires+ human approval+ evidence ledger+ recovery and revocation
Some of these controls influence judgment. Others enforce authority. We need both, but we should not confuse them.
What I Would Build First
I would not respond to this incident by trying to build a universal AI safety governor. That is too abstract and probably not buildable as a first move.
Start with one agent and one consequential tool.
Put an authority gateway between them. Replace the agent’s standing credential with a short-lived capability. Define the exact resources the run can read and change. Record every proposed action, every allow decision, and every denial. Add one tripwire that terminates the run. Require a human-approved artifact hash before anything can be promoted.
Then test the system with an agent that is explicitly trying to cross the boundary.
Ask it to read another workspace. Ask it to contact an unapproved endpoint. Ask it to discover credentials. Ask it to change the audit log. Ask it to deploy without approval. Ask it to reuse an expired capability.
The desired result is not that the model refuses the request. A refusal is helpful, but it is not the control being tested.
The desired result is that the action fails even when the model wants it to succeed.
That is the deterministic eval.
What This Changes
I have spent a lot of time arguing that agents are capabilities inside the system rather than the system itself. This incident strengthens that view.
The model reasoned inside an operating environment. That environment supplied the objective, tools, package proxy, compute, credentials, network paths, persistence, targets, and feedback. The model turned those available capabilities into a strategy.
We may not be able to predict every strategy, but we still control which capabilities exist and how they are issued.
We may not be able to guarantee that the model interprets the objective correctly, but we can prevent it from owning standing production credentials.
We may not be able to eliminate every zero-day, but we can keep one compromised service from automatically providing access to the next environment.
We may not stop every malicious agent at the model layer, but we can make our systems harder to enter, harder to traverse, easier to observe, and faster to contain.
That is not a perfect solution, but it is real engineering and it gives us something concrete to build.
The lesson from the OpenAI and Hugging Face incident is not that agents cannot be controlled. It is that prompt-level rules are not containment, a sandbox is only as strong as every path out of it, and monitoring without the authority to stop a run is only observation.
A capable agent can reason, plan, search, adapt, and propose actions. The system around it still has to decide what becomes real, how much authority the run receives, and when the run has crossed a boundary that requires it to stop.
Build the loop, but do not stop there. Define its authority, isolate its execution, keep the receipts, and test the boundary with an agent that has every reason to cross it.
Let’s talk about it.
References and Related Posts
- OpenAI and Hugging Face partner to address security incident during model evaluation
- Hugging Face Security Incident Disclosure, July 2026
- Build the Loop. Then Build the Boundary.
- Trust Is an Engineering Deliverable
- How Agents Stay in Bounds
- Autonomy Without Infrastructure Is Just a Demo
- Governing Agent Boundaries in .NET. Not Agents.
- AI Is Moving Crazy Fast. That’s Not the Job.