Agent Runtimes Are Infrastructure Now
In the span of eight weeks, four companies shipped agent runtimes targeting the same architectural pattern. OpenClaw went from 9,000 to 68,000 GitHub stars. Perplexity launched Computer. Anthropic launched Dispatch. NVIDIA announced NemoClaw at GTC. A wave of open-source alternatives jumped in too.
They are solving different problems for different audiences. But they converge on the same structural claim: agents need a long-running runtime with containment boundaries, not a chat window.
That convergence is the signal. Agent runtimes are no longer experimental tooling. They are infrastructure and most companies have no plan for running them.
The Problem
Most organizations interact with AI through two modes: chat interfaces and copilot integrations. Both are interactive. A human types, the model responds, the human reviews. The loop is tight. The blast radius is small. The human is always present.
Agent runtimes break that model.
An agent runtime is a persistent process that connects a language model to tools that operate on real systems. It reads files, runs commands, calls APIs, and manages state across sessions. It does not wait for a human to type the next instruction. It plans, executes, evaluates, and continues.
The shift from interactive to autonomous changes everything about how you govern AI in your organization. Permission models designed for copilots do not work when the agent runs overnight. Approval gates designed for chat do not work when the agent has already executed forty tool calls before anyone checks. Cost controls designed for per-query billing do not work when a runtime burns tokens continuously.
Most companies are not ready for this. They have AI policies written for chatbots. They have security reviews scoped to API integrations. They have cost projections based on per-seat licensing.
None of that applies to a long-running autonomous process with tool access.
Why It Breaks
The failure mode is not dramatic. It is gradual.
A team installs OpenClaw on a developer’s machine. It works well for code review and research tasks. Someone gives it shell access. Someone else connects it to the company’s GitHub. A third person sets up a cron job to run it overnight.
No one wrote a containment policy because no one thought of it as infrastructure. It was just a tool someone installed.
Then the agent runtime has persistent access to production repositories, runs unattended, makes commits, and calls external APIs. The blast radius expanded incrementally. Each step seemed reasonable in isolation. The compound effect is an autonomous process with broad access and no governance boundary.
This is the same pattern that produced shadow IT fifteen years ago. Except shadow IT was humans using unauthorized tools. Shadow agents are autonomous processes using authorized tools without authorized oversight.
Three dynamics make this worse than traditional shadow IT.
First, agents are stochastic. The same input does not always produce the same output. A shell command that worked safely yesterday might produce a different command today. Deterministic tools with stochastic invocation is a new failure class.
Second, agents compound. A single tool call is low risk. An agent that chains forty tool calls in sequence can reach states that no individual call would produce. The risk is in the composition, not the components.
Third, agents persist. A copilot session ends when the developer closes the tab. An agent runtime runs until someone stops it. Long-running processes accumulate context, make decisions based on stale state, and operate during hours when no one is watching.
Without containment infrastructure, every team that installs an agent runtime creates an ungoverned autonomous process. Multiply that across an organization and you have a fleet of agents with no central visibility, no consistent policy, and no kill switch.
The Fix
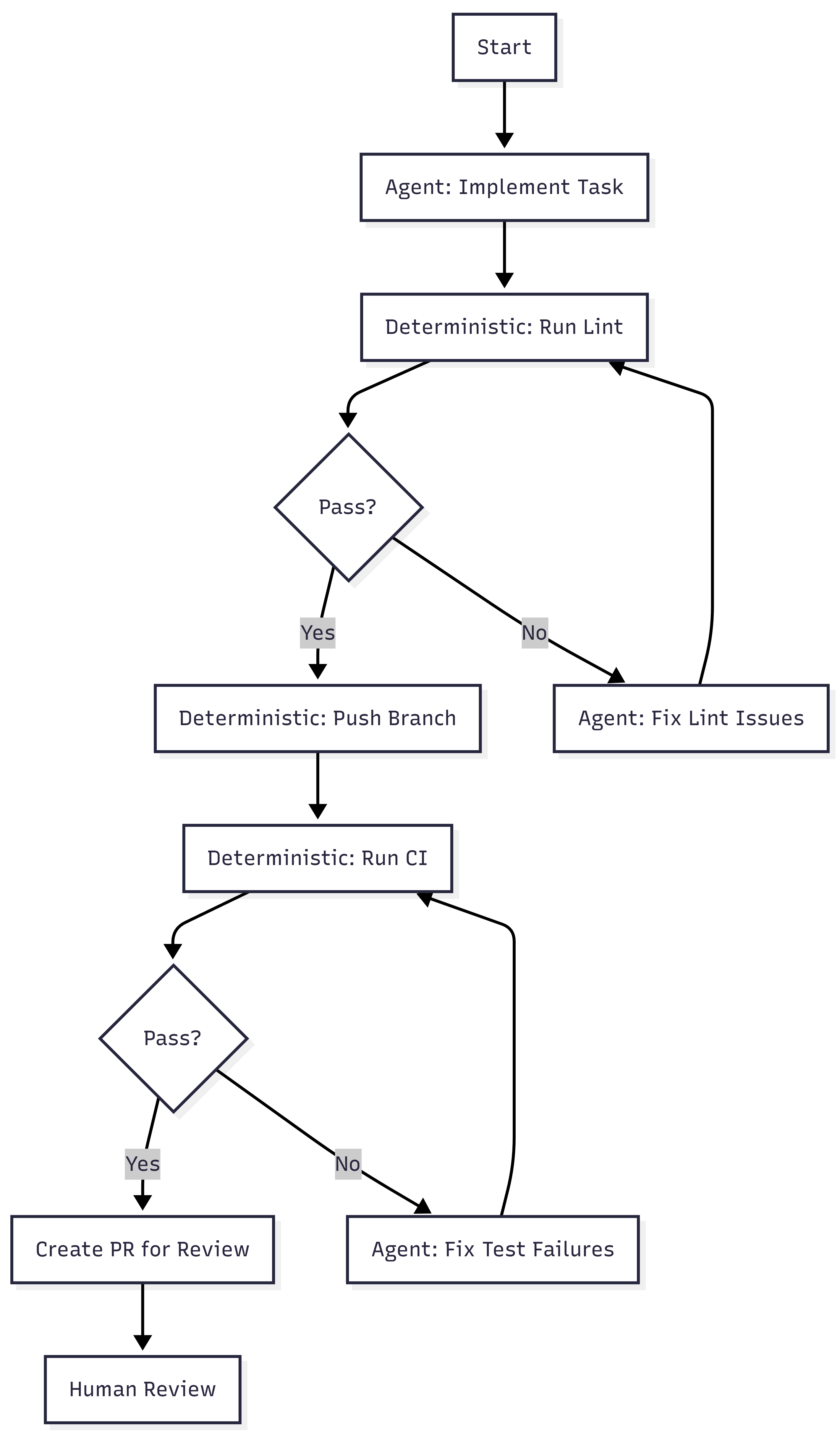
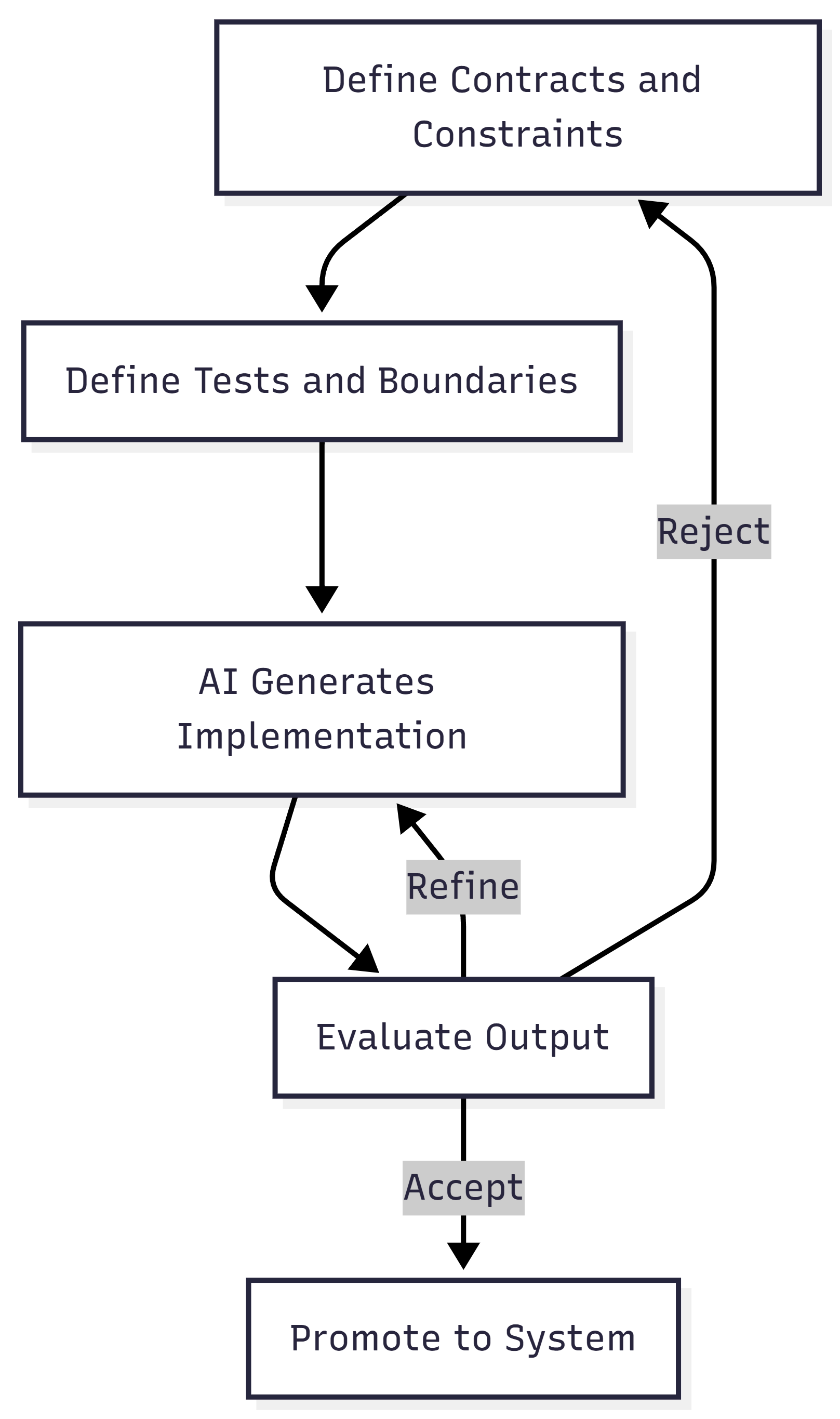
The fix is not a policy document. The fix is treating agent runtimes as infrastructure that requires the same operational discipline as any other long-running service.
Three concrete requirements.
1. Sandboxed Execution with Declarative Policy
Agent tool execution must run inside an isolated environment with policy controls that the agent cannot modify.
This is exactly what NemoClaw’s OpenShell runtime provides. Each agent session runs inside a sandbox with a YAML policy file that declares which files the agent can access, which network endpoints it can reach, and which tools it can invoke.
# openclaw-sandbox.yamlfilesystem: writable: - /sandbox - /tmp read_only: everything_elsenetwork: allowed: - build.nvidia.com - api.anthropic.com denied: everything_elsetools: allowed: - read - write - exec denied: - cron - messaging
The policy is enforced by the runtime, not by the agent. When the agent tries to reach an unlisted host, OpenShell blocks the request. The agent does not get to decide whether the policy applies.
Dispatch takes a different approach to the same problem. Code runs in a sandbox, files stay local, and every destructive action requires user confirmation via push notification. The containment is structural. The agent pauses and waits for human approval before crossing a boundary.
Perplexity Computer takes a third approach. Move everything to the cloud. The agent runs on Perplexity’s infrastructure, not on your machine. Your files, your apps, your network are not directly exposed. The containment boundary is the cloud itself. The tradeoff is control. You gain isolation by giving up locality.
All three approaches enforce the same principle: the environment says “can’t,” not “shouldn’t.”
2. Cost Containment as a Runtime Concern
Long-running agents consume tokens continuously. Without budget enforcement at the runtime level, costs scale with uptime, not with value delivered.
Post 8 in this series described a budget daemon that polls agent sessions every five minutes, calculates token cost deltas, and enforces three tiers: warning at 80%, throttle at 100% of a daily limit, hard kill at a monthly cap. The throttle mechanism writes a flag file and blocks the agent at the gateway level. The agent does not know it has been throttled. It simply cannot start new sessions.
NemoClaw supports local inference through Nemotron models, which eliminates token costs entirely for workloads that can run on local hardware. Instead of metering cloud tokens, you shift inference to hardware you already own.
Perplexity Computer takes a subscription approach. $200 per month for 10,000 credits. After that, per-credit billing. The cost is predictable until it is not. A workflow that runs for hours or months, which Perplexity explicitly supports, can exhaust credits faster than anyone budgeted for. Subscription pricing obscures the relationship between agent activity and cost.
Three different cost models. Token metering, local inference, and subscription credits. All three treat cost as a runtime constraint, not a billing surprise. But only explicit metering gives you the visibility to understand what each agent actually costs.
3. Separation of Build and Run
The agent that builds the runtime must not run inside it. The agent that writes the budget daemon must not have its spending governed by that daemon. The agent that configures the sandbox policy must not be sandboxed by that policy.
This is the structural separation described in Post 8. Claude Code planned and implemented the OpenClaw deployment. At no point did it run inside OpenClaw. The orchestrating agent and the deployed runtime operate in separate containment boundaries.
Dispatch enforces this separation by architecture. The runtime runs on your desktop. The control interface runs on your phone. The command channel is end-to-end encrypted. The agent cannot modify the channel it receives commands through.
Perplexity Computer enforces this separation by moving the entire execution environment to the cloud. The agent runs on Perplexity’s servers. You interact through a client. The agent cannot modify the client or the subscription boundary that governs its compute allocation.
The pattern is consistent across all four systems: the control plane is not subject to the data plane’s constraints.
Four Runtimes, One Pattern
OpenClaw, Perplexity Computer, Dispatch, and NemoClaw approach the problem from different directions. They arrive at the same architecture.
| Property | OpenClaw | Perplexity Computer | Dispatch | NemoClaw |
| Runtime model | Self-hosted Node.js daemon | Cloud-hosted, multi-model orchestration | Managed desktop agent | OpenClaw + OpenShell wrapper |
| Containment | Docker Sandbox, tool sandboxing | Cloud isolation, vendor-managed | Local execution, human gates | YAML policy, filesystem/network isolation |
| Inference | Cloud APIs (bring your own key) | 19 models (Opus 4.6, Gemini, Grok, others) | Anthropic models only | Nemotron local or cloud APIs |
| Cost model | Token metering (user-built) | $200/month subscription + per-credit overage | $100-200/month subscription | Local inference or cloud metering |
| Persistence | JSONL session transcripts | Cloud-managed workflow state | Single persistent conversation | Blueprint-versioned sandbox state |
| Target audience | Developers, self-hosters | Knowledge workers, enterprises | Consumers, knowledge workers | Enterprise, IT teams |
| Governance posture | Configurable, user-managed | Vendor-managed, opaque | Opinionated, Anthropic-managed | Declarative, policy-as-code |
The convergence is in the structural properties, not the implementation details.
All four run as persistent processes, not request-response APIs. All four connect language models to tools that operate on real systems. All four enforce containment boundaries that the agent cannot override. All four separate the control plane from the execution environment.
That is not four companies making the same product. That is four companies independently validating the same architectural pattern.
The Open-Source Wave
The pattern is replicating beyond the major players. OpenClaw’s explosion triggered a wave of open-source agent runtimes, each optimizing for a different constraint.
ZeroClaw is a Rust-native runtime that compiles to a 3.4MB binary and runs on under 5MB of RAM. PicoClaw, written in Go, hit 12,000 GitHub stars in its first week. Nanobot from HKU delivers core agent runtime features in 4,000 lines of Python with 26,800 stars. IronClaw rewrites the entire stack in Rust with WebAssembly sandboxing where every tool starts with zero permissions and must be explicitly granted access.
The common thread is not the language or the size. It is that every one of these projects treats containment as a first-class concern, not a feature request. The early OpenClaw criticism, that it shipped powerful tools with minimal default governance, taught the ecosystem a lesson. The second wave of runtimes launched with sandboxing built in.
That is the pattern maturing in real time.
What This Means for Every Company
The question is no longer whether your organization will run agent runtimes. The question is whether you will govern them before or after they are already running.
OpenClaw has 68,000 GitHub stars. Any developer in your organization can install it in five minutes. Perplexity Computer is a subscription away. Dispatch ships to every Claude Max subscriber. NemoClaw runs on any NVIDIA hardware.
The barrier to deploying an autonomous agent is now lower than the barrier to writing a containment policy for one.
Three things every organization should do now.
First, inventory what is already running. If your developers use Claude Code, Cursor, OpenClaw, or any tool that connects a language model to a shell, you already have agent runtimes in your environment. Most IT teams do not know this. Find out.
Second, define a containment baseline. Not a policy document. An actual runtime configuration that enforces filesystem isolation, network restrictions, and tool allowlists. NemoClaw’s YAML policy format is a reasonable starting point. If you are not using NemoClaw, build the equivalent for whatever runtime your teams use.
Third, treat agent runtime governance as infrastructure, not as AI ethics. The team that owns this is platform engineering or SRE, not the AI committee. The artifacts are sandbox configs, network policies, and budget daemons. The review process is the same one you use for any other production service.
Agent runtimes are not a trend. They are the next layer of compute infrastructure. The companies that learn to run them with containment discipline will compound their capabilities. The companies that ignore them will discover shadow agents the same way they discovered shadow IT. After the damage is visible.
Stories from Production
The OpenClaw Explosion
OpenClaw went from 9,000 to 68,000 GitHub stars in days during late January 2026. Creator Peter Steinberger announced he would join OpenAI, and the project would move to an open-source foundation. The growth was driven by a single property: OpenClaw is a self-hosted agent runtime that you control. No vendor lock-in, model-agnostic, runs on your machine.
Security researchers immediately began demonstrating prompt injection and malicious skill attacks against agents with broad access. CrowdStrike published guidance for security teams. The pattern was exactly what Post 6 in this series predicted: powerful runtime, minimal default containment, governance as an afterthought.
Perplexity shipped Computer on February 25. A cloud-hosted agent runtime that orchestrates 19 different models. Opus 4.6 for reasoning. Gemini for deep research. Grok for lightweight tasks. Workflows that run for hours or months. The pitch was accessibility. Perplexity CEO Aravind Srinivas said, “Even your mum can text the app and delegate tasks.” The containment model is cloud isolation. Your local machine is never exposed because the agent never runs on it.
Then Perplexity shipped the Agent API on March 11. A managed runtime for developers that orchestrates retrieval, tool execution, reasoning, and multi-model fallback. This moved Perplexity from consumer product to infrastructure provider. The same pattern, packaged as a platform.
NVIDIA announced NemoClaw at GTC on March 16. OpenShell sandboxing, YAML policy controls, local Nemotron inference. The enterprise wrapper that OpenClaw needed but could not build as a one-person open-source project.
Anthropic launched Dispatch the same week. A managed desktop agent runtime with structural containment baked in. No shell access unless the sandbox allows it. Destructive actions gated by push notification. End-to-end encryption on the control channel.
Four approaches. Eight weeks. Same pattern. That is convergence.
The Shadow Agent Scenario
A mid-size engineering team installs OpenClaw on developer machines for code review automation. It works well. Someone adds a skill that connects to the company’s Jira instance. Someone else adds GitHub write access. A third developer sets up a scheduled task that runs the agent overnight to triage incoming issues.
Six months later, the agent has made 2,000 commits across twelve repositories, closed 400 issues, and consumed $3,200 in API tokens that no one budgeted for. The security team discovers it during an audit. They have no visibility into what the agent did, no log of which tools it invoked, and no policy that governs its access.
This has not happened yet. But every component exists today. OpenClaw supports scheduled execution. GitHub skills are preconfigured. Token costs are invisible unless you build metering infrastructure. The only thing preventing this scenario is the gap between installation ease and governance maturity. That gap is closing. Fast.
Let’s talk about it.