Category: AgenticOps Applied
Verification Beats Debugging
A few days ago I read a post describing an intense engineering sprint.
In roughly three days the author reported:
- designing and implementing a JVM language
- building a wiki with its own web server
- improving the AI of a strategy game
- creating mutation testing tools
- implementing a differential mutation strategy
All while enforcing strict engineering discipline.
- Coverage above 90%.
- CRAP score under 8.
- Mutation testing enforced.
- Files split when complexity exceeded limits.
When the systems were finally run for the first time, they worked. Not mostly worked. Worked.
That sounds like a miracle if you are used to the normal development loop. The author of that post was Robert C. Martin, often called Uncle Bob, and he reported this in an X post.
But the interesting part is not the accomplishments. It is the engineering loop behind them.
The Normal Development Loop
Most development follows this pattern.
- Write code.
- Run program.
- Debug problems.
- Repeat.
Execution becomes the discovery mechanism for defects. The system runs, something breaks, and we start searching for the cause. This works, but it is inefficient. Debugging becomes the dominant cost of development.
A Verification Loop
The workflow described in the post follows a different structure.
Specification
↓
Acceptance tests (ATDD / Gherkin)
↓
Unit tests (TDD)
↓
Implementation
↓
Run tests and fix failures
↓
Measure coverage and increase it
↓
Measure complexity and reduce it
↓
Run mutation testing
↓
Refactor until all constraints hold
This is not a coding loop. It is a verification loop. The system never moves forward until each layer of verification holds.
Constraints Instead of Discipline
The key insight is that this process does not rely on discipline alone. It relies on constraints enforced by tools.
The system continuously measures:
- code coverage
- cyclomatic complexity
- CRAP score
- mutation score
If the metrics fail, the code must be changed.
This turns engineering practice into infrastructure. Instead of relying on developers to remember best practices, the system requires them.
Code Coverage
Code coverage measures how much of the codebase is executed by the test suite.
Coverage tools typically track several dimensions:
- line coverage
- branch coverage
- function coverage
Coverage answers a basic but important question. Did the tests actually execute the code? If large portions of the system are never exercised during testing, defects can hide in those paths.
Higher coverage increases the probability that tests interact with most of the system. Many teams set a minimum threshold such as:
- coverage ≥ 80%
- coverage ≥ 90% for critical systems
In the workflow described earlier, coverage was kept above 90%.
Coverage alone does not guarantee correctness. It only tells us that code executed during testing. That is why coverage must be combined with stronger signals like mutation testing.
Mutation Testing
Mutation testing strengthens traditional testing.
Traditional tests answer one question: Did the code run? Mutation testing asks a stronger question: If the code were wrong, would the tests detect it?
A mutation engine introduces small semantic changes into the code:
- flipping boolean conditions
- changing comparison operators
- altering arithmetic
- removing conditions
Each change creates a mutant version of the program.
If the tests fail, the mutant is killed. If the tests pass, the mutant survived. A high mutation score means the tests actually verify behavior.
Execution coverage proves code runs. Mutation coverage proves the tests detect incorrect behavior.
Cyclomatic Complexity
Cyclomatic complexity measures how many independent execution paths exist through a function.
Each branch increases the number of paths.
Examples include:
- `if` statements
- loops
- logical operators
- conditional expressions
More paths means more scenarios that must be tested and reasoned about.
Typical guidelines:
- complexity ≤ 5 → simple
- complexity ≤ 10 → manageable
- complexity > 10 → refactor
High cyclomatic complexity does not mean code is wrong.
It means the code is becoming difficult to reason about and difficult to test. Limiting complexity forces functions to remain small and predictable.
CRAP Score
CRAP stands for Change Risk Anti-Patterns.
It combines two signals:
- cyclomatic complexity
- test coverage
The idea is simple. Complex code increases risk. Untested code increases risk. Complex and untested code multiplies risk. CRAP quantifies that relationship.
Typical interpretation:
- CRAP < 10 → low risk
- CRAP 10-30 → moderate risk
- CRAP > 30 → high risk
In the workflow described earlier the target was CRAP below 8.
That forces two things at the same time:
- code must remain simple
- tests must remain thorough
Together these dramatically reduce the probability of introducing defects.
Why This Matters for AI
AI-generated code has a predictable weakness. It often looks correct while being semantically fragile.
The code compiles. The tests run. But small behavioral changes break the system.
Mutation testing directly attacks that weakness. Cyclomatic complexity prevents large opaque functions from emerging. CRAP ensures complex areas remain heavily tested. Together these metrics create guardrails that stabilize generated code.
This fits naturally into an AgenticOps pipeline.
The AgenticOps Verification Loop
A practical AgenticOps workflow might look like this.
Specification
↓
Agent generates acceptance tests
↓
Agent generates unit tests
↓
Agent generates implementation
↓
Run tests and fix failures
↓
Measure coverage and improve it
↓
Reduce complexity and CRAP
↓
Mutation testing attacks the code
↓
Agent fixes surviving mutants
↓
Repeat until all quality gates pass
The system continuously attempts to invalidate its own behavior. Only code that survives adversarial verification moves forward.
Architecture Through Measurement
Another interesting rule in the workflow was limiting files to a maximum number of mutation sites. Mutation sites correlate with complexity.
As files accumulate mutation points, they become harder to reason about. Instead of manually policing architecture, the system enforces limits:
- maximum mutation sites per file
- maximum cyclomatic complexity
- maximum CRAP score
When limits are exceeded, refactoring becomes mandatory. Architecture emerges from constraints.
Acceptance Tests First
Another subtle pattern is the order of operations. The systems were not executed during development. Behavior was defined through acceptance tests before the implementation existed. Only after the verification pipeline passed was the system executed.
Execution was confirmation. Not discovery.
Deterministic Pipelines
AI-assisted development introduces a fundamental challenge: trust. Developers often ask whether generated code “looks correct”. That is not the right question. The right question is whether the code passes the verification pipeline.
Pipelines provide deterministic evaluation of stochastic output. They transform judgment into measurement.
Parallel Verification
In the original story, everything ran on a single machine. Tests, mutation engines, coverage analysis, and refactoring cycles competed for CPU time.
Modern systems can push this further. Verification can run in parallel:
- test workers
- mutation workers
- coverage analysis
- linting
- architecture checks
Parallel verification shortens feedback loops while preserving rigor.
Engineering Confidence
The most important takeaway is not productivity. It is confidence.
By the time the systems were executed, they had already survived:
- acceptance tests
- unit tests
- mutation testing
- coverage gates
- structural constraints
Execution became almost a formality.
This kind of discipline has been advocated for years by engineers like Robert C. Martin, but the lesson is broader than any individual methodology. Verification beats debugging.
Convergent Patterns
This pattern appears across many engineering environments. Different teams use different tools, but the structure is consistent:
- tight feedback loops
- automated verification
- promotion gates
The tools evolve. The principles remain.
AgenticOps applies these same ideas to AI-assisted development. The goal is not to trust the agent. The goal is to build systems where trust is unnecessary.
Let’s talk about it.
Previous: [OpenClaw Is Not an AI Assistant]
Next: [Deploying an Agent Runtime with an Agent]
OpenClaw Is Not an AI Assistant
OpenClaw is getting a lot of attention right now. It’s usually described as an AI assistant. That description misses what it actually is. OpenClaw is an agent runtime.
It connects a language model to tools that interact with real systems. Those tools can read files, write code, run shell commands, and call APIs.
So the right mental model is not: “install an AI assistant.” The right mental model is: “deploy an autonomous process with the ability to operate on my machine.”
Once you see it that way, the real question isn’t how to install it. The real question is how to contain it.
What OpenClaw Actually Does
OpenClaw allows a language model to operate as an agent. Instead of just generating text, the model can decide to invoke tools that interact with the outside world.
Those tools can:
- read and write files
- execute code
- run shell commands
- call APIs
- interact with external services
These capabilities are organized as skills. A skill is a package that describes a capability and exposes tools the agent can use.
Example structure:
skills/ github/ SKILL.md tools/ create_pr.js list_issues.js
The SKILL.md file explains to the model when and how to use those tools.
You can think of a skill as a capability module that expands what the agent is allowed to do.
Installing OpenClaw
OpenClaw installs through Node and runs as a CLI with a gateway daemon.
Requirements
- Node 22 or later
- macOS, Linux, or Windows (WSL recommended)
Check Node:
node -v
If needed:
nvm install 24
Install OpenClaw:
npm install -g openclaw
Run onboarding:
openclaw onboard --install-daemon
This installs the gateway service that manages agent sessions.
Configure Models
OpenClaw connects to external models through configuration.
Example file:
~/.openclaw/models.yaml
Example configuration:
models: primary: provider: anthropic model: claude-3-opus api_key: ${ANTHROPIC_KEY} fallback: provider: openai model: gpt-5 api_key: ${OPENAI_KEY}
Start the runtime:
openclaw start
At this point you have an operational agent runtime.
Installation Is Easy. Containment Is the Real Problem.
An OpenClaw agent can run shell commands, modify files, and call external services. That means the system should be treated as untrusted automation.
Most tutorials approach this with policy: “Don’t let the agent do dangerous things.” That approach is backwards. You don’t want policies. You want infrastructure that prevents the agent from doing dangerous things. Containment needs to be enforced by the environment.
Three Different Isolation Layers
There are three different isolation mechanisms involved when running OpenClaw. They solve different problems.
Runtime Containerization
The simplest layer is running OpenClaw itself inside Docker.
Example:
docker run -it \ --name openclaw \ -v claw-workspace:/workspace \ openclaw/openclaw
In this setup the OpenClaw gateway runs inside a container. This gives you:
- a reproducible environment
- basic host isolation
- simpler deployment
But this alone does not sandbox the agent’s actions. This protects the host, not the runtime.
OpenClaw Tool Sandboxing
OpenClaw can sandbox tool execution. Instead of executing commands directly, the runtime launches a container for tool execution.
Architecture:
↓
OpenClaw Gateway
↓
Agent Session → container
↓
Tool ExecutionTools that can be sandboxed include:
- shell commands
- file edits
- code execution
- browser automation
Configuration example:
agents.defaults.sandbox.mode: "all"agents.defaults.sandbox.scope: "session"
Each session receives its own sandbox container.
This isolates agent actions, but the gateway process still runs outside the sandbox.
Docker Sandboxes
Docker recently introduced Docker Sandboxes specifically for AI workloads. A Docker Sandbox runs the agent inside a micro-VM style environment with strict boundaries.
Architecture:
Host ↓Docker Sandbox ↓OpenClaw Runtime ↓Agent Tools
This environment provides stronger isolation:
- restricted filesystem access
- network proxy and allowlists
- external secret injection
- workspace-only file access
Secrets are injected from outside the sandbox rather than being stored in the runtime. Network access can be restricted to specific domains such as model providers or internal APIs. This shifts containment from policy to infrastructure. Instead of telling the agent not to do something, the environment simply prevents it.
The Containment Model That Makes Sense
The safest approach combines these layers.
Docker Sandbox ↓OpenClaw Runtime ↓OpenClaw Tool Sandbox ↓Agent Tools
This creates multiple containment rings.
Ring 1 — Docker Sandbox
Ring 2 — OpenClaw tool sandbox
Ring 3 — tool allowlists
Ring 4 — network restrictions
Ring 5 — human approval gates
Each ring assumes the ring inside it may fail. That’s how you design systems around stochastic components.
Where OpenClaw Actually Becomes Useful
Once it’s contained, OpenClaw becomes a programmable operator. The value comes from defining skills that match the workflows you already run.
Engineering Agent
Skills:
- git
- test runner
- code review
- CI
Tasks:
- review pull requests
- generate architecture summaries
- run test suites
- produce coverage reports
Example:
review this PR and summarize the architectural impact
Research Agent
Skills:
- web search
- summarization
- synthesis
- writing
Typical workflow:
- gather sources
- summarize them
- extract insights
- draft documents
Operations Agent
Skills:
- calendar
- meeting summarization
- task management
Tasks:
- triage inbox
- extract action items
- schedule meetings
- produce summaries
Product Strategy Agent
Skills:
- market research
- competitor analysis
- financial modeling
- feedback synthesis
Outputs:
- product briefs
- experiment plans
- roadmap drafts
Structuring an Agent Runtime
For larger systems, it helps to treat the runtime as infrastructure hosting multiple agents.
Example:
Runtime research agent engineering agent planning agent writing agent
Each agent has:
- its own prompt
- its own skills
- the same runtime environment
The runtime provides infrastructure. The agents provide behavior.
A Note on Maturity
OpenClaw is still early. The capabilities are powerful, but the ecosystem is not hardened yet.
Security researchers are already demonstrating how prompt injection and malicious skills can manipulate agents with broad access. That doesn’t mean the system shouldn’t be used. It means the system should be designed with containment in mind from the start.
The Opportunity
The real opportunity isn’t running a single agent. The interesting direction is combining agent runtimes with orchestration and evaluation systems.
Example architecture:
Agent Runtime ↓Workflow Engine ↓Tool Execution ↓Evaluation Loop
That changes the role of the agent. Instead of being an assistant, it becomes a component inside a controlled operational system. At that point you’re no longer experimenting with AI tools. You’re building infrastructure around them.
Let’s talk about it.
Previous: [Autonomy Without Infrastructure Is Just a Demo]
Next: [Verification Beats Debugging]
Autonomy Without Infrastructure Is Just a Demo
The AgenticOps series defines six layers, four containment rings, and a maturity model. All of it was framework vision. The AgenticOps Applied series are stories about how the vison is realized through experiments and production case studies. This post is a case study that tests the framework against a production system that was built without the it.
What Stripe Published
Stripe released two blog posts in early 2026 describing their internal coding agents, called Minions (Part 1 and Part 2). The numbers are striking. Over 1,300 merged pull requests per week. Every PR is human-reviewed. None contains human-written code.
Stripe didn’t build Minions from a governance framework. They built them from engineering first principles to solve a production problem. Autonomous coding agents at scale inside a system that processes payments.
The architecture they arrived at is worth examining. Not because it validates AgenticOps by name, but because independent convergence on the same structural patterns is stronger evidence than any single implementation built from the framework itself.
What They Built
Five components define the Minions architecture.
Devboxes. Every agent run executes in a disposable AWS EC2 instance. These environments arrive pre-warmed with the full codebase, built dependencies, and running services in about ten seconds. No internet access. No production connectivity. Destroyed after each run. Stripe already used devboxes for human engineers. The same infrastructure worked for agents.
Blueprints. Minion runs are not pure agent loops. They are hybrid state machines that interleave deterministic nodes with stochastic agent nodes. Deterministic steps handle linting, pushing branches, and triggering CI. Agent steps handle implementation and failure resolution. The agent gets freedom where reasoning helps. The system enforces what must always happen.
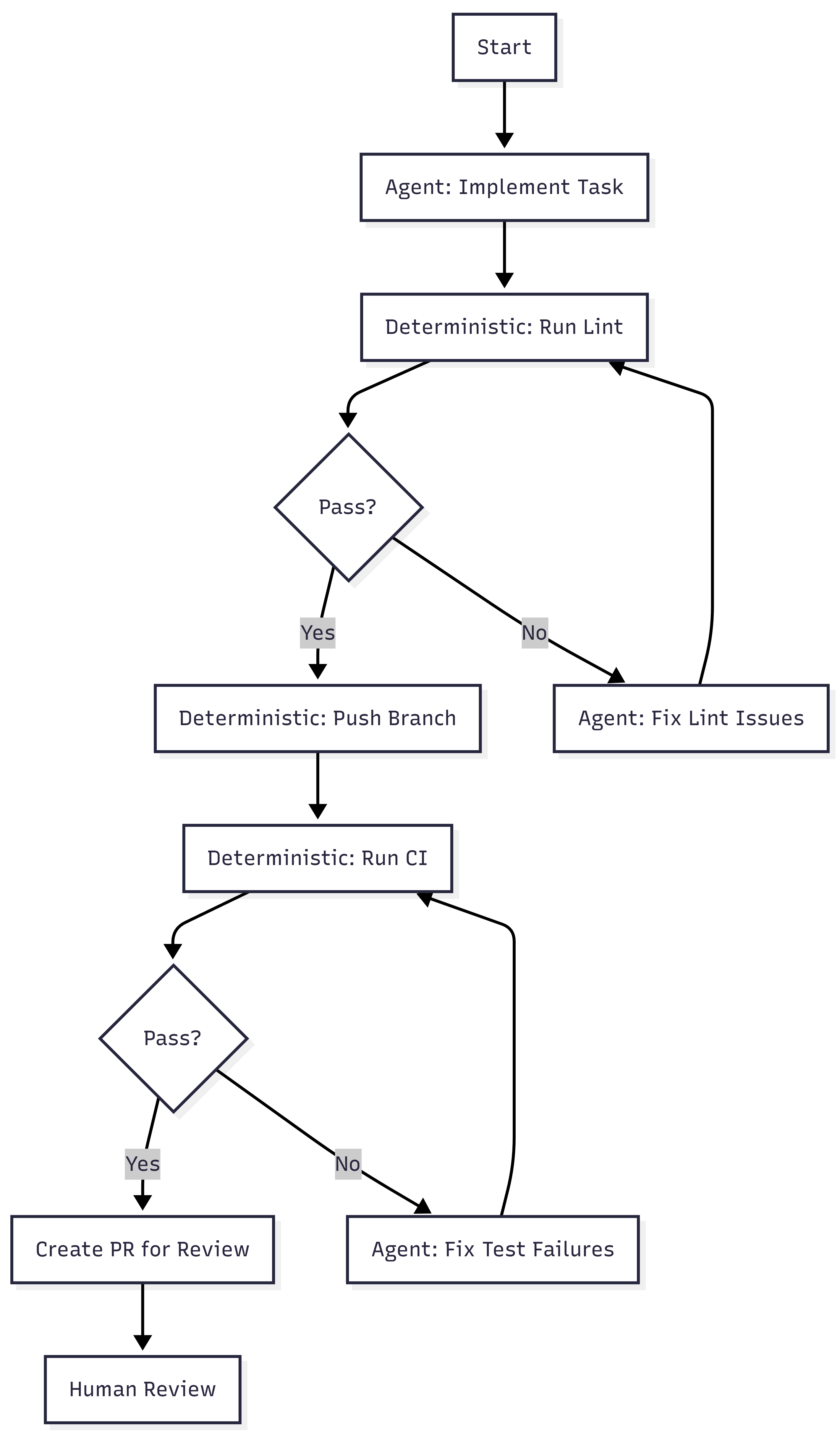
Toolshed. An internal MCP server with nearly 500 tools for internal systems and SaaS platforms. Agents receive curated subsets, not the full set. Security controls prevent destructive actions. Before a run begins, the system fetches context from tickets and documentation so agents start informed rather than searching blind.
Rule files. Static guidance scoped to directories. As the agent traverses the codebase, relevant rules load automatically. Stripe standardized on Cursor’s format and syncs rules to support Claude Code as well. Global rules fill the context window. Scoped rules provide signal where the agent is actually working.
Verification pipeline. Local lint runs in under five seconds after generation. Only after that passes does the system target CI against a suite of over three million tests (WTF). If CI fails, the agent gets one retry. Not infinite retries. One. Then the PR goes to a human. Stripe caps iterations because compute, tokens, and time cost money.
Alignment to the Containment Rings
Post 4 of the main series introduced four rings. Here is where Stripe’s architecture maps.
| Ring | What It Requires | What Stripe Built |
| 1: Constrain Inputs | Curated tool access, scoped context | Toolshed (curated MCP subsets), directory-scoped rule files, pre-hydrated context |
| 2: Constrain Environment | Isolated, disposable execution | Devboxes (pre-warmed EC2, no internet, destroyed after use) |
| 3: Validate Outputs | Layered verification | Local lint (seconds) + selective CI (minutes) + capped retry (one attempt) |
| 4: Gate Promotion | Human review as structural gate | Every PR goes to a human reviewer, agents never self-merge |
All four rings are present.
Ring 2 is the strongest. Devboxes provide binary isolation. The agent either cannot reach production, or the ring does not exist. There is no partial isolation. Stripe chose infrastructure over policy.
Ring 1 is more sophisticated than most implementations. Toolshed is not just tool access. It is curated, scoped, and security-controlled tool access. The distinction matters. Giving an agent 500 tools is not Ring 1. Giving it the 12 tools relevant to its task is.
Ring 3 includes a design decision that reveals operational maturity. Capping retries at one is an economic constraint, not a technical one. Infinite retries would burn tokens and compute chasing diminishing returns. The cap forces failed tasks back to humans rather than letting agents loop.
Ring 4 is non-negotiable at Stripe. Agent-generated code never merges itself. This is the same principle from the main series: governance sits outside the agent loop, not inside it.
Alignment to the Six Layers
The six layers tell a different story. Stripe covers some well and skips others entirely.
| Layer | Stripe Coverage | Evidence |
| Intent | Partial | Tasks arrive from Slack, CLI, web UIs. No formal contract space, invariants, or state machines. |
| Agent Generation | Strong | Blueprints, devboxes, Toolshed. Agents generate inside explicit boundaries. |
| Evaluation | Strong | Lint + CI + capped iteration. Layered and cost-aware. |
| Promotion | Strong | Human PR review. No self-promotion. |
| Runtime Governance | Not described | Blog posts focus on agent infrastructure, not post-deployment observability of generated code. |
| Knowledge Compression | Not described | Minions produce PRs. No mention of compressed artifacts, invariant updates, or system documentation as output. |
The bottom four layers (Generation through Promotion) are well-built. The top and bottom layers (Intent and Knowledge Compression) are absent or informal.
This is not a criticism. Stripe solved the problem they had. But the gap is structurally interesting. Maybe intent isn’t mentioned because tasks are small and well-scoped. Maybe knowledge compression is absent because Stripe’s existing engineering culture handles documentation through other channels.
The AgenticOps model predicts that these layers become necessary at higher maturity levels. Stripe may not need them yet. Or they may have them and the blog posts simply didn’t cover them.
Maturity Assessment
Post 3 of the main series defined six maturity levels. Here is where Stripe sits.
Level 0, manual coding. Humans write and review everything. Stripe is past this.
Level 1, AI-assisted coding. AI generates, humans review line by line. Stripe is past this. Minions are not copilots. They are autonomous agents that produce complete pull requests.
Level 2, contract-first generation. Humans define contracts. AI implements against them. Tests gate promotion. Stripe partially meets this. Tests gate promotion, and rule files define constraints. But there is no formal contract space in the AgenticOps sense. No versioned invariants, no state machine definitions, no explicit risk tolerance declarations. The contracts are implicit in the test suite and rule files rather than formalized as a separate layer.
Level 3, governed agent loops. Slice queues, evaluation services, approval gates, containment enforced structurally. This is where Stripe lives. Blueprints are governed loops. Devboxes are structural containment. Human review is an approval gate. The governance is built into the system, not a process someone follows.
Level 4, observational governance. Runtime telemetry feeds back into planning and constraint refinement. Stripe tracks metrics on Minion performance, success rates, and merge rates. They iterate on blueprints and rules based on results. But the blog posts do not describe an automated feedback loop from runtime telemetry to constraint refinement. There are indicators of L4 thinking without the closed loop.
Level 5, adaptive governance. The system proposes constraint improvements within defined boundaries. Not described.
Stripe is solid Level 3 with early Level 4 signals. I bet that places them ahead of most organizations. Post 3 noted that most teams are between Level 1 and Level 2. Stripe jumped past the painful middle by investing in infrastructure rather than trying to scale human review.

What’s Not There
Three things the AgenticOps model calls for that Stripe’s published architecture does not describe.
Formalized intent. Tasks arrive as natural language requests through Slack or internal tools. There is no versioned contract space, no invariant classification, no explicit risk tolerance. In the next post I argued that intent rots without versioning. Stripe’s tasks are small enough that intent rot may not be a factor. At 1,300 PRs per week, the blast radius of any single task is small by design.
Knowledge compression. Minions produce code changes. The blog posts do not describe any system for producing compressed artifacts, updated documentation, invariant lists, or system summaries as a byproduct of agent work. In a future post I will also argued that compression without tiers is spam. Stripe may have solved this through other channels, or they may not need it at the task granularity Minions operate at.
The feedback loop. 1 argued that the six-layer diagram should be a cycle, not a waterfall. Knowledge compression feeds back into intent refinement. Stripe’s system appears linear: task in, PR out. The blog posts do not describe runtime signals feeding back into blueprint design or rule file updates, though Stripe almost certainly does this manually through engineering iteration.
None of these are failures. They are observations about where the model extends beyond what Stripe published. The interesting question is whether these gaps constrain Stripe’s ability to reach Level 4 and Level 5, or whether their task granularity makes the gaps irrelevant. Maybe they are past 4 and 5 and found gear 6.
What Convergence Means
Stripe did not read the AgenticOps posts. They did not reference containment rings. They solved an engineering problem and arrived at a structurally similar architecture.
The mapping nomenclature is mine, not theirs.
When independent teams approach the same class of problem from different starting points and still land on the same structural solutions, it usually means the problem space itself is constraining the design. The architecture isn’t ideology. It’s physics.
In this case the physics is stochastic software generation.
This is the first post in this series and it shows the Framework Applied rather than Framework Vision. The underlying principles are real, published, and operating at scale. The alignment to the containment model is analytical, not claimed by Stripe.
The containment rings hold. The maturity model places Stripe where the evidence suggests. The layers that Stripe skips are the ones the model predicts become necessary later.
Will it hold? Is it wrong?
Let’s talk about it.
Next: [Intent Drifts. Then Everything Drifts.]
