You Stopped Verifying.
Post 4 of the AgenticOps series introduced the containment rings that keep agents in bounds. This post stress-tests the verification layer that makes containment real.
Forty-two percent of committed code is now AI-generated. Ninety-six percent of developers say they don’t fully trust it. Only forty-eight percent always verify before committing.
Those numbers are from a single survey of over 1,100 developers, published by Sonar in early 2026. Real people. Real codebases. Real behavior.
The gap between what people say they trust and what they actually verify is where the problem lives. Feel me?
The Problem
Generation and verification don’t scale the same way. That’s the whole issue.
AI generation scales with compute. You add more calls, you get more code. Human verification scales with hours in the day. You can’t add more hours without adding more people.
Sonar projects AI-generated code will hit 65% of all commits by 2027. That’s not a capability prediction. It’s an adoption curve. Seventy-two percent of developers who tried these tools already use them daily. The volume is accelerating.
Here’s the math that doesn’t work.
| Year | AI-Generated Code | Verification Rate | Effective Coverage |
|---|---|---|---|
| 2025 | 42% of commits | 48% always verify | ~20% of AI code verified |
| 2027 (projected) | 65% of commits | Flat or declining | ~15% of AI code verified |
Effective coverage is already below 20%. It’s heading lower. Every month the gap widens, the cost to close it grows.
Werner Vogels, AWS CTO, put a name on this at re:Invent 2025. He called it verification debt. The term is precise. Debt compounds. Technical debt is work deferred. Verification debt is trust assumed. Both grow silently.
Why It Breaks
The failure happens in three stages. Most teams are already past stage one.
Stage one: generation outpaces review. The PR queue grows. Reviewers approve faster to keep up. Average review time drops. It feels like efficiency. It is the verification rate declining.
Stage two: trust substitutes for verification. Developers build intuitions about which AI output is “usually right.” They stop reading generated code that looks familiar. They trust the model on boilerplate and test scaffolding. This works until it doesn’t.
Thirty-eight percent of developers say reviewing AI-generated code takes longer than reviewing human-written code. AI code looks plausible. It compiles. It passes basic tests. Catching the defects requires knowing what the code should do, not just what it does.
Stage three: debt compounds. Unverified code becomes load-bearing. Tests get written against its behavior, locking in whatever it does, correct or not. Six months later, a bug surfaces. The trace goes back to a function that was AI-generated, never reviewed, and now has forty callers.
That’s not a debugging problem. That’s a structural failure.
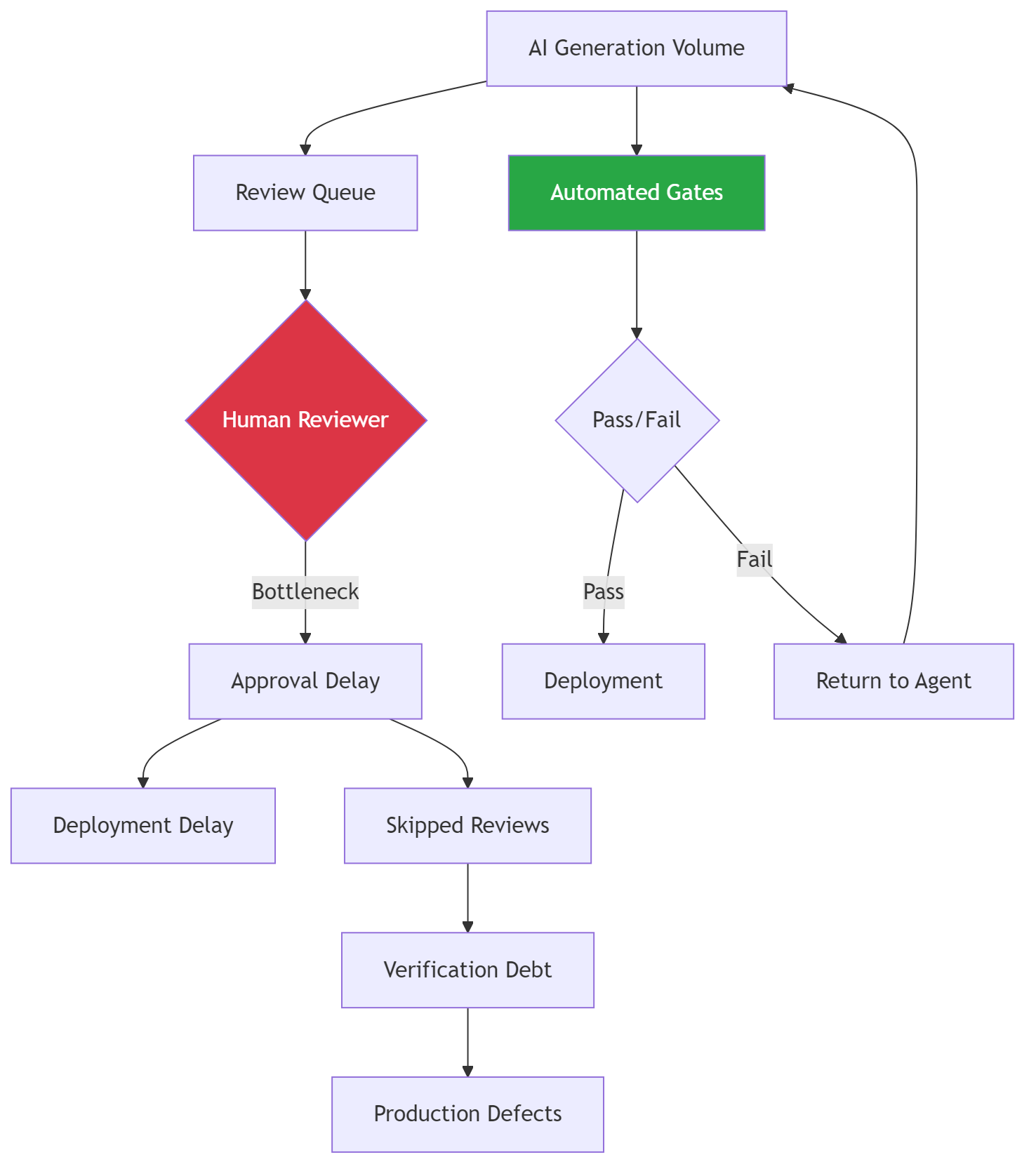
The left path is where most teams are right now. The right path is what the evaluation layer provides. No amount of developer discipline fixes a rate mismatch between generation and verification. Only automation fixes a rate mismatch.
The Fix
The fix is not “verify more.” That’s telling a drowning person to swim harder. The fix is moving verification from human effort to automated infrastructure.
Layer 3 of the AgenticOps model is the evaluation layer. It has to scale at the same rate as generation. If it doesn’t, the governance model collapses under volume.
Let me give you a specific example of what the throughput difference looks like.
| Approach | Throughput | Catches | Scales With |
|---|---|---|---|
| Human code review | ~50 LOC/hour deep | Logic errors, design flaws, intent mismatches | Headcount (linear, expensive) |
| Static analysis | Thousands of files/minute | Style violations, antipatterns, type errors | Compute (near-free at scale) |
| Mutation testing | Hundreds of functions/hour | Weak tests, untested branches, semantic gaps | Compute (parallelizable) |
| Property-based testing | Thousands of cases/minute | Edge cases, invariant violations | Compute (embarrassingly parallel) |
Human review is the only approach that cannot scale with generation volume. It is also the only one most teams rely on exclusively.
The gate sequence: each gate runs automatically, each gate has a pass/fail threshold, and code that fails returns to the agent for correction, not to a human for debugging.
Gate Thresholds
| Gate | Metric | Threshold | Action on Failure |
|---|---|---|---|
| Coverage | Line and branch coverage | >= 90% | Agent generates additional tests |
| Complexity | Cyclomatic complexity per function | <= 10 | Agent refactors or splits function |
| CRAP | Change Risk Anti-Patterns score | <= 8 | Agent reduces complexity or adds coverage |
| Mutation | Mutation score (killed / total) | >= 85% | Agent strengthens test assertions |
| Property | Property test pass rate | 100% | Agent fixes implementation |
These are machine-enforced deterministic gates. Not suggestions. Not targets. They block promotion.
When the agent generates code, the pipeline runs. When the pipeline fails, the agent fixes. When the pipeline passes, the code promotes. Humans review the gate configuration, not the code itself.
The review surface shrinks from every line of generated code to the gate definitions. That’s the inversion that makes it scale.
Three things humans still own.
First, gate configuration. What are the thresholds? Are they appropriate for this codebase? Do they need to tighten as the system matures? This is a quarterly review, not a per-commit review.
Second, intent specification. Automated gates verify structural properties. They don’t verify intent. Acceptance tests, written by humans or by agents under human review, bridge that gap.
Third, promotion decisions. Automated gates recommend promotion. Humans approve it. The human is still the final decider, but deciding from evidence instead of from reading code.
Stories from Production
The Sonar Survey Reality Check (Framework Applied)
Sonar’s 2026 survey of over 1,100 developers is the first large-scale dataset quantifying the verification gap in AI-assisted development. These are self-reported numbers from working developers. Not a lab study.
The most telling data point: 38% say reviewing AI code takes longer than reviewing human code. That contradicts the assumption that AI output is easier to review because it follows consistent patterns.
In practice, AI-generated code is harder to review because it looks right. The defects are subtle. Catching them requires knowing what the code should do, not just what it does. That knowledge is exactly what gets lost when generation is fast and context is thin.
The 72% daily usage rate confirms the generation side. Developers who try these tools stay with them. The volume is not going to decrease. Any governance strategy that assumes generation volume stabilizes will fail.
The Math That Breaks (Framework Vision)
Team of eight. Historically, each developer reviews four PRs per day at thirty minutes each. That’s 16 hours of review capacity per day.
AI generation doubles PR volume. The team faces 64 PRs per day instead of 32. Review time increases 38% per PR, matching the Sonar data. The team now needs 44.8 hours of review capacity. They have 16.
Something gives. Either review quality drops, coverage drops, or cycle time extends until the backlog collapses. All three produce verification debt.
Now run the same scenario with automated gates. The pipeline handles 90% of PRs automatically, pass or return-to-agent. Human reviewers see 6.4 PRs per day instead of 64. Each arrives with a verification report. Review time drops because reviewers are evaluating evidence, not reading code.
This scenario hasn’t been validated at full production scale. The individual components are proven. The composition into a unified pipeline that replaces human review as the primary verification mechanism is the open question. But the Sonar data is clear: the current approach is already failing at 42% AI generation. It won’t survive 65%.
Verification Debt Gets Its Name (Framework Applied)
When Vogels named verification debt at re:Invent 2025, the term stuck because it maps to something every engineer already understands. Technical debt is work deferred. Verification debt is trust assumed. Both compound. Both are invisible until they aren’t.
By naming it as a distinct category, Vogels separated verification debt from code quality, test coverage, and security scanning.
A codebase can have 90% test coverage and still carry massive verification debt. If the tests were generated by the same AI that wrote the code, and nobody confirmed the tests validate the right behavior, the coverage number is noise.
Mutation testing is the direct remedy for this specific form of debt. A test suite that kills 85% of mutants has been verified against behavioral changes, not just structural coverage. That’s the difference between “the tests run” and “the tests catch defects.”
—
The trend line is what matters. Generation is accelerating. Verification is not. The intersection already passed.
The teams that build verification infrastructure now will carry manageable debt. The teams that wait will find out what compound interest looks like in a codebase.
Don’t be scared of the infrastructure cost. Be scared of what happens without it.
Let’s talk about it.
