Tagged: LLM
Agent Sprawl Is the New Shadow IT.
A friend sent me a post about AI sprawl across enterprise tooling. The argument was that organizations are paying for the same value many times over. Across an organization some people summarize emails in Outlook, sales team summarizes same email in the CRM, PMO summarizes the email in the project management tool. Three subscriptions, three vendors, three different models delivering the same value for the same organization on the same input. The potential for waste is real.
I want to be straight with you. I think the sprawl is a maturity problem, not a design problem. Everyone is trying to find leverage with AI right now. Teams are experimenting. Departments are buying tools that solve immediate pain. Nobody coordinated because nobody knew what would work six months ago. That is not negligence. That is what early adoption looks like in every technology wave. As things settle and consolidate, the duplicate subscriptions will compress. The market is already moving that way.
But here is the part that will not consolidate on its own. Even after the vendor landscape settles, even after the organization standardizes on fewer tools, the duplicate capability problem persists at the agent level. Three different workflows that each classify a work item using three different prompts with three different confidence thresholds. Five agents that each summarize context in slightly different ways because five operators made five independent decisions about what “summarize” means. The tools consolidate. The capabilities inside them do not, because nobody governed the boundary where one agent’s output becomes another agent’s input.
Gartner predicts 40% of enterprise applications will feature task-specific AI agents by the end of 2026. For the average organization, that translates to 50 or more specialized agents. Customer service agents. Code generation agents. Data pipeline agents. Document processing agents. Scheduling agents. Each one deployed by a different team, with different tooling, different containment posture, and different governance assumptions. They Can Watch. They Cannot Stop. showed what happens when organizations skip the containment rings for a single class of agent. Now multiply the problem.
69% of organizations suspect their employees already use prohibited AI tools. The agents are not waiting for an enterprise rollout. They are arriving through the same channel that every previous wave of unauthorized technology used: individual teams solving immediate problems without waiting for centralized approval.
History Repeats
The enterprise technology industry has seen this before. In 2018, Robotic Process Automation promised to automate repetitive tasks without changing underlying systems. Adoption was fast. Individual departments built bots to handle invoice processing, data entry, report generation. The bots worked. The ROI was immediate and visible. Within two years, large organizations had hundreds of RPA bots running across dozens of departments with no central inventory, no shared governance, and no unified monitoring.
Unframe AI drew the comparison directly: decentralized adoption, quick wins, proliferation, fragmentation, expensive consolidation. The RPA consolidation crisis cost organizations millions and took years. Bots broke when underlying systems changed. Nobody knew which bots existed, what they accessed, or who was responsible for maintaining them. The technical debt was invisible until it was not, and by then the cleanup was more expensive than the original implementation.
Agent sprawl follows the same trajectory but compresses the timeline. RPA bots were deterministic. They did exactly what they were scripted to do, which made them fragile but predictable. AI agents are stochastic. They interpret instructions, make decisions, and adapt to context. A misbehaving RPA bot runs the wrong script. A misbehaving AI agent improvises. The blast radius per agent is larger, the number of agents is growing faster, and the governance infrastructure is thinner.
Organizational Cognitive Debt
Your Code Works. Nobody Knows Why. described cognitive debt as the gap between a system’s structure and a team’s understanding of that structure. Agent sprawl creates cognitive debt at the organizational level. When fifty agents operate across an enterprise, the question is not whether any individual agent is governed. The question is whether anyone can describe the complete system of agents, their interactions, their data flows, and their combined effect on the business.
Most organizations cannot. The agents were deployed independently. The customer service team chose one vendor. The engineering team built their own. The finance team embedded agents into existing SaaS tools. Each team can describe their own agents. Nobody can describe the whole. And nobody knows what happens when these agents interact. When the customer service agent updates a record, and the data pipeline agent processes that record, and the reporting agent summarizes the result, the combined behavior is an emergent property of three independent systems that were never designed to work together.
This is shadow IT at the capability level. Traditional shadow IT was about unauthorized applications. Agent sprawl is about unauthorized capabilities. An employee does not install a new application. They enable an AI feature inside an application the organization already approved. The application is sanctioned. The agent capability within it is not. The IT asset inventory shows zero unauthorized tools. The actual environment contains agents that nobody is tracking.
The Unit of Governance Is Not the Agent
CIO magazine identified three pillars for taming agent sprawl: orchestration, governance, and observability. These are correct as categories. The implementation question is where those pillars sit. If orchestration, governance, and observability are built per-agent, the organization has a governed collection of individual agents. If they are built per-boundary, the organization has a governed system.
The distinction matters because agent-level governance does not compose. Ten individually governed agents are not a governed system. They are ten systems that happen to share an organization. The interactions between agents, the data that flows from one to another, the cumulative effect of their combined actions on business processes, none of this is captured by governing each agent in isolation.
How Agents Stay in Bounds defined containment at the boundary, not the agent. Ring 1 scopes the inputs an agent receives. Ring 2 isolates the environment it runs in. Ring 3 validates its outputs. Ring 4 gates its promotion. These rings apply at every boundary in a multi-agent system, not just the boundary around each individual agent. The handoff from one agent to another is a boundary. The data flow between agent-enabled applications is a boundary. The integration point where an agent’s output becomes another agent’s input is a boundary.

Governing the boundaries means that even when a new agent appears in the ecosystem, its interactions with existing agents are already constrained. The new agent’s output passes through a boundary ring before it becomes input for another agent. The organization does not need to re-govern the entire system every time someone deploys a new agent. The boundaries hold.
The Inventory Problem
Before you can govern agents at the boundary, you need to know the boundaries exist. This is the discovery problem, and it is harder than it sounds. A 2026 Deloitte analysis of the multi-agent market estimated the agentic AI orchestration market will reach $35 billion by 2030. That money is not going to centralized platforms. It is being distributed across vendors, internal tools, and embedded capabilities in existing software.
The first step is an inventory. Not an inventory of agents, because agents are embedded in applications and invisible to traditional asset management. An inventory of capabilities. Which applications in the environment have AI agent features enabled? Which of those features can take autonomous action? Which can access data from other systems? Which can modify records, send communications, or trigger workflows?
This is the same audit structure from They Can Watch. They Cannot Stop., extended from individual agents to the organizational ecosystem. The four questions are the same. Can you define and enforce what each agent receives as input? Can you isolate each agent’s execution environment? Can you validate each agent’s output against measurable criteria? Can you prevent each agent from promoting its actions without approval? Apply those questions at the boundary between agents and you have a multi-agent governance audit.
- Enumerate every application in the environment with AI agent capabilities, including embedded copilots and SaaS features.
- For each, identify whether the agent can take autonomous action, access data beyond its primary function, or trigger downstream processes.
- Map the data flows between agent-enabled applications. Every flow is a boundary.
- Apply the four-ring audit to each boundary. Can you scope the input at the handoff? Can you isolate the execution? Can you validate the output? Can you gate the promotion?
- Score each boundary as governed, partial, or ungoverned. The ungoverned boundaries are your risk surface.
Organizations that run this audit typically discover more boundaries than they expected. The agent count may be manageable. The boundary count is where the governance gap hides.
RPA’s Lesson
Unframe AI’s comparison to RPA includes an observation that applies directly: “Agents aren’t the unit of value. Outcomes are.” The organizations that survived the RPA consolidation crisis were the ones that shifted from managing individual bots to managing business outcomes that bots contributed to. They built centralized orchestration, unified governance, and shared monitoring. They treated the collection of bots as a system rather than a portfolio of independent tools.
The agent version of this lesson is the same. The organization that governs fifty agents as fifty individual tools will face the same consolidation crisis RPA created. The organization that governs fifty agents as a system with defined boundaries, scoped handoffs, and unified observation will not. The difference is not the number of agents. It is whether the governance model scales with the agent count or collapses under it.
Agentic Engineering Is a Practice. AgenticOps Is the Infrastructure. made this argument for individual developers: practice degrades under pressure, infrastructure holds. The argument is identical at organizational scale. An organization that relies on each team to govern their own agents will see governance degrade as deployment velocity increases. An organization that builds governance into the boundaries between agents will see governance hold regardless of how many agents individual teams deploy.
The agents are already here. The sprawl has already started. The RPA playbook says the consolidation crisis arrives in 18 to 24 months. The question is whether organizations build the boundaries now or pay for the cleanup later.
Let’s talk about it.
They Can Watch. They Cannot Stop.
An agent misbehaves. The dashboard lights up. An operator sees exactly what is happening: the scope violation, the unauthorized data access, the lateral movement across systems. And then nothing. No kill switch. No isolation. No way to stop what they are watching unfold in real time. This is not a hypothetical. The Kiteworks Data Security Forecast surveyed 225 security, IT, and risk leaders across ten industries and eight regions, and the results say this is the default state of enterprise AI governance. Organizations built the screens. They did not build the brakes.
The four containment rings from the AgenticOps model predict exactly where the failure occurs and in what order to fix it. Observation is one ring. Organizations treated it as all four.
The Numbers
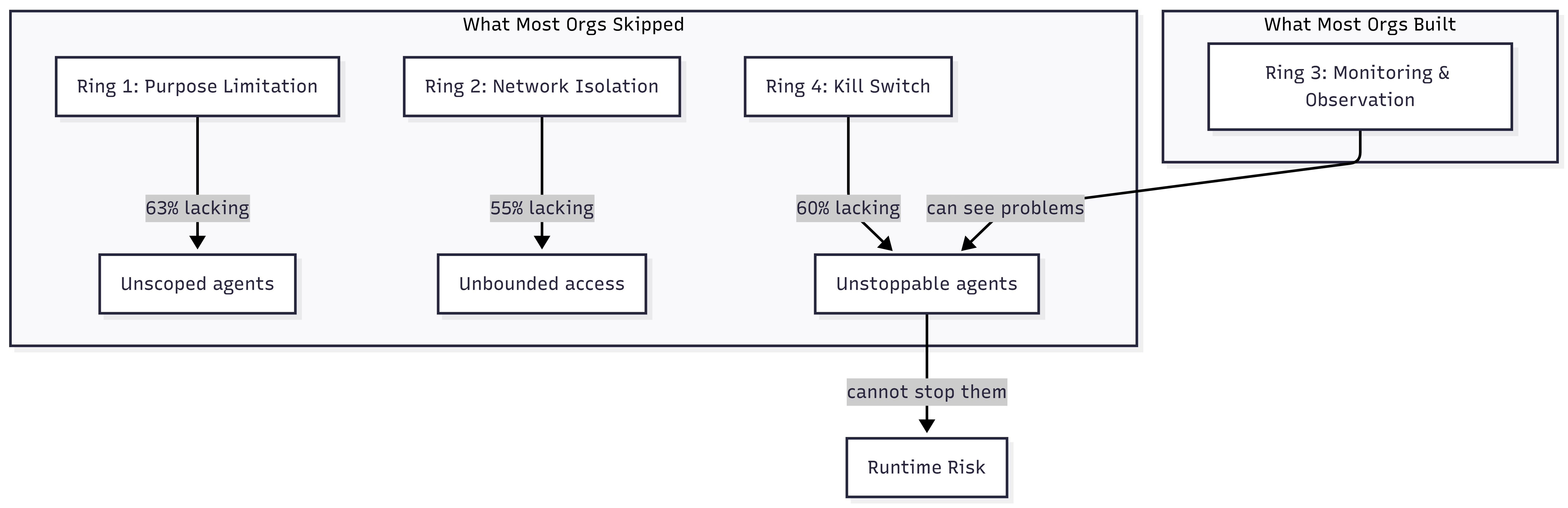
63% of organizations cannot enforce purpose limitations on their AI agents. They know what agents should do. They cannot technically prevent other actions. 60% cannot terminate a misbehaving agent. They can see the agent doing something unexpected. They cannot stop it. 55% cannot isolate AI systems from broader network access. The agent has access to systems beyond its intended scope, and the organization has no mechanism to restrict that access after deployment.
Meanwhile, 58% report continuous monitoring. 59% report human-in-the-loop oversight. 56% report data minimization practices. They can observe their agents, log what agents do, and flag anomalies.
The gap between observation and containment is 15 to 20 percentage points. The security community calls this the governance-containment gap. Most organizations can see an AI agent doing something unexpected and cannot prevent it from exceeding its authorized scope, shut it down, or isolate it from sensitive systems.
Mapping the Gap to the Four Rings
The four containment rings from How Agents Stay in Bounds provide a structural explanation for this gap. Each ring addresses a different containment boundary. The Kiteworks data reveals which rings organizations invested in and which they skipped.
Ring 1 is constrain inputs: scope what the agent receives before it starts. Purpose limitation is a Ring 1 control. It defines what the agent is allowed to do by limiting the context, tools, and data it can access. 63% of organizations cannot enforce this ring. They give agents broad access and rely on instructions to stay in scope. How Agents Stay in Bounds described this as the difference between policy and infrastructure. Policy says “only access these systems.” Infrastructure says “these are the only systems that exist in your environment.” Most organizations chose policy.
Ring 2 is constrain environment: physically isolate the agent’s execution. Network isolation is a Ring 2 control. It prevents the agent from reaching systems outside its intended scope regardless of what it attempts. 55% cannot enforce this ring. The agent runtime has network access to the broader environment, and the only barrier is the agent’s instructions not to use it. OpenClaw Is Not an AI Assistant demonstrated how Docker sandboxes, tool sandboxing, and network allowlists create physical containment around agent runtimes. The organizations in this survey do not have that infrastructure.
Ring 3 is validate outputs: evaluate what the agent produced before it takes effect. This is where the 58% monitoring figure lives. Organizations invested here. They can observe agent behavior, flag anomalies, and log actions for review. This ring is necessary but insufficient on its own. Observation without the ability to act on what you observe is surveillance, not governance.
Ring 4 is gate promotion: prevent unverified work from reaching production systems. Kill switches are a Ring 4 control. They prevent or reverse the promotion of agent actions that violate criteria. 60% of organizations cannot terminate a misbehaving agent. They can see the agent is misbehaving through their Ring 3 investment. They cannot stop it because they never built Ring 4.
| Ring | Control | Capability | Organizations Lacking |
| 1 | Constrain inputs | Purpose limitation | 63% |
| 2 | Constrain environment | Network isolation | 55% |
| 3 | Validate outputs | Continuous monitoring | 42% |
| 4 | Gate promotion | Kill switch / termination | 60% |
The pattern is clear. Organizations invested in Ring 3 and skipped Rings 1, 2, and 4. They built the middle of the defense and left the boundaries open. This is precisely what How Agents Stay in Bounds predicted: every ring you skip is a ring you inherit as runtime risk.
Why Organizations Built Observation First
The investment pattern is not irrational. Observation is easier to implement than containment. Monitoring can be added to existing agent deployments without redesigning the architecture. Log aggregation, anomaly detection, and human review queues are familiar patterns that security teams already understand from traditional application monitoring.
Containment requires architectural decisions made before deployment. Ring 1 requires scoping the agent’s context at design time. Ring 2 requires sandbox infrastructure that isolates the runtime. Ring 4 requires promotion gates that can halt or reverse agent actions. These are not things you bolt on after the agent is running. They are things you build into the deployment architecture from the start.
You Can Build This. Three Artifacts and a Sandbox. described the build order: constraint first, then agent definition, then gate, then sandbox. That order is deliberate. You define what the agent can do before you define the agent. You define what success looks like before you let the agent run. You build the sandbox before you execute inside it. The organizations in the Kiteworks survey did it the other way around. They deployed agents, then added monitoring, and now they are discovering that monitoring without containment leaves them watching problems they cannot fix.
Government Is in the Worst Position
The Kiteworks data includes a sector breakdown that makes the structural argument even more concrete. Government agencies are in the worst position across every containment metric. 90% lack purpose-binding controls. 76% lack kill switches. A third have no dedicated AI controls at all.
This is not because government agencies are less capable. It is because they face the most acute version of the structural problem. Procurement cycles are long. Architecture decisions are locked into multi-year contracts. The agents are deployed by vendors into environments the agency does not control. Ring 1 requires scoping the agent’s context, but the agency may not have visibility into what context the vendor’s agent receives. Ring 2 requires environmental isolation, but the agent may run in the vendor’s cloud, not the agency’s infrastructure.
The containment model assumed the organization controls the deployment environment. When that assumption breaks, when the agent runtime is managed by a third party, containment becomes a contractual problem, not just a technical one. The four rings still apply, but the implementation shifts from infrastructure configuration to vendor requirements and service-level agreements.
100% Have Agents on the Roadmap
The most striking number in the survey is not about failures. It is about ambition. 100% of organizations surveyed have agentic AI on their roadmap. Zero exceptions. Across 225 organizations, ten industries, eight regions, not a single organization plans to abstain from agent deployment.
This means the governance-containment gap is not a temporary condition that some organizations will avoid. It is the default starting position for every organization that deploys agents. The question is not whether an organization will face this gap. The question is whether they close it before something goes wrong.
What AgenticOps Actually Looks Like introduced three non-negotiables: no generation without defined contracts, no promotion without evaluation, no runtime without observability. The Kiteworks data suggests a fourth: no deployment without containment. Observability alone is not governance. It is the prerequisite for governance, not the thing itself.
Closing the Gap
The gap closes in a specific order. Ring 1 first: define what each agent is allowed to do, not in policy documents but in scoped contexts and tool allowlists. Ring 2 next: isolate the agent’s execution environment so that the boundary is physical, not instructional. Ring 4 last: build promotion gates that can halt or reverse agent actions when evaluation criteria fail. Ring 3, observation, is what most organizations already have. The gap is everything else.
This is the same build order from You Can Build This applied at enterprise scale. Write a constraint. Define the agent. Write a gate. Run it in a sandbox. The artifacts are different when the agent is a customer service bot instead of a code generator, but the pattern is identical. Scope the input. Isolate the environment. Verify the output. Gate the promotion.
The Agents of Chaos study also found that 75% of leaders will not let security concerns slow their AI deployment. This means the gap will not close by slowing down. It will close by building containment infrastructure that runs at deployment speed. How Agents Stay in Bounds made this argument for individual agents. The Kiteworks data makes it for entire organizations.
The model was built to describe this problem. Now the problem has data. The four rings are no longer a conceptual model. They are a diagnostic tool. Map your agent deployments against the four rings. Where you have gaps, you have risk. Where you have all four, you have governance.
The data says most organizations are watching. Watching is not governing. Governing requires the ability to stop what you are watching. That requires infrastructure, not observation.
Let’s talk about it.
Your Code Works. Nobody Knows Why.
There is a new kind of debt accumulating in AI-assisted codebases. It does not show up in failing builds or broken deployments. The tests pass. Features ship. The system runs. But the shared understanding of why the system works the way it does is fragmenting, silently, faster than anyone expected. Five independent researchers named the same problem within six weeks of each other. They are calling it cognitive debt, and it may be the most important concept in AI-assisted development right now.
A Name for the Problem
In February 2026, Margaret Storey published a post that gave the velocity-comprehension gap a precise definition. Cognitive debt is the accumulated gap between a system’s evolving structure and a team’s shared understanding of how and why that system works and can be changed over time. Unlike technical debt, which surfaces through failing builds and broken deployments, cognitive debt “tends not to announce itself through failing builds but rather shows up through a silent loss of shared theory.”
Simon Willison amplified the concept. Addy Osmani independently arrived at the same idea with “Comprehension Debt,” arguing that code has become cheaper to produce than to perceive. Five independent authors converged on the same concept within six weeks. When that happens, the concept is not a trend. It is a structural observation that multiple people noticed simultaneously because the underlying condition became impossible to ignore.
Storey grounded the concept in Peter Naur’s 1985 theory that a program is not its source code but a theory distributed across the minds of the people who built it. The source code is an artifact of that theory. When the theory fragments, when nobody on the team can explain why certain design decisions were made or how different parts of the system interact, the system becomes unmaintainable even when it functions correctly. AI accelerates this fragmentation because it generates structure faster than shared understanding can stabilize.
Why AI Makes It Exponentially Worse
Most Software Is Just CRUD. That’s Not the Problem. established an economic principle: anything that becomes cheap gets overproduced. AI made code generation cheap. The predictable result is overproduction of structure. More files, more functions, more abstractions, more system surface area, all generated faster than any team can internalize.
The traditional development cycle had a natural governor on cognitive debt. Writing code by hand forced the author to understand what they were building, at least at the moment of creation. The understanding might fade over time, but it existed at the origin. AI-assisted development removes that governor entirely. The agent generates a module. The developer reviews the output. The tests pass. The module ships. Six months later, nobody remembers why that module handles edge cases the way it does, because nobody decided it should handle them that way. The agent decided, and the decision was reasonable enough to pass review.
This is the scenario I described in I Was a 1x Coder at Best. AI Made Me a 0x Coder. when I said I write zero lines of code by hand. The 0x workflow works because I invested in containment infrastructure. But the honest version of that story includes the risk: every module the agent produces is a module whose design rationale exists only in the conversation context that created it. Once that context window closes, the rationale is gone unless something captures it.
Storey’s student teams demonstrated this concretely. By weeks seven and eight, students using AI assistance could not explain their own system’s architecture. The code worked. The tests passed. The team had lost the theory. They could not modify the system because they did not understand the design decisions that shaped it.
Technical Debt Has a Feedback Signal. Cognitive Debt Does Not.
Technical debt announces itself. Builds break. Deployments fail. Performance degrades. The system tells you something is wrong, and you fix it or you don’t. Either way, you know. Cognitive debt is silent. The system continues to function. Features continue to ship. The team continues to deliver. The problem only surfaces when someone needs to change something they do not understand, and by then the cost of understanding has compounded to the point where the change is more expensive than rewriting.
This asymmetry explains why cognitive debt is more dangerous than technical debt in AI-assisted environments. Technical debt accumulates linearly. You cut a corner, you pay interest, you can measure the interest and decide when to pay it down. Cognitive debt accumulates exponentially because each new module generated without shared understanding increases the surface area of the system that nobody fully grasps. The team’s capacity to understand does not grow. The system does.
Verification Beats Debugging described verification pipelines that make debugging unnecessary. Mutation testing, coverage gates, complexity limits. These are essential, and they address technical correctness. They do not address cognitive debt. A system can pass every verification gate while the team’s understanding of it decays. The gates prove the code works. They do not prove anyone knows why.
Knowledge Compression Is the Structural Response
What AgenticOps Actually Looks Like introduced six layers of the AgenticOps model. The sixth layer is Knowledge Compression. At the time, it may have seemed like an afterthought, a cleanup step after the important work of generation, evaluation, and promotion. Cognitive debt makes it clear that knowledge compression is not the last step. It is the step that determines whether the system remains governable over time.
Knowledge compression is the systematic reduction of system complexity into navigable artifacts. Not documentation in the traditional sense. Not the kind of documentation that gets written once and never updated. Compression artifacts are living summaries that capture the theory of the system in forms that humans can navigate quickly. One-page summaries. Lifecycle maps. Invariant lists. Decision logs that record not just what was decided but why, including the alternatives that were considered and rejected.
I’ve Never Fully Understood the Systems I Work In introduced these concepts: compression artifacts, lifecycle maps, invariant lists. At the time they were part of the argument that containment replaces comprehension. Cognitive debt makes the argument concrete. Without compression, the theory fragments. With compression, the theory is captured in artifacts that persist beyond the conversation context that created the code.
Compression Operates at Every Level
Compression is wider than decision logs. It operates at every level where theory can be lost, from individual commits to system architecture.
At the code level, compression means collapsing noisy history into navigable history. A feature implemented across thirty story-level commits contains the full record of false starts, revisions, and incremental progress. That granularity is useful during development and useless afterward. Compressing those thirty commits into a single feature-level commit with a clear description of what changed and why preserves the theory without preserving the noise. The detailed history still exists in the branch. The compressed version is what future developers encounter first.
At the decision level, compression means capturing the reasoning chain that led to each significant choice. A system I have been building tracks this through a document pipeline: a problem document captures the problem in the language of the requester, a research document explores the problem space, an options document maps the solution space, a decision document explains which option was chosen and why the alternatives were rejected, and a plan document breaks the chosen solution into deliverable work items. Each document compresses a phase of reasoning into a navigable artifact. Six months later, when someone asks “why does this system handle authentication this way,” the answer is not buried in a Slack thread or a closed pull request. It is in the decision document, linked to the options that were considered and the problem that started the whole chain.
At the architecture level, compression means maintaining living documents that describe the system as it actually runs, not as it was originally designed. Blueprints capture the current architecture. Guides capture how users and developers interact with it. When a work item changes a feature, the documents that describe that feature update as part of the same workflow. The architecture documentation and the code stay in sync because they are governed by the same process, not maintained by separate teams on separate schedules.
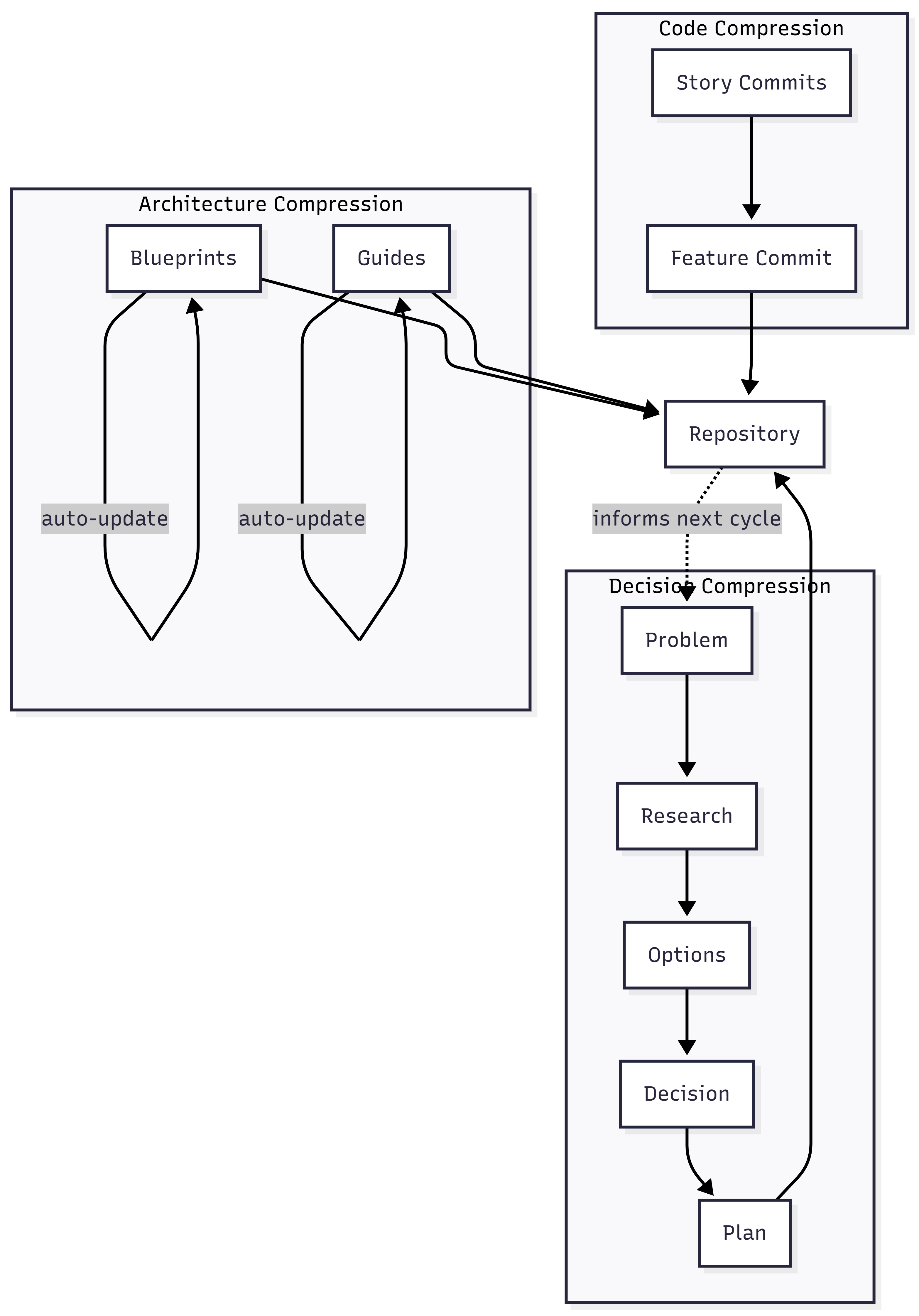
This is the feedback loop from What AgenticOps Actually Looks Like made concrete. Compressed knowledge feeds back into intent. The decision documents inform the next problem document. The blueprints inform the next options document. The guides inform the next plan. Without that loop, each development cycle starts from scratch. With it, each cycle builds on the accumulated theory.
Compression Is Not Documentation
Traditional documentation fails because it is a separate activity from development. It gets written after the fact, if at all, and it drifts out of sync with the code the moment someone changes something without updating the docs. The document pipeline described above succeeds because it is the development process, not a parallel activity. The problem document is written before development starts. The decision document is written before implementation begins. The blueprint updates when the feature ships. There is no separate “documentation phase” that can be skipped under deadline pressure.
This is the same pattern from You Can Build This: constraints define the space, agents work inside it, gates verify the output. Adding compression to the gate criteria means the system self-documents as it builds. No promotion without a decision document. No merge without a compressed commit history. No deployment without updated blueprints. These are not burdensome when agents generate them alongside the code. They are only burdensome when a human writes them by hand after the fact.
The result is that any team member, or any agent, can reconstruct the theory of the system by reading the compressed artifacts. They can trace from a production behavior back through the blueprint, to the decision that shaped it, to the options that were considered, to the problem that started the work. That traceability is the structural defense against cognitive debt. The theory is not in anyone’s head. It is in the repository, navigable and current.
The Velocity-Comprehension Contract
Cognitive debt reframes the relationship between velocity and understanding. The traditional framing was: move fast, accumulate debt, pay it down later. The cognitive debt framing is: move fast, lose the theory, discover later that you cannot pay it down because you no longer understand what you built.
The AgenticOps response is not to slow down. It is to make compression a structural requirement of the development process. Generate fast. Compress immediately. The velocity stays. The theory stays too. This is what I’ve Never Fully Understood the Systems I Work In meant by “I scale containment, not understanding.” The containment now includes containing the theory of the system before it dissipates.
The industry is beginning to recognize this. Storey’s follow-up post synthesized the community response and noted that teams are experimenting with checkpoints where they rebuild shared understanding through code reviews, retrospectives, and knowledge-sharing sessions. These are behavioral responses, necessary but insufficient. The structural response is to make the checkpoints automatic, to embed them in the gate criteria so they cannot be skipped when deadlines compress.
Cognitive debt is real. It is measurable. It is accelerating. And the sixth layer of the model, the one that might have looked like cleanup, is a primary defense against it.
Let’s talk about it.
Agentic Engineering Is a Practice. AgenticOps Is the Infrastructure.
In early 2026, multiple people working independently arrived at the same conclusion about how professional developers should work with AI coding agents. They converged on a term: agentic engineering. The practices they describe are correct. But practices live in behavior, and behavior degrades under pressure. Nothing in the agentic engineering model enforces the practice when the practitioner is tired, rushed, or outnumbered.
The Industry Converged
In early 2026, Andrej Karpathy proposed the term “agentic engineering” to describe what professional developers actually do when they work with AI coding agents. Addy Osmani wrote the definitive guide. IBM published a formal definition. Simon Willison drew the line that separates it from vibe coding: “I think the borderline is when you take responsibility for the code, and stop blaming the LLM for any mistakes.”
The core claims are familiar. Humans own architecture and quality. Agents handle implementation. Testing is the single biggest differentiator between disciplined and undisciplined AI-assisted work. Specifications before prompts produce better output than prompts alone. These are not new observations. I’ve Never Fully Understood the Systems I Work In described the same boundary between human judgment and agent execution. How Agents Stay in Bounds formalized it as four rings of containment. The language differs. The structure is the same.
What makes this convergence meaningful is not that smart people agree. It is that they agree independently, from different starting points, using different evidence. When multiple observers reach the same conclusion through different paths, the conclusion is likely structural rather than stylistic.
The Practice Is Necessary But Not Sufficient
Agentic engineering describes how a developer should work. Write specifications first. Review agent output with the same rigor as human code. Test relentlessly. Maintain architectural discipline. These are practices, and they are correct. Osmani’s observation that “agentic engineering actually rewards strong fundamentals more than traditional development” matches exactly what I found building the system described in You Can Build This. Three Artifacts and a Sandbox.
The problem is that practices depend on practitioners. A developer following agentic engineering principles produces governed output. A developer who skips the specification step, or merges without reviewing the diff, or runs without tests, produces ungoverned output. The practice has no mechanism to enforce itself. It relies on discipline, and discipline degrades under pressure. Deadlines compress. Scope expands. The careful developer who reviews every diff at 10 AM rubber-stamps the last three at 6 PM.
Any approach that lives in behavior rather than infrastructure has this limitation. Verification Beats Debugging made the same argument in the AgenticOps Applied series: the fix is not better discipline, it is verification pipelines that make discipline unnecessary. What matters is what happens when developers do not follow the practice, because eventually they will not.
Where Agentic Engineering Stops
The agentic engineering literature covers three activities well. Intent specification: write a design document or task description before prompting. Agent generation: let the agent implement within a scoped context. Evaluation: review the output, run tests, verify correctness. These map to the first three layers of the AgenticOps model from What AgenticOps Actually Looks Like: Intent, Agent Generation, and Evaluation.
The literature is largely silent on what happens after evaluation. Promotion, the controlled movement of verified work into production environments, is rarely addressed. Runtime governance, the observation and constraint of agent behavior in live systems, appears only in security-focused discussions. Knowledge compression, the systematic reduction of system complexity into navigable artifacts, is almost entirely absent.
These are layers four through six. They are the layers that turn a development practice into an operational system. Without them, agentic engineering produces high-quality work in development and hopes it stays that way in production.

The feedback loop matters. Knowledge compression feeds back into intent. The compressed understanding of how the system behaves in production shapes the next round of specifications. Without that loop, each development cycle starts fresh. With it, each cycle compounds on what the system learned about itself.
Containment Is Not a Practice
The four containment rings from How Agents Stay in Bounds illustrate the difference most clearly.
- Constrain inputs.
- Constrain environment.
- Validate outputs.
- Gate promotion.
These are not things a developer does. They are things the system enforces.
Ring 1, constraining inputs, means the agent receives a scoped context defined by skill files and schemas. The developer did not decide at runtime what to include. The constraint existed before the agent started. Ring 2, constraining the environment, means the agent runs in a sandbox that physically prevents access to anything outside the workspace. The developer did not have to trust the agent not to wander. The environment made wandering impossible. Ring 3, validating outputs, means automated gates evaluate the result against measurable criteria. The developer did not have to judge quality from a diff. The gate returned a score. Ring 4, gating promotion, means nothing moves forward without evidence. The developer did not have to remember to check. The system refused to proceed without passing the gate.
OpenClaw Is Not an AI Assistant demonstrated this with three isolation layers and multiple containment rings around a real agent runtime: Docker sandboxes, tool sandboxes, allowlists, network restrictions, and human approval gates. The containment was not a developer practice. It was infrastructure configuration. The agent could not violate the boundary because the boundary was physical, not procedural.
Agentic engineering asks the developer to be disciplined. AgenticOps builds the system so that discipline is the default and violation is structurally difficult. The distinction is the same one from How Agents Stay in Bounds: policy says “don’t.” Infrastructure says “can’t.”
Practice Drifts. Infrastructure Holds.
A Hacker News commenter captured the concern precisely: “The effects of vibe coding destroy trust inside teams and orgs, between engineers.” The damage comes not from individual failures but from inconsistency. One developer follows the practice. Another does not. The codebase contains governed and ungoverned output that looks identical in a pull request.
Infrastructure eliminates this variance. When every agent session runs inside the same sandbox, uses the same constraint files, and passes through the same gates, the output quality has a floor. Individual developers can exceed the floor. They cannot go below it. Most Software Is Just CRUD. That’s Not the Problem. argued that the danger is cheap generation without constraint discipline. Infrastructure is how constraint discipline survives contact with a team of twenty developers, varying skill levels, and a Friday afternoon deadline.
The Treasure Data case study illustrates this concretely. They tried speed without structure first. Then they embedded governance into infrastructure, not policy documents. The result was one engineer shipping a production AI tool in an hour. The constraint was the accelerator. Governance infrastructure made them faster because it removed the decision overhead that slowed them down. Every developer on the team produced output that met the same quality bar because the quality bar was enforced by the system, not by individual judgment.
The Build Plan Still Works
The three artifacts from You Can Build This are the implementation of this distinction.
- Constraints are Ring 1.
- Agent definitions with tool allowlists and forbidden lists are Ring 2.
- Gates with measurable success criteria are Rings 3 and 4.
The sandbox makes containment physical. None of these require the developer to remember to be disciplined. They require the developer to define the constraint once and let the system enforce it on every run.
This is why the convergence matters. Agentic engineering identified the right practices. AgenticOps provides the infrastructure to make those practices the default. The industry does not need to choose between them. It needs both. The practice tells you what to do. The infrastructure ensures you actually do it.
I am glad the industry arrived at the same conclusion. The next question is whether they will build the infrastructure or stop at the practice.
Let’s talk about it.
I Was a 1x Coder at Best. AI Made Me a 0x Coder.
Over four posts I built an argument. Total understanding is a myth. Cheap generation without governance creates invisible debt. AgenticOps is the discipline layer. Containment is the mechanism.
All of that was structural. This one is personal.
I Taught Myself to Code
I don’t have a computer science degree. I don’t have a software engineering degree. I have no formal training in the thing I’ve done for a living for well over two decades.
I learned from books. Then from Google. Then from StackOverflow. I learned from copying patterns I saw in codebases I didn’t fully understand. Eventually from building things that broke and figuring out why.
The learning never felt complete. It still doesn’t, and now it feels like I have so much more to learn.
I have OCD, ADD, depression, and imposter syndrome. The OCD means I fixate on problems until they resolve. The ADD means I struggle to focus long enough to resolve them efficiently. The depression and imposter syndrome make me doubt everything I do. Those forces fight each other constantly. Sometimes that tension produces good work. Sometimes it produces hours lost chasing details that didn’t matter.
On top of that I never felt like an engineer. The people I admired seemed to hold so much of the systems we worked on in their heads, reason about concurrency without breaking a sweat, debug memory and network issues by reading traces. They seemed to operate in a different register, a different dimension.
I watched conference talks and understood maybe half of what was said. I read papers and got the gist but not the math. I built mental models that were close enough to be useful but never precise enough to feel confident.
The 10x developer myth lived in my head. Not because I believed it literally, but because I measured myself against it. If they were 10x, I was 1x. Maybe. On a good day.
Yet, I ended up as a top producer or leader on all the teams I worked on, so I had some value, even if my brain doesn’t believe it.
I Spent Years Closing a Gap That Didn’t Matter
I tried to get faster. Better tooling, better shortcuts, better frameworks. I optimized my workflow to muscle memory. Split terminals, keyboard shortcuts, IDE configurations I’d tuned over years.
I got good enough. I shipped systems that handled real traffic, real money, real consequences. Payment services processing billions of dollars per month where a bug meant many people didn’t get paid. Multi-tenant platforms where a data leak meant one company could see another company’s information.
But I never shook the feeling that the real engineers were operating at a level I’d never reach. That the gap between us was fundamental, not experiential.
So I kept grinding. More books. More side projects. More late nights trying to understand things other people seemed to just know.
The gap I was trying to close was implementation speed. How fast can I translate intent into working code? How quickly can I go from “this is what we need” to “this is what exists”?
I was optimizing for the wrong variable the entire time.
AI Made Me a 0x Coder
Then in October to November of 2025 it felt like AI arrived. Not the theoretical AGI kind. The real kind that writes code.
I started using AI agents to build systems. Not as a helper. Not as autocomplete. As the implementation layer.
Today I write zero lines of code by hand. Zero.
AI scaffolds services. AI implements business logic. AI writes tests. AI refactors modules. AI generates migrations. I define what needs to exist, what constraints it must satisfy, what acceptance criteria must be met, and I evaluate that they are met. The agent does the rest.
I code 0x.
The skill I spent twenty years building, the ability to translate intent into syntax, is fully delegated. The keystrokes I optimized. The frameworks I memorized. The patterns I drilled into muscle memory. All bypassed.
It still feels like a loss. A waste. The thing I’d spent my career trying to master was now something a machine does better and faster. A 1x coder didn’t become 10x. I became 0x.
0x Is Not a Deficit
Here’s what I didn’t expect. Letting go of implementation didn’t reduce my output. It multiplied it.
AI doesn’t just write code faster and better than me. It writes at a scale I could never match. Full service scaffolding in minutes. Test suites covering edge cases I would have missed. Rewrites and refactors across modules that would have taken me days.
I was never going to write at 100x. But I can govern at 100x.
In the first post I said I scale containment, not understanding. I wrote that before I’d lived it. Now I have.
In the second post I argued the hard parts were never typing. In October 2025 I meant it theoretically. Today, I mean it literally. I don’t type production code. The hard parts, the constraint decisions, the system boundaries, the verification criteria, those are the only parts I do.
The six layers from the third post. Intent, agent generation, evaluation, promotion, runtime governance, knowledge compression. Those are not a framework I designed in the abstract. They are the operating system I iterate on because I had to. Because governing agent output is the only way 0x works.
The four rings from the fourth post. Constrain inputs, constrain environment, validate outputs, gate promotion. Those are not best practices on a slide. They are the walls of the house I am building to live in. Without them, 0x is reckless. With them, 0x is operational.
What a Day Looks Like for a 0x Coder
Here is the 0x workflow in practice.
- Define intent. What value does this slice deliver? What state transitions does it manage? What must never break?
- Define contracts. Input schemas, output schemas, interface definitions, invariant list.
- Define tests. Contract tests, integration tests, edge case scenarios. The tests exist before the implementation does.
- Scope the agent. Mount the contracts, tests, and bounded context into the agent’s workspace. Nothing else.
- Generate. The agent plans, scaffolds, implements, and refactors inside its scope.
- Evaluate. The evaluation pipeline runs automatically. Contract tests, static analysis, security scanning, schema validation.
- Review outcomes. I don’t read generated code line by line. I review whether behavior matches intent. Test results, API output diffs, invariant checks.
- Approve or reject. If the evidence says it works, promote. If not, refine the constraints and loop.
That loop is my job. I don’t write code. I write constraints and review evidence. I don’t delegate my responsibility to deliver value.
There are skills, besides coding, that I spent twenty years building that still matter, but not the way I expected.
I understand systems well enough to define intent for them. I understand failure modes well enough to write meaningful constraints and acceptance criteria. I understand architecture well enough to scope agents tightly. I understand system risks well enough to judge when evidence is sufficient.
Understanding code well enough to evaluate it is different from writing it. Both are valid. Evaluation may matter more now.
The Skills That Actually Compound
I worried about the wrong things for twenty years.
I thought typing speed mattered. What compounds is system design.
I thought language mastery mattered. What compounds is constraint definition.
I thought memorizing APIs mattered. What compounds is evaluating outcomes.
I thought writing code from scratch mattered. What compounds is judging output.
I thought line-by-line review mattered. What compounds is evidence-based verification.
I thought understanding every line of code mattered. What compounds is understanding boundaries.
The first list is what I optimized for as a 1x coder. The second is what I actually use as a 0x one.
Every one of those skills in the second list was something I was already doing alongside the coding. Designing systems, defining boundaries, testing behavior, evaluating risk. I just didn’t recognize them as the primary skills because the coding felt like the real work.
It never was.
The Code Was Never the Value
This is the part I had to live to believe.
I spent twenty years measuring myself by my ability to produce code. When AI took that ability away, it felt like losing the foundation of my career. Will I miss the act of coding? Yes. But more than that, I worried that without it, I had no value to add.
But the foundation was never the code. The foundation was the ability to solve problems and deliver value. My value add was being able to understand systems, judge outcomes, define constraints, and make decisions under uncertainty. Writing a for loop was not where the value lived. The code was always an artifact of those decisions. Not the decisions themselves.
The payments service worked because I understood the state transitions, not because I typed the implementation. The multi-tenant platform was secure because I understood the isolation requirements, not because I wrote the permission layer by hand.
In the first post I said my decisions are what matter. I believe that more now than when I originally wrote it. I’ve spent time producing real systems without writing a single line of code, and the outcomes are the same or better than what I produced when I typed everything myself.
Not because I’m better or AI is better. Because the division of labor is optimized. Humans are good at intent, constraints, judgment, and risk assessment. Agents are good at implementation, coverage, consistency, and speed. Combining them beats either one alone.
Coding and Building Are the Same Thing Again
Grace Hopper spent her career trying to get away from code. Trying to move programming toward natural language. Uncle Bob Martin called our continued use of the word “code” a reflection of our failure to meet her goal.
I think we’re close to meeting it now. Not because prompts are natural language. Because the distinction between “writing code” and “building systems” is dissolving.
For decades, building software required coding. You couldn’t build without typing in some weird cryptic syntax. The skills overlapped so completely that we treated them as the same thing.
They aren’t. Building is intent, constraints, architecture, verification, judgment. Coding is translating those into syntax. When AI handles the translation, building remains.
The distinction was always there. We just couldn’t see it because the two were inseparable. Now they’re separated. And it turns out the building side is where the value was all along. I am a system builder and an AI agent operator.
Five Posts. One Thesis.
I’ve never fully understood the systems I work in. AI made that worse, but containment made it manageable.
Most software is CRUD molded into value. Cheap generation without governance creates invisible debt, but constraint discipline prevents it.
AgenticOps is the governance model. Six layers. Four rings of containment. A hard line between what agents generate and what systems execute.
The human’s role didn’t shrink. It moved. From implementation to intent. From typing to judgment. From code review to evidence review.
And this last part is the one I had to live to believe. The code was never the value. The decisions were. A 0x coder governing a 100x agent produces better outcomes than a 1x coder typing everything by hand.
I know because I’m the 0x coder. And I believe the systems I’m building now are as good or better than the systems I hand coded. What’s your experience?
Let’s talk about it.
Previous: [How Agents Stay in Bounds]
Next: [You Can Build This. Three Artifacts and a Sandbox.]
Most Software Is Just CRUD. That’s Not the Problem.
I spent my career in startups, enterprises, and small boutique consultancies. And if I’m being honest about most of the systems I’ve worked on, they were over-complicated CRUD machines.
Different domains. Different UIs. Different industries. But underneath? Create, read, update, delete. From the UI to the API to the database, we molded CRUD into something usable, something valuable.
We wrapped business rules around it. We added workflows, enforced permissions, tracked state transitions, sprinkled in some complex algorithms where needed. But the core of what most systems do? They move data around.
That doesn’t make these systems trivial. It makes them structured. State machines, permission layers, data mutation rules, integration plumbing. And structured domains are exactly the kind of thing that’s automation-friendly.
That’s why AI is both dangerous and powerful at the same time.
The Word “Code” Is 80 Years Old. So Is the Problem.
In my last post I mentioned Uncle Bob Martin’s observation about Grace Hopper and the origin of the word “code.” It’s worth sitting with for a minute.
When Hopper and her team programmed the Harvard Mark I, “code” meant the numbers they wrote on paper. Numbers representing hole positions on 24-bit paper tape. That was the program.
Hopper spent the years after that trying to get away from code entirely, trying to move programming toward natural language. She built some of the earliest compilers to do it.
Eighty years later, we still call our programs “code.” Every step up the abstraction ladder, from hole positions to assembler to Fortran to C to managed runtimes to cloud abstractions, we kept calling it code.
The people closer to the metal always complained that the higher level didn’t understand what was really happening. And they were right, at a certain level. But that was always the point.
We don’t punch cards anymore. We don’t read assembly to ship a CRUD app. We don’t manage memory for every request lifecycle.
Each time we moved up, we traded low-level visibility for leverage. The people who adapted operated at a different level entirely. The people who clung to the lower layer complained about the inadequacies of the higher one.
Now the abstraction layer is rising again. But this time, the nature of the shift is different.
This Abstraction Step Isn’t Like the Others
Every previous step up the abstraction ladder was deterministic. C compiled to assembly the same way every time. Managed runtimes handled memory according to defined algorithms.
Cloud abstractions mapped to infrastructure through predictable configurations. You could trace the path from the higher level to the lower level. The mapping was knowable.
AI-generated code doesn’t work like that. It’s stochastic. Ask it to scaffold a service and you’ll get something reasonable, something that works, but it’s sampled, not compiled. Run it again and you might get a different implementation. The output sits in a probability space, not a deterministic one.
For most CRUD scaffolding, this doesn’t matter much. The solution space is narrow enough that the probabilistic output is reliably close to what a deterministic process would produce.
Wiring up a DTO, implementing a repository pattern, generating a migration. These tasks are constrained enough that AI’s stochastic nature is practically invisible.
But when AI starts reasoning through edge cases, inferring business intent, or making architectural choices, the stochastic nature matters a lot. The danger is the mismatch: probabilistic reasoning producing artifacts that systems treat as deterministic truth.
A contract, a migration, a security boundary. Once it exists, the system executes it as fact. It doesn’t know or care that it was generated by a process that could have gone differently.
That’s the new risk that didn’t exist at any previous level of the abstraction ladder.
The Danger Isn’t That CRUD Is Simple. The Danger Is That CRUD Becomes Cheap.
This is the part I don’t see enough people talking about.
When CRUD becomes nearly free to produce, more systems get built. More features get added. More integrations get stitched together. More surface area exists than anyone can reason about.
The cost per unit of implementation drops toward zero, but the governance cost per unit doesn’t. Anything that becomes cheap gets overproduced. That’s not a software principle, it’s an economic one.
Without constraint discipline, we won’t get better systems. We’ll get more of them. Layered, duplicated, loosely governed, and fragile. The implementation volume explodes but the system intent stays murky. And now the implementation is stochastic on top of it.
That’s invisible complexity debt. And it compounds.
Humans Love Proving AI Is Wrong
I see it constantly. Humans reveling in AI getting things wrong.
“See? It misunderstood the intent.” “See? It missed an edge case.” “See? It hallucinated.”
There’s almost a celebration every time someone can prove that humans are still necessary in the SDLC. I get it. But it’s a weak position. It’s defensive. It’s arguing that our value is in catching mistakes in 300 lines of generated code.
The mistakes they’re catching are stochastic outputs that slipped through without verification. The solution isn’t to celebrate catching them. The solution is to build systems where they get caught before they matter.
Humans are becoming the bottleneck in raw code production. Not because we’re irrelevant, but because we’re slower.
An AI can produce hundreds of lines in seconds. It can scaffold services, wire up DTOs, implement repository patterns, generate migrations, create test suites. A human doing that line by line is objectively slower.
Just like punching cards was slower. Just like writing assembly was slower. Just like manually allocating memory everywhere was slower.
We abstracted those layers away. Now we’re abstracting away bulk implementation.
The Hard Parts Were Never Typing
This doesn’t make software development easier. If anything it gets harder. Because the hard parts were never typing.
Consider two examples.
A payments service needs to decide what happens when a refund is requested after a partial chargeback has already been applied. AI can generate the refund endpoint in seconds. It cannot decide whether the business eats the overlap, rejects the refund, or caps it at the remaining amount. That’s a constraint decision.
A multi-tenant system needs to determine its isolation boundary. AI can scaffold either a shared-database or database-per-tenant architecture in minutes. It cannot decide which one is right. That depends on compliance requirements, cost structure, and what the business can tolerate if a tenant’s data leaks into another tenant’s view.
AI can generate CRUD scaffolding all day long. It cannot make these kinds of decisions. And that responsibility doesn’t shrink as abstraction rises. It intensifies, especially when the abstraction layer below you is probabilistic instead of deterministic.
The Human Moves Up the Stack to the Verification Boundary
Every time we moved up the abstraction ladder, the human role shifted. We stopped writing the lower-level thing and started governing how it got produced. This time, the shift has a specific shape.
I don’t need to read every line of generated CRUD anymore. What I need to do is govern the boundary between stochastic generation and deterministic system surfaces. I need to make sure that nothing AI produces probabilistically hardens into load-bearing system behavior without verification.
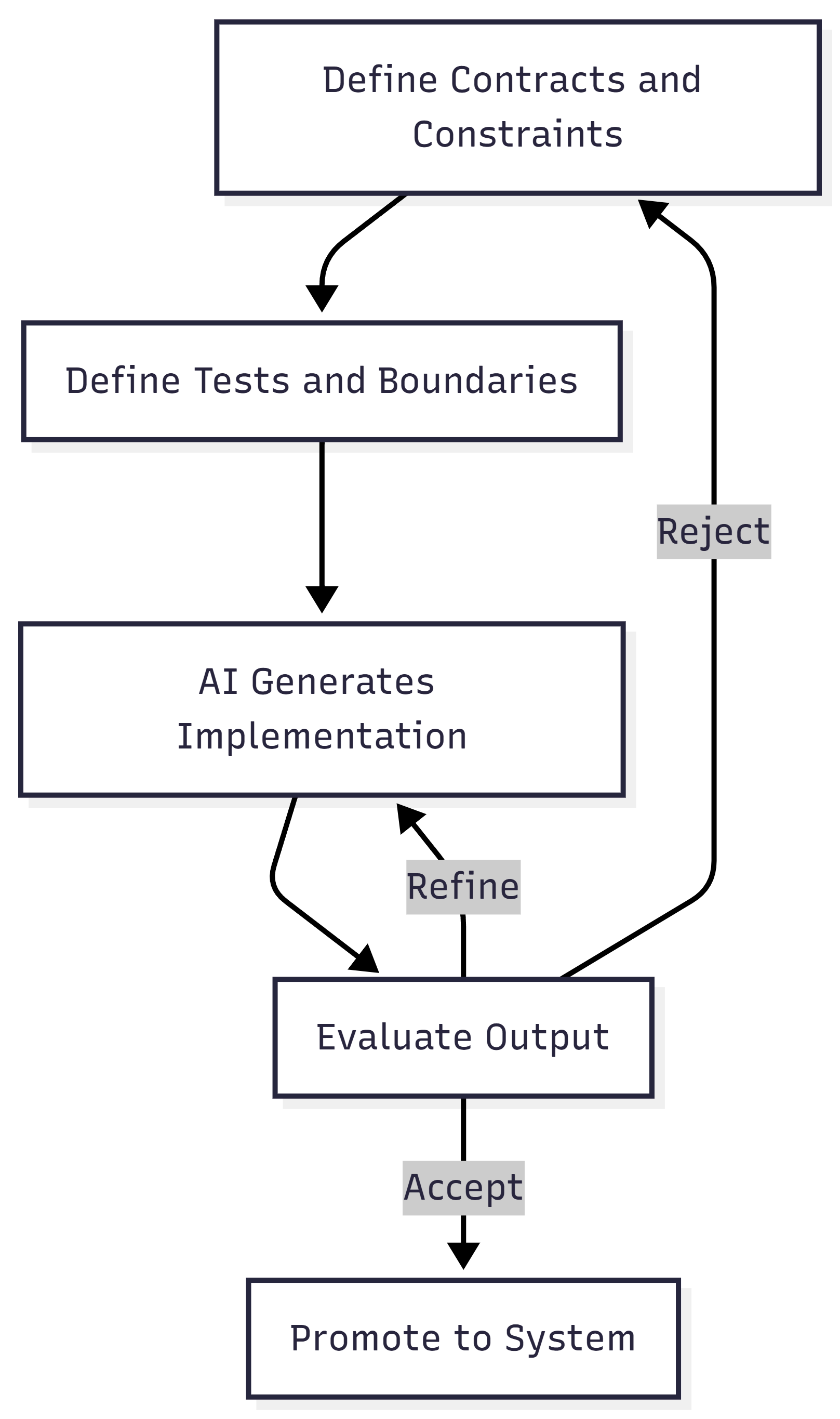
That governance takes a specific form. The constraint-first loop:
- Define the contract. Specify inputs, outputs, invariants, and boundaries before any code is generated.
- Define the tests. Write verification criteria that encode what correct behavior looks like.
- Generate. Let AI implement against the contract and tests.
- Evaluate. Run the tests. Check the output against the contract.
- Reject or accept. If the output violates the contract, reject it. Do not patch stochastic output manually.
- Refine. Tighten the contract or the tests based on what failed.
- Loop. Repeat until the output passes verification.
PassFailDefine ContractDefine TestsGenerate with AIEvaluate OutputAcceptRejectRefine Constraints
This loop isn’t just a workflow preference. It’s the verification layer that makes AI-assisted development safe. Without it, you’re letting dice rolls become the walls of your building.
The human moves from “writer” to “architect and governor.” And that’s uncomfortable for people who built their identity around keystrokes.
We Might Need More People, Not Fewer
Here’s the part people don’t expect: we may need more humans in this world, not fewer.
The reasoning is simple. If generation cost drops to near zero, the volume of systems being built explodes. Every new system still needs someone to define its constraints, verify its behavior, govern its boundaries, and decide what it should and shouldn’t do.
Those tasks don’t compress the way implementation does. A single architect can’t govern fifty AI-generated services any more than a single building inspector can sign off on fifty skyscrapers going up simultaneously.
So the roles shift. Fewer people writing boilerplate. More people designing systems, defining evaluation criteria, modeling business intent, and governing safety. The bottleneck won’t be “who can type the fastest.” It’ll be “who can think clearly about systems at the rate those systems are being produced.”
The Abstraction Layer Is Rising. Again.
Software was never about typing. It was about shaping constraints around state.
That truth has been there since Hopper’s team wrote hole positions on paper. It’s been there through every abstraction layer since. The implementation details changed. The nature of the work didn’t.
CRUD isn’t the problem. Cheap CRUD without containment is. We’re about to produce more software in five years than the previous fifty combined. The question isn’t whether we can generate it. The question is whether we can scale constraint discipline as fast as we’re scaling code production.
That’s where AgenticOps begins.
Let’s talk about it.
Previous: [I’ve Never Fully Understood the Systems I Work In. AI Is Making That Worse.]
I’ve Never Fully Understood the Systems I Work In. AI Is Making That Worse.
I don’t know how many systems I’ve worked in without fully understanding how they work.
I’ve debugged production issues in codebases I’d never seen before. I’ve added features to systems that were built years before I showed up. I’ve built systems understanding how they are built but not why they are being built.
No documentation. No architecture diagrams. No one left on the team who could explain why that weird abstraction exists or what constraints shaped the original design. No context on the intent behind the technical debt I was inheriting. No explanation for why the system was overly complex.
I have built and maintained small systems, massive systems at scale, and in between. I rarely, if ever, had a complete understanding of any of them. I couldn’t hold them in my head. I couldn’t walk through them class by class, function by function, or explain them end to end with any real confidence.
Not because of some personal failing. Because complex systems are not memorizable. They never were.
AI Expands the Surface Area
AI can produce thousands of lines of code in a day. It can scaffold entire services, generate integrations, write tests, refactor modules. The surface area of what “exists” in a codebase is exploding. I’m going to know even less than I did before about what’s in these code repositories.
So the question I keep coming back to isn’t “how do I understand everything?” That was never realistic for me. The question is, how do I operate safely and effectively in systems I don’t fully understand, especially when AI is multiplying how much code exists?
Code is accumulating faster than any human can read it, and the abstraction layer I operate in is rising with it. The problem isn’t just bigger. It’s structurally different.
Total Understanding Was Always a Myth
I could never understand a complex system end to end. Not really. Especially once it crosses a certain threshold of complexity. What I understand are abstractions, the models, flows, boundaries, invariants.
Mechanical familiarity, reading and understanding every line, is not the same as structural comprehension. As a C# programmer you don’t read the IL the compiler emits. Not because the IL doesn’t matter, but because the compiler operates within constraints that make line-by-line review redundant. The language specification is the review.
Do we need to do a mechanical review of code generated by an agent?
A fair objection is a compiler is deterministic. Same input, same output, every time. An agent is stochastic. Same constraints can produce structurally different code on each run. But that variance isn’t new. Put three developers in separate rooms with the same requirements and you’ll get three different implementations. Different variable names, different control flow, different abstractions. The output was never deterministic. We dealt with that variance long before AI through code review, architecture, contracts, and automated checks and tests.
The best reviewers never reviewed code by expecting a specific implementation. They reviewed structurally: does it satisfy the contract, pass the tests, respect the boundaries? But plenty of code review was mechanical. Line by line, checking syntax, naming, style, catching things a linter should catch. That worked when the volume of code roughly matched the capacity to read it.
Agents break that balance. They produce more code than any human can efficiently read line by line. Mechanical code review doesn’t scale to agent-speed output. What replaces it isn’t less review. It’s a different kind of review. Instead of code review maybe we call it peer review or agent-assisted review with a focus on constraints, invariants, contracts, and structural correctness. The discipline that the best reviewers always practiced becomes the only viable approach.
What actually matters is: what value does a system produce? Who consumes it? What are the critical flows? Where are the boundaries? What must never break? How to increase maintainability, quality, security… value?
If I can explain how value moves through a system, I’m in control of how I move and operate in that system. If I can’t, I’m guessing. And I’ve done enough guessing with enough experience to make intuition look intentional. I hallucinated long before AI.
I Had to Stop Thinking Bottom-Up
For a long time my instinct when entering a new codebase was to start reading code. File by file, class by class. It felt productive. It wasn’t. I ended up with a pile of implementation details and no mental model to hang them on. I understood How without the Why.
The Why, the business purpose a system exists to serve, is the reason I was hired. The systems I worked in existed for a reason. Understanding the services that serve the users of the system maps to that purpose. Designing, building, and maintaining services is what I do, and the Why is the reason I do it.
Understanding moved top-down. Define the Northstar of the system and the purpose of its services. Map the user problem to the user experience through service interfaces and the contract for inputs and outputs.
Identify state transitions and data flows. Understand the dependencies. Clarify the invariants, the things that must always be true for the system and services to function.
Only then do I care about how specific classes or functions are implemented.
If I can’t sketch a system or service on a whiteboard in five minutes, I don’t understand it yet. Doesn’t matter how many files I’ve written or read. I am hired to support the Why above the code.
With AI Agents, My Role Changes
Today, I’m not the typist, the writer of code, that focuses on the How. I’m the operator of AI agents. I deliver the Why by designing and evaluating the How driven by agents.
Uncle Bob Martin made a sharp observation in his book We, Programmers. He traces how the word “code” comes from Grace Hopper’s team programming the Harvard Mark I. “Code” referred to the numbers they wrote on paper representing hole positions on 24-bit paper tape.
Hopper spent the rest of her career trying to get away from code, trying to move toward more natural languages. Eighty years later, we still call our programs “code.” Uncle Bob calls that a reflection of our failure to meet her goal.
He frames the AI question as a binary. Is AI just the next compiler, translating higher-level code to lower-level code? Or is it what Hopper envisioned, something where prompts aren’t code at all, but natural language negotiations and the realization of Hopper’s goal?
It’s a good question. But I wonder if compiler-vs-negotiation is the real axis.
I view it more as deterministic vs stochastic.
When AI scaffolds a CRUD service from a schema, the output is predictable and verifiable. The task has a narrow solution space with deterministic input, clear schema, clear constraints, predictable output. You can inspect it and trust it roughly the way you’d trust a compiler.
When AI reasons through edge cases, infers business intent, or makes architectural judgment calls, that’s probabilistic. Ambiguous intent, competing constraints, tradeoffs that require iterative refinement. The output isn’t necessarily wrong, but it’s sampled a next token guess. Run it again and you might get a different answer.
And the confidence surface is invisible. There’s no compiler warning when AI makes a plausible-but-wrong architectural choice. Hallucinations don’t have an error code.
The mistake is using stochastic reasoning to produce deterministic system surfaces without verification.
A contract. An interface. A migration. A security boundary. These become load-bearing the moment they exist. The system doesn’t know or care that the thing defining its behavior was probabilistically generated. It executes it as truth.
This is the gap. AI can generate implementation, the How. What it can’t generate are constraints, architectural boundaries, risk surfaces, and operational discipline. Yes it can write words that appear to be constraints, but I can’t delegate my responsibility for them, even if I let AI do most of the writing.
What I allow to go into production is on me, no one else. It’s on me to make sure that anything AI generates probabilistically gets verified before it hardens into something a production system treats as fact.
If AI writes 10,000 lines of code and I haven’t defined the contracts, the interfaces, the performance expectations, the security constraints, the observability requirements, and the test surfaces, then I’ve let dice rolls become load-bearing walls in the system.
AI doesn’t remove architectural responsibility. It amplifies it.
I Don’t Scale Understanding. I Scale Containment.
I’m not trying to know everything. I gave up on that a long time ago. What I’m trying to do is design systems where I don’t have to know everything.
That means clear interfaces. Explicit schemas. Strict typing. Unit tests, contract tests, integration tests, security and performance tests. Tracing and metrics. Logs that actually tell me something useful when things go sideways.
If something breaks, I don’t rely on memory. I rely on instrumentation. Understanding becomes observational, not memorized.
I can’t hold 200,000 lines of code in my head. But I’ll hold onto a one-page system summary, a lifecycle map, a state machine diagram, a list of invariants, a list of “what must never happen,” and a dependency diagram.
Those are the compression artifacts I’ll actually carry around. Not the implementation. The constraints that govern it.
And with AI generating code faster than I can read it, constraint-first is the only sane approach. Define the contract. Define the tests. Define the boundaries. Then let AI implement. Evaluate the result. Accept, reject, or refine. Loop until convergence.
That loop is the verification layer. It catches stochastic output before it becomes deterministic system behavior. Without it, AI-generated systems turn into unbounded complexity farms.
When I design and build, I optimize for maintainability and low mean time to value. Containment is how I get there.
The Real Shift
I believe the industry is moving from “I understand every line of code” to “I understand the boundaries, constraints, and risk surfaces.” Some might call that a loss of craftsmanship. I think it’s evolution.
The skill isn’t omniscience. It’s navigational confidence. Can I enter a foreign system, form a hypothesis, test it safely, reduce the blast radius, and improve it incrementally? If yes, I’m fine. AI doesn’t change that. It just increases the speed at which I can do it.
I don’t think software development has ever been about typing in a coding language. To me it’s about shaping constraints around state.
The job is transcending up a layer of abstraction, operating teams of AI agents and governing the boundary between what AI generates probabilistically and what systems execute deterministically. The code, whether I wrote it or AI did, is an artifact of my decisions. And my decisions are what matter.
That’s the shift I’m building around. And I call it AgenticOps.
Let’s talk about it.

Enterprise SaaS is Broken. AI Agents Can Fix It.
Let’s talk about enterprise software.
Everyone knows the dirty secret: it’s complex, bloated, slow to change, and ridiculously expensive to customize. It’s a million dollar commitment for a five-year implementation plan that still leaves users with clunky UIs, missing features, and endless integration headaches.
And yet, companies line up for enterprise software as a service (SaaS) products. Why? Because the alternative, building custom systems from scratch, can be even worse.
But what if there was a third way?
I believe there is. And I believe AgenticOps and AI agents are the key to unlocking it.
The Current Limitation: AI Agents Can’t Build Enterprise Systems (Yet)
There’s a widely held belief that AI agents aren’t capable of building and maintaining enterprise software. And let’s be clear: today, that’s mostly true.
Enterprise software isn’t just code. It’s architecture, security, compliance, SLAs, user permissions, complex business rules, and messy integrations. It’s decades of decisions and interdependencies. It requires long-range memory, system-wide awareness, judgment, and stakeholder alignment.
AI agents today can generate CRUD services and unit tests. They can refactor a function or scaffold an API. But they can’t steward a system over time, not without help.
The Disruptive Model: Enterprise System with a Core + Customizable Modules
If I were to build a new enterprise system today, I wouldn’t sell build a monoliths or one-off custom builds.
I’d build a base platform, a composable, API-driven foundation of core services like auth, eventing, rules, workflows, and domain modules (like claims, rating engines, billing, etc. for insurance).
Then, I’d enable intelligent customization through AI agents.
For example, a customer could start with a standard rating engine, then they could ask the system for customizations:
> “Can you add a modifier based on the customer’s loyalty history?”
An agent would take the customization request:
- Fork the base module.
- Inject the logic.
- Update validation rules and documentation.
- Write test coverage.
- Submit a merge request into a sandbox or preview environment.
This isn’t theoretical. This is doable today with the right architecture, agent orchestration, and human-in-the-loop oversight.
The Role of AI Agents in This Model
AI agents aren’t building without engineers. They’re replacing repetition. They’re doing the boilerplate, the templating, the tedious tasks that slow innovation to a crawl.
In this AgenticOps model, AI agents act as:
- Spec interpreters (reading a change request and converting it into code)
- Module customizers (modifying logic inside a safe boundary)
- Test authors and validators
- Deployment orchestrators
Meanwhile, human developers become:
- Architects of the core platform
- Stewards of system integrity
- Reviewers and domain modelers
- Trainers of the agent workforce
The AI agent doesn’t own the system. But it extends it rapidly, safely, and repeatedly.
This Isn’t Just Faster. It’s a Better Business Model.
What we’re describing is enterprise software as a service as a living organism, not a static product. It adapts, evolves, and molds to each client’s needs without breaking the core.
It means:
- Shorter sales cycles (“Here’s the base. Let’s customize.”)
- Lower delivery cost (AI handles the repetitive implementation work)
- Faster time to value (custom features in days, not quarters)
- Higher satisfaction (because the system actually does what clients need)
- Recurring revenue from modules and updates
What It Takes to Pull This Off
To make this AgenticOps model work, we need:
- A composable platform architecture with contracts at every boundary (OpenAPI, MCP, etc.)
- Agents trained on domain-specific architecture patterns and rules
- A human-in-the-loop review system with automated guardrails
- A way to deploy, test, and validate changes per client
- Observability, governance, and audit logs for every action an agent takes
Core build with self serve client customizations.
AI Agents Won’t Build Enterprise Software Alone. But They’ll Change the Game for Those Who Do.
In this vision, AI Agents aren’t here to replace engineers. In reality, they may very well replace some engineers, but they could also increase the need for more engineers to manage this agent workforce. Today, AI Agents can equip engineers and make them faster, freer, and more focused on the work that actually moves the needle.
This is the future: enterprise SaaS that starts composable, stays governable, and evolves continuously to meet client needs with AI-augmented teams.
If you’re building this kind of Agentic system, or want to, let’s talk about it.
2025: The Year AI Transforms Work and Industry at Scale
Happy New Year! Here are my bet’s for 2025.
The rapid evolution of artificial intelligence is reshaping industries and redefining how we work. In 2025, I predict that several transformative trends will reshape the landscape of software development, industry specialization, and workforce dynamics. Below, we explore these predictions, provide additional insights, and examine the opportunities and risks that come with these changes.
1. Accelerating Improvements in LLMs
Large Language Models (LLMs) will continue to push the boundaries of what AI can do. With advancements in transformer, SSM, and other architectures, fine-tuning, and multimodal learning, LLMs will deliver faster, more accurate, and contextually rich results. We may even see an new architecture that pushes LLMs ahead even faster.
Opportunities
- Enhanced productivity and creativity in tasks like content creation, research, and customer interaction.
- Multimodal capabilities enabling seamless integration of text, images, and even video into workflows.
Challenges
- Ethical concerns around misuse, bias, and misinformation.
- Increased compute requirements may exacerbate energy consumption concerns.
2. Smaller Models, Big Potential
Compact LLMs leveraging distillation, pruning, and quantization will achieve near-parity with today’s largest models. This shift will democratize AI, making it accessible for edge devices, IoT applications, and industries with limited compute resources.
Opportunities
- Cost-effective AI solutions for SMBs.
- Expanding AI’s footprint into rural and underserved areas via low-power devices.
Challenges
- Balancing efficiency with accuracy in critical applications like healthcare diagnostics or autonomous vehicles.
3. Industry-Specific AI Takes Center Stage
The rise of verticalized AI solutions tailored to specific industries, such as marketing, healthcare, finance, and legal, will dominate the market. These solutions will provide unparalleled domain expertise, driving faster ROI for businesses.
Opportunities
- Precision and relevance in solving domain-specific challenges.
- Increased trust in AI adoption as models demonstrate real-world impact.
Challenges
- Heavy reliance on proprietary data could lead to monopolistic behavior or widen the gap between industry leaders and smaller players.
4. AI-Driven Development as the Norm
AI coding assistants like GitHub Copilot, Cursor, and Aider are already changing the way developers work. In 2025, AI will be fully integrated into development ecosystems, assisting with ideation, debugging, and even deployment.
Opportunities
- Streamlined development cycles, reducing time to market.
- Better accessibility for non-traditional developers, diversifying the talent pool.
Challenges
- Over-reliance on AI could erode foundational coding skills.
- Potential loss of creativity in problem-solving as AI-driven patterns become standardized.
5. Coding Becomes a Commodity
As AI handles the technical details of coding, the value of knowing how to code will diminish. Instead, the ability to guide AI assistants, define clear objectives, and solve high-level problems with code will become paramount. The experience to know when code is good or bad becomes more important than the just the ability to code.
Opportunities
- Broader inclusion of non-technical professionals in tech projects.
- Emergence of new roles focused on prompt engineering, strategy, and oversight.
Challenges
- A potential skills gap for current developers who fail to adapt.
- Risk of job displacement without sufficient upskilling initiatives.
6. Shippable AI-Driven Products with Minimal Oversight
In 2025, performant coding agents capable of turning product requirements into deployable solutions will emerge. These agents will handle well-defined scopes but may still require human oversight for complex or high-stakes applications.
Opportunities
- Faster MVP development for startups.
- Automated maintenance of legacy systems, freeing up human resources for innovation.
Challenges
- Ensuring quality control and accountability in AI-generated products.
- Difficulty in generalizing complex, nuanced requirements.
7. OpenAI Dominates but Faces Competition
OpenAI will maintain a stronghold on the market, but competition from Google, Meta, Anthropic, Cohere, and open-source ecosystems will heat up.
Opportunities
- Diverse options for businesses to choose from, fostering innovation and reducing costs.
- Strengthening open-source movements that promote transparency and collaboration.
Challenges
- Risk of market fragmentation, making it harder for businesses to standardize solutions.
- Proprietary dominance could limit interoperability.
8. AI Agencies Replace Traditional Agencies
Small AI agencies will rise to prominence, offering specialized services in automation, data modeling, and AI-driven marketing and development. These agencies will cater to SMBs, replacing traditional creative and technical firms.
Opportunities
- Affordable, tailored AI solutions for local markets.
- Innovation in personalized customer experiences and hyper-local strategies.
Challenges
- Ethical dilemmas in hyper-targeted advertising.
- Limited oversight in emerging markets where regulation lags behind.
9. Data Becomes the New Gold for Real This Time
Businesses will finally fully realize the value of their proprietary data, using it to train domain-specific models. Data-rich companies will dominate their industries by leveraging AI in unique and powerful ways.
Opportunities
- Competitive differentiation through unique datasets.
- Greater investment in data quality, security, and governance.
Challenges
- Risk of data monopolies exacerbating inequality.
- Increased cybersecurity threats targeting proprietary datasets.
Navigating Risks and Building for the Future
While the predictions for 2025 are exciting, they also come with challenges that require proactive measures:
- Upskilling the Workforce: Governments, businesses, and educational institutions must collaborate to prepare the workforce for AI-driven roles.
- Regulating Ethically: Establishing global standards for AI use will be crucial to avoid misuse and ensure equitable benefits.
- Driving Sustainability: Advancements in AI must prioritize energy efficiency and sustainable practices.
As we move into 2025, businesses that embrace these changes while navigating risks will unlock unprecedented opportunities. The future of work and industry is brighter, more efficient, and deeply collaborative—driven by AI.
Are you ready to harness the power of AI for your business? Let’s talk about it and get your business ready for our AI future.
