Tagged: Architecture
Governing Agent Boundaries in .NET. Not Agents.
Post 9 of the AgenticOps series argued that agent sprawl governance starts at the boundary, not the agent. This post implements that claim in a .NET stack: C#, Microsoft Agent Framework, ML.NET, PostgreSQL, and Vue.js.
—
The Problem
A .NET platform grows agents organically. A triage agent classifies inbound work items. A ranking agent scores them by priority. A summarization agent compresses context for the daily control task. An extraction agent pulls candidate work items from external signals. Each agent is individually reasonable. Same team, same framework, same infrastructure. And none of them have governed boundaries between them.
The triage agent writes a classification. The ranking agent reads it. What validates the handoff? Nothing. Ranking trusts whatever triage wrote. If triage hallucinates a category that does not exist in the scoring model, ranking silently produces garbage scores. The failure is invisible because both agents completed successfully. The boundary between them had no ring.
This compounds with every agent added. Five agents with four boundaries and internal governance is not five governed agents. It is an ungoverned system that happens to have five well-scoped components.
—
Why It Breaks
Microsoft Agent Framework makes it easy to define agents with clean internal governance. The AgentChat orchestration model handles turn-taking, tool invocation, and termination conditions. The framework governs the interior of each agent. It says nothing about what happens between agents when one agent’s output becomes another agent’s input outside of a chat.
In a typical .NET implementation, the handoff looks like this.
// Triage agent writes result to the databasevar classification = await triageAgent.InvokeAsync(workItem);await db.WorkItems.UpdateClassification(workItem.Id, classification);// Ranking agent reads the result and scoresvar ranked = await rankingAgent.InvokeAsync(workItem);await db.WorkItems.UpdateScore(workItem.Id, ranked.Score);
Both agents are governed internally. Triage has scoped tools and a defined prompt. Ranking has its own tool set and scoring model. But the handoff, the moment classification leaves triage and enters ranking, is raw. No schema validation. No ring. No gate. If the triage agent returns an unexpected classification, the ranking agent consumes it without complaint.
Agent frameworks govern agent interiors. Boundary governance is the developer’s responsibility. When nobody builds it, the boundaries are open by default. Each new agent adds new boundaries. The governance gap grows with the agent count.
ML.NET adds a second dimension. A trained model that scores work item priority is deterministic given its inputs. But when those inputs come from an upstream stochastic agent, the deterministic model inherits the upstream variance. Garbage classification in, confidently wrong score out. The ML.NET model cannot tell you its inputs were hallucinated. It will score them with the same confidence as valid inputs.
This Looks Like RPA Orchestration. It Is Not.
The pattern of contract, validate, route is decades old. ESBs enforced message schemas between services. RPA orchestration platforms validated handoffs between bots. API gateways check request payloads against OpenAPI specs. If the fix is “validate data at the boundary,” enterprise middleware solved this twenty years ago. So what is different?
The difference is what crosses the boundary.
An RPA bot is deterministic. Bot A always returns the same shape with the same value space. If the schema passes, the content is correct. The bot does not invent new categories. It does not return a structurally valid payload containing a value it fabricated. Schema validation is sufficient because the output space is closed. Every possible output is known at design time.
An AI agent is stochastic. The triage agent can return a structurally valid JSON object with a category field that contains a value no one anticipated. The schema passes. The JSON is well-formed. The category is a string. But the string is “enhancement” and the downstream scoring model has never seen that value. Schema validation caught nothing because the violation is semantic, not structural.
This is why the boundary contract checks three things instead of one. Structure: does the payload match the schema? Domain: is the content within the known value space? Confidence: does the source agent trust its own output enough to skip human review? RPA boundaries only needed the first check. Agent boundaries need all three because the output space is open.
The confidence check is the sharpest difference. RPA bots do not have confidence scores because they do not make probabilistic decisions. They execute scripts. An AI agent that classifies a work item with 0.52 confidence is telling you it is nearly guessing. That signal exists at the boundary and nowhere else. If you do not check it there, the downstream system consumes a guess as a fact.
The infrastructure pattern is old. The failure mode it defends against is new. Deterministic boundaries protect against malformed data. Stochastic boundaries protect against plausible hallucinations. The plumbing looks the same. The threat model is fundamentally different.
—
The Fix
The fix is a boundary contract enforced at every handoff between agents. The contract checks structure, domain, and confidence. In .NET, this is an interface and a middleware pattern.
The Boundary Contract
Every agent-to-agent handoff passes through a boundary. A boundary has a schema, a validator, and a log entry.
public interface IBoundaryContract<T>{ string SourceAgent { get; } string TargetAgent { get; } JsonSchema Schema { get; } BoundaryResult<T> Validate(T payload);}public record BoundaryResult<T>( bool IsValid, T Payload, string[] Violations, DateTimeOffset Timestamp, string SourceAgent, string TargetAgent);
The schema is not optional and not advisory. It is a JSON Schema definition that the payload must satisfy before the target agent receives it. The validator checks structural compliance, domain constraints, and known invalid states.
public class TriageToRankingContract : IBoundaryContract<WorkItemClassification>{ public string SourceAgent => "triage-agent"; public string TargetAgent => "ranking-agent"; public JsonSchema Schema => WorkItemClassification.JsonSchema; public BoundaryResult<WorkItemClassification> Validate( WorkItemClassification payload) { var violations = new List<string>(); if (!KnownCategories.Contains(payload.Category)) violations.Add( $"Unknown category '{payload.Category}'. " + $"Valid: {string.Join(", ", KnownCategories)}"); if (payload.Confidence < 0.0 || payload.Confidence > 1.0) violations.Add( $"Confidence {payload.Confidence} outside [0.0, 1.0]"); if (payload.Confidence < MinConfidenceThreshold) violations.Add( $"Confidence {payload.Confidence} below threshold " + $"{MinConfidenceThreshold}. Requires human review."); return new BoundaryResult<WorkItemClassification>( IsValid: violations.Count == 0, Payload: payload, Violations: violations.ToArray(), Timestamp: DateTimeOffset.UtcNow, SourceAgent: SourceAgent, TargetAgent: TargetAgent ); } private static readonly HashSet<string> KnownCategories = new() { "bug", "feature", "chore", "spike", "incident" }; private const double MinConfidenceThreshold = 0.6;}
A HashSet may be questionable compared with another type like Enum, but that besides the point. The validator catches two failure modes. First, structural violations where the triage agent returns a category the scoring model does not recognize. Second, confidence violations where the agent classified the work item but with low confidence. Low confidence means the classification should route to a human instead of flowing automatically to ranking.
The Boundary Middleware
The handoff code changes from a direct call to a governed crossing.
public class BoundaryGate<T>{ private readonly IBoundaryContract<T> _contract; private readonly IBoundaryLog _log; public BoundaryGate(IBoundaryContract<T> contract, IBoundaryLog log) { _contract = contract; _log = log; } public async Task<BoundaryResult<T>> CrossAsync(T payload) { var result = _contract.Validate(payload); await _log.RecordCrossingAsync(new BoundaryCrossing { SourceAgent = result.SourceAgent, TargetAgent = result.TargetAgent, Timestamp = result.Timestamp, IsValid = result.IsValid, Violations = result.Violations, PayloadHash = ComputeHash(payload) }); return result; }}
The calling code now looks like this.
var classification = await triageAgent.InvokeAsync(workItem);var gate = new BoundaryGate<WorkItemClassification>( new TriageToRankingContract(), boundaryLog);var crossing = await gate.CrossAsync(classification);if (!crossing.IsValid){ await humanReviewQueue.EnqueueAsync(workItem, crossing.Violations); return;}await db.WorkItems.UpdateClassification(workItem.Id, crossing.Payload);var ranked = await rankingAgent.InvokeAsync(workItem);
Invalid crossings route to a human review queue instead of silently propagating. The ranking agent never sees input that failed the boundary contract. Ring 1, constrain inputs, is now structural at the handoff.
The payload’s hash as Identity for the payload was distracting because I worried about uniqueness, but its besides the point.
There is so much to think about here, but even this is better than nothing.
The Boundary Log in PostgreSQL
Every crossing is recorded. Valid and invalid. The log serves two purposes: operational debugging and governance audit.
CREATE TABLE boundary_crossings ( id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY, source_agent TEXT NOT NULL, target_agent TEXT NOT NULL, crossed_at TIMESTAMPTZ NOT NULL DEFAULT now(), is_valid BOOLEAN NOT NULL, violations TEXT[], payload_hash TEXT NOT NULL, session_id UUID);CREATE INDEX ix_crossings_agents ON boundary_crossings (source_agent, target_agent, crossed_at);CREATE INDEX ix_crossings_invalid ON boundary_crossings (crossed_at) WHERE NOT is_valid;
The payload_hash avoids storing raw payloads in the log while preserving traceability. The partial index on invalid crossings makes it cheap to query failure patterns. A retention policy keeps six months of data, which aligns with the audit log requirements from The EU Says You Need a Kill Switch by August.
The Boundary Dashboard in Vue.js
A governance system that only engineers can read is not governance. It is logging. The Vue.js dashboard surfaces boundary health to anyone who needs to see it.
+---------------------------------------------------+| Agent Boundary Health |+------------------+----------+---------+-----------+| Boundary | Last 24h | Invalid | Rate |+------------------+----------+---------+-----------+| triage > ranking | 847 | 12 | 1.4% || ranking > summary| 835 | 3 | 0.4% || extract > triage | 214 | 31 | 14.5% || summary > daily | 412 | 0 | 0.0% |+------------------+----------+---------+-----------+
Look at that extract-to-triage boundary. 14.5% failure rate. That means the extraction agent is producing work items that triage cannot classify within its known categories. Without boundary governance, those items would flow silently through the system and produce meaningless scores. With boundary governance, they route to human review and the failure rate is visible.
The dashboard queries the boundary_crossings table through a simple API endpoint. No new infrastructure. PostgreSQL, a .NET API, and a Vue.js component.
The Boundary Map
The system knows its own topology because every boundary contract declares its source and target agent. The map is derived from the contracts, not maintained separately.

When a new agent is added to the system, it connects through boundary contracts. The map updates automatically because the contract declares the relationship. The topology is a property of the code, not a diagram someone maintains.
ML.NET at the Boundary
The ranking agent uses an ML.NET model to score work items. The model is deterministic. Its inputs are not. The boundary contract between triage and ranking protects the model from stochastic drift by rejecting inputs the model was not trained to handle.
public class RankingModelBoundary : IBoundaryContract<ScoringInput>{ public string SourceAgent => "ranking-agent"; public string TargetAgent => "ml-scoring-model"; public BoundaryResult<ScoringInput> Validate(ScoringInput payload) { var violations = new List<string>(); if (!TrainedCategories.Contains(payload.Category)) violations.Add( $"Category '{payload.Category}' not in training set. " + "Model output will be unreliable."); if (payload.FeatureVector.Any(float.IsNaN)) violations.Add("Feature vector contains NaN values."); return new BoundaryResult<ScoringInput>( violations.Count == 0, payload, violations.ToArray(), DateTimeOffset.UtcNow, SourceAgent, TargetAgent); }}
This is Ring 1 applied to a deterministic component. The ML.NET model does not need containment in the stochastic sense. It needs input validation that accounts for the stochastic source of its inputs. The boundary contract is where that validation lives.
—
Stories from Production
Five Agents, Four Boundaries, Zero Rings (Framework Vision)
A .NET platform runs five agents built with Microsoft Agent Framework. Triage, ranking, summarization, extraction, and a daily control task orchestrator. Each agent was built with scoped tools, clear prompts, and individual test coverage. The team follows agentic engineering practices. Every agent is well-governed internally.
After three months, the team notices the daily control task occasionally surfaces work items with nonsensical priority scores. The ranking model scored a work item at 0.97 priority, but the item was a routine documentation update. Investigation reveals that the triage agent classified it as an “incident” with 0.52 confidence. The classification was wrong but above the implicit threshold of “the model returned something.” The ranking model scored it as a high-priority incident because that is what the classification said.
The fix takes ten minutes. A boundary contract between triage and ranking that rejects classifications below 0.6 confidence and routes them to human review. The investigation to find the root cause took three days because nothing in the system flagged the boundary as the failure point. Every agent completed successfully. The logs showed normal operations. The failure was invisible because it lived between agents, not inside them.
The team adds boundary contracts to all four handoffs in one sprint. The extract-to-triage boundary immediately reveals that 14% of extracted work items cannot be classified. That failure rate was invisible before. Those items had been silently flowing through the system producing low-confidence classifications that the ranking model consumed without question. (Framework Vision)
The Boundary That Caught a Model Drift (Framework Vision)
Six months after deploying boundary contracts, the triage-to-ranking boundary failure rate increases from 1.4% to 8.2% over two weeks. The dashboard surfaces the trend. The violations are all the same: “Unknown category ‘enhancement.'”
The triage agent’s upstream model was updated. The new version learned a category the scoring model was never trained on. Without the boundary contract, every “enhancement” classification would flow to the ranking model and receive a meaningless score. With the contract, every “enhancement” routes to human review and the failure rate spike is visible on the dashboard the day it starts.
The fix is straightforward. Retrain the ML.NET scoring model to include the “enhancement” category, then update the boundary contract’s known categories list. The boundary caught a model drift that would have silently degraded output quality for weeks. (Framework Vision)
When the Boundary Itself Is Wrong
Boundaries will have bugs. A contract that rejects a valid category or sets a confidence threshold too high will route good work items to human review. At low volume that is a nuisance. At hundreds of crossings per hour it is a bottleneck that looks like a system failure.
Recovery speed matters more than prevention here. The crossing log records every rejection with the violation reason and payload hash. When you discover a contract was wrong, you query the log for every item that hit that specific violation, fix the contract, and replay them through the updated gate. The human review queue still holds the items because they were routed, not dropped.
The pattern this post describes does not include an automated replay mechanism. That is deliberate. Replay is a recovery operation that should be explicit, auditable, and triggered by a human who understands what the contract change means. But the log makes it possible. Without the log, a bad boundary contract means lost work. With the log, it means delayed work. Time to resolve is the metric that separates a governance system from a governance obstacle.
—
The pattern is old. Contract, validate, route, log. Enterprise middleware has done this for decades. What is new is the threat model. Deterministic systems needed schema validation. Stochastic systems need domain validation and confidence gating because the agent can produce structurally perfect output that is semantically wrong. The plumbing is familiar. The reason you need it is not.
Agent sprawl governance in .NET is not a framework feature. It is the same boundary pattern, extended for stochastic handoffs. The code is C#. The storage is PostgreSQL. The visibility is Vue.js. The principle is the same one from the main series: the unit of governance is the boundary, not the agent.
Let’s talk about it.
The EU Says You Need a Kill Switch by August. Do You Have One?
Post 4 of the AgenticOps series introduced the four containment rings. This post shows what happens when a regulator asks to see them.
You Stopped Verifying. traced how verification gaps compound under pressure. This post is about a different kind of gap. One with a fine attached.
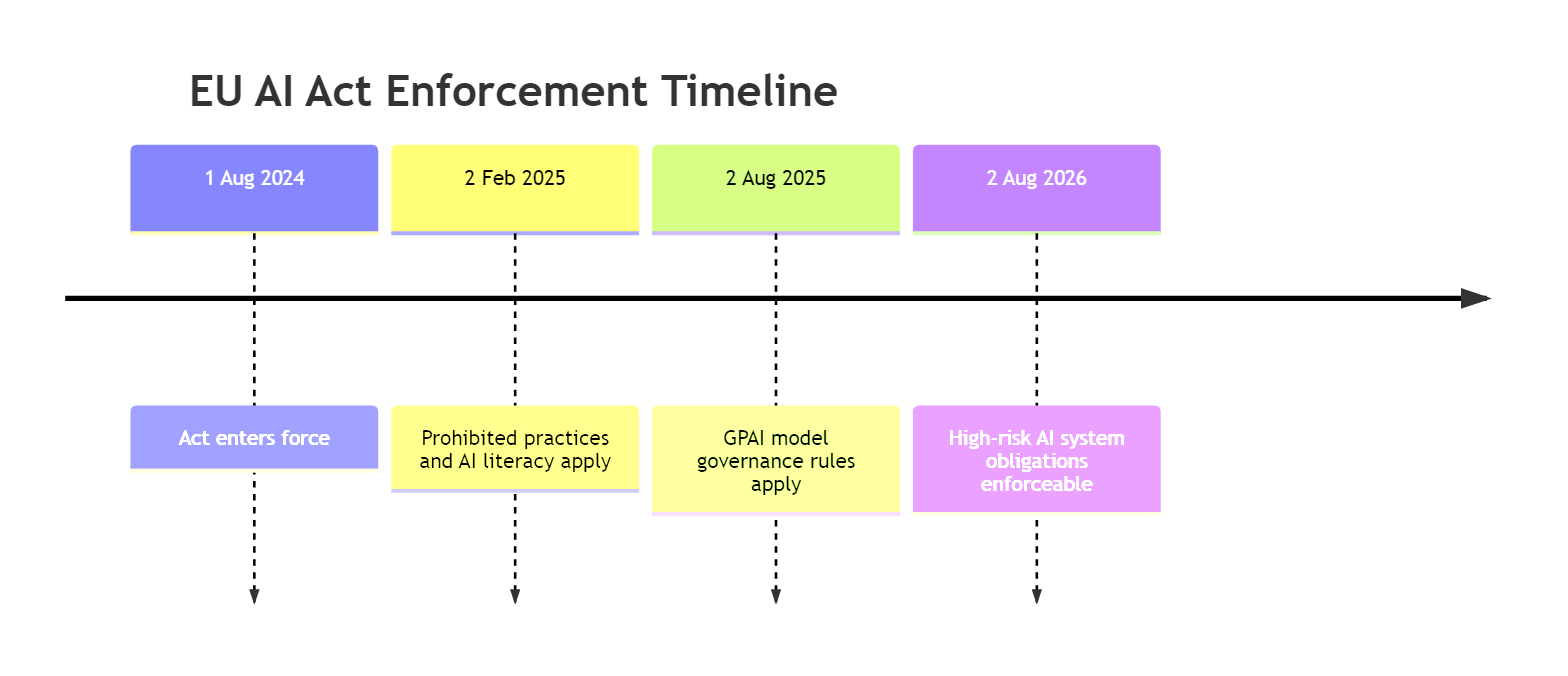
The EU AI Act enters its final enforcement phase on 2 August 2026. High-risk AI system obligations become enforceable: human oversight measures, six-month audit logs, kill switches. Not policies. Technical controls with financial penalties.
Penalties reach 35 million EUR or 7% of global annual turnover for the most serious violations. For high-risk system failures, 15 million EUR or 3% of turnover. That is not a compliance risk. That is a business risk.
I used to think AI governance meant writing the right policies. Define acceptable use. Assign a committee. Review quarterly. I know now that none of that produces a kill switch. And the Act requires one.
What the Act Actually Requires
Article 14 is specific. Natural persons assigned to oversee a high-risk AI system must be able to intervene or interrupt it through a stop button or similar procedure. Not a process that eventually leads to stopping. An actual mechanism. Operable now.
Article 12 requires automatic logging of events relevant to risk identification. Retained for at least six months. Not operational logs. Compliance logs. The kind that tell a regulator what the agent decided, what drove the decision, what it did.
Article 50 applies to all AI systems, not just high-risk ones. If your agent interacts with a natural person, it must disclose that it is an AI. Already applicable. Right now.
The Kiteworks Agents of Chaos study surveyed 225 security, IT, and risk leaders. 60% of organizations cannot terminate a misbehaving agent. 63% cannot enforce purpose limitations. 55% cannot isolate AI systems from network access. Real talk: those are compliance failures under the Act.
Why Most Organizations Will Miss It
The failure is structural. Organizations built Ring 3 first. Monitoring, logging, anomaly detection. That is the ring they already understood. The Act requires all four rings as technical controls.
First, a kill switch requires a control plane external to the agent runtime. Most organizations deploy agents as independent processes. No unified control plane. No mechanism to halt all instances simultaneously. Building one is a rearchitecting exercise, not a feature flag.
Second, compliance-grade audit logs are not operational logs. An operational log says “called API at 14:32.” A compliance log says “agent decided to escalate case 4521, sentiment 0.23, invoked route_to_queue, status change at 14:32:07Z.” Six months of those. Queryable by a regulator.
Third, purpose limitation as a technical control means the agent cannot access systems outside its intended scope at runtime. 63% of organizations define intended use in documentation. The agent’s actual scope is whatever tools and data it can reach at runtime. Feel me? That gap is what the Act targets.
The compound effect: most organizations have compliance gaps across three of four rings simultaneously. Ring 3 partially covered. Rings 1, 2, and 4 open. The Act requires all four.
The Fix: Map Rings to Requirements
Compliance is containment infrastructure. The four rings are the checklist. Let me give you a specific example.
Ring 1 is purpose limitation. Articles 9 and 13. The technical control is scoping the agent’s inputs before it starts.
# ring-1-purpose-limitation.yamlagent: customer-escalation-handlerintended_purpose: "Classify and route customer escalation tickets"tools: allowed: - read_ticket - classify_sentiment - route_to_queue denied: - update_customer_record - issue_refund - access_billingdata_scope: - tickets.escalation_queue - knowledge_base.routing_rules
When the agent cannot access billing systems, it cannot make billing decisions. Purpose limitation becomes a property of the environment, not the prompt.
Ring 2 is environmental isolation. Articles 9 and 15. Network restrictions, filesystem isolation, process sandboxing. Each boundary enforced by the runtime, not by the agent’s instructions.
Ring 3 is audit logging and transparency. Articles 12 and 50. This is the ring most organizations have partially built. The gap is granularity.

Ring 4 is the kill switch. Article 14. This is where 60% of organizations fail.
A compliant kill switch has three properties. It is reachable from outside the agent’s execution environment. It halts the agent within a bounded time, not after the task completes. It is operable by non-engineers assigned to oversight.
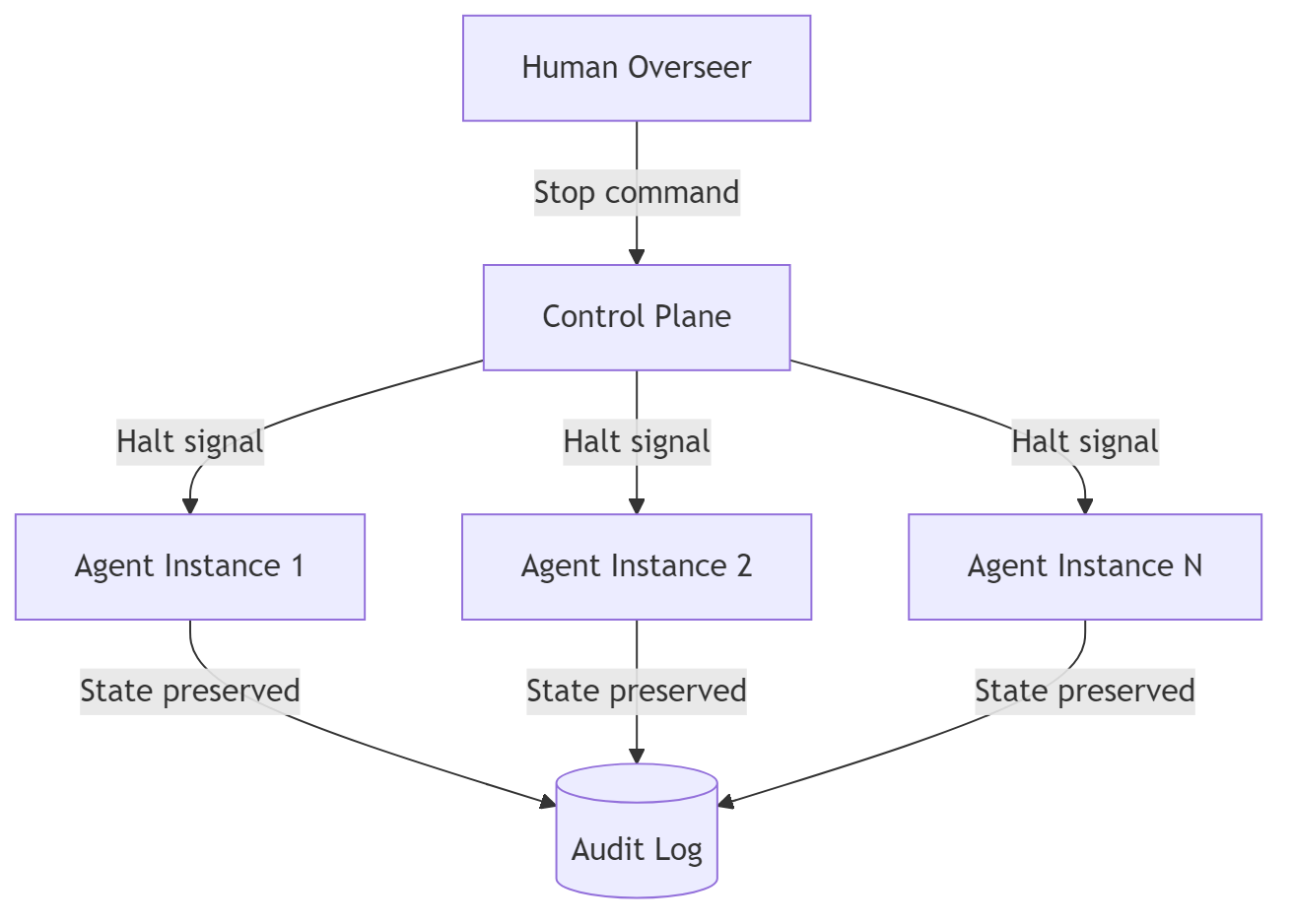
The control plane must be separate from the agent runtime. The agent cannot be responsible for its own termination.
| Ring | EU AI Act Requirement | Articles | Technical Control | Deadline |
|---|---|---|---|---|
| Ring 1 | Purpose limitation enforced | 9, 13 | Tool allowlists, data scope configs | 2 Aug 2026 |
| Ring 2 | Risk management operational | 9, 15 | Network policies, sandbox configs | 2 Aug 2026 |
| Ring 3 | Automatic logging, six-month retention | 12 | Structured audit log pipeline | 2 Aug 2026 |
| Ring 3 | Transparency disclosure | 50 | AI interaction labeling | Already applicable |
| Ring 4 | Kill switch and human oversight | 14 | Control plane, halt mechanism | 2 Aug 2026 |
What This Means for You
Organizations that built containment rings for engineering reasons will reach compliance faster. The rings were designed to contain stochastic processes. The Act requires containment of stochastic processes. The alignment is structural.
If you deployed agents with YAML policy controls, filesystem restrictions, and network allowlists, you are 80% of the way there. The remaining 20% is log enrichment, retention infrastructure, and a kill switch that non-engineers can operate.
Don’t be scared if you have no containment infrastructure. Article 57 requires each EU Member State to establish at least one AI regulatory sandbox by 2 August 2026. Engage early. Build the rings under regulatory guidance. Validate before penalties apply.
The four containment rings were built for engineering discipline. The regulation made them law. The infrastructure either exists or it does not. An auditor asking to see the kill switch will not accept a policy document.
Let’s talk about it.
You Stopped Verifying.
Post 4 of the AgenticOps series introduced the containment rings that keep agents in bounds. This post stress-tests the verification layer that makes containment real.
Forty-two percent of committed code is now AI-generated. Ninety-six percent of developers say they don’t fully trust it. Only forty-eight percent always verify before committing.
Those numbers are from a single survey of over 1,100 developers, published by Sonar in early 2026. Real people. Real codebases. Real behavior.
The gap between what people say they trust and what they actually verify is where the problem lives. Feel me?
The Problem
Generation and verification don’t scale the same way. That’s the whole issue.
AI generation scales with compute. You add more calls, you get more code. Human verification scales with hours in the day. You can’t add more hours without adding more people.
Sonar projects AI-generated code will hit 65% of all commits by 2027. That’s not a capability prediction. It’s an adoption curve. Seventy-two percent of developers who tried these tools already use them daily. The volume is accelerating.
Here’s the math that doesn’t work.
| Year | AI-Generated Code | Verification Rate | Effective Coverage |
|---|---|---|---|
| 2025 | 42% of commits | 48% always verify | ~20% of AI code verified |
| 2027 (projected) | 65% of commits | Flat or declining | ~15% of AI code verified |
Effective coverage is already below 20%. It’s heading lower. Every month the gap widens, the cost to close it grows.
Werner Vogels, AWS CTO, put a name on this at re:Invent 2025. He called it verification debt. The term is precise. Debt compounds. Technical debt is work deferred. Verification debt is trust assumed. Both grow silently.
Why It Breaks
The failure happens in three stages. Most teams are already past stage one.
Stage one: generation outpaces review. The PR queue grows. Reviewers approve faster to keep up. Average review time drops. It feels like efficiency. It is the verification rate declining.
Stage two: trust substitutes for verification. Developers build intuitions about which AI output is “usually right.” They stop reading generated code that looks familiar. They trust the model on boilerplate and test scaffolding. This works until it doesn’t.
Thirty-eight percent of developers say reviewing AI-generated code takes longer than reviewing human-written code. AI code looks plausible. It compiles. It passes basic tests. Catching the defects requires knowing what the code should do, not just what it does.
Stage three: debt compounds. Unverified code becomes load-bearing. Tests get written against its behavior, locking in whatever it does, correct or not. Six months later, a bug surfaces. The trace goes back to a function that was AI-generated, never reviewed, and now has forty callers.
That’s not a debugging problem. That’s a structural failure.
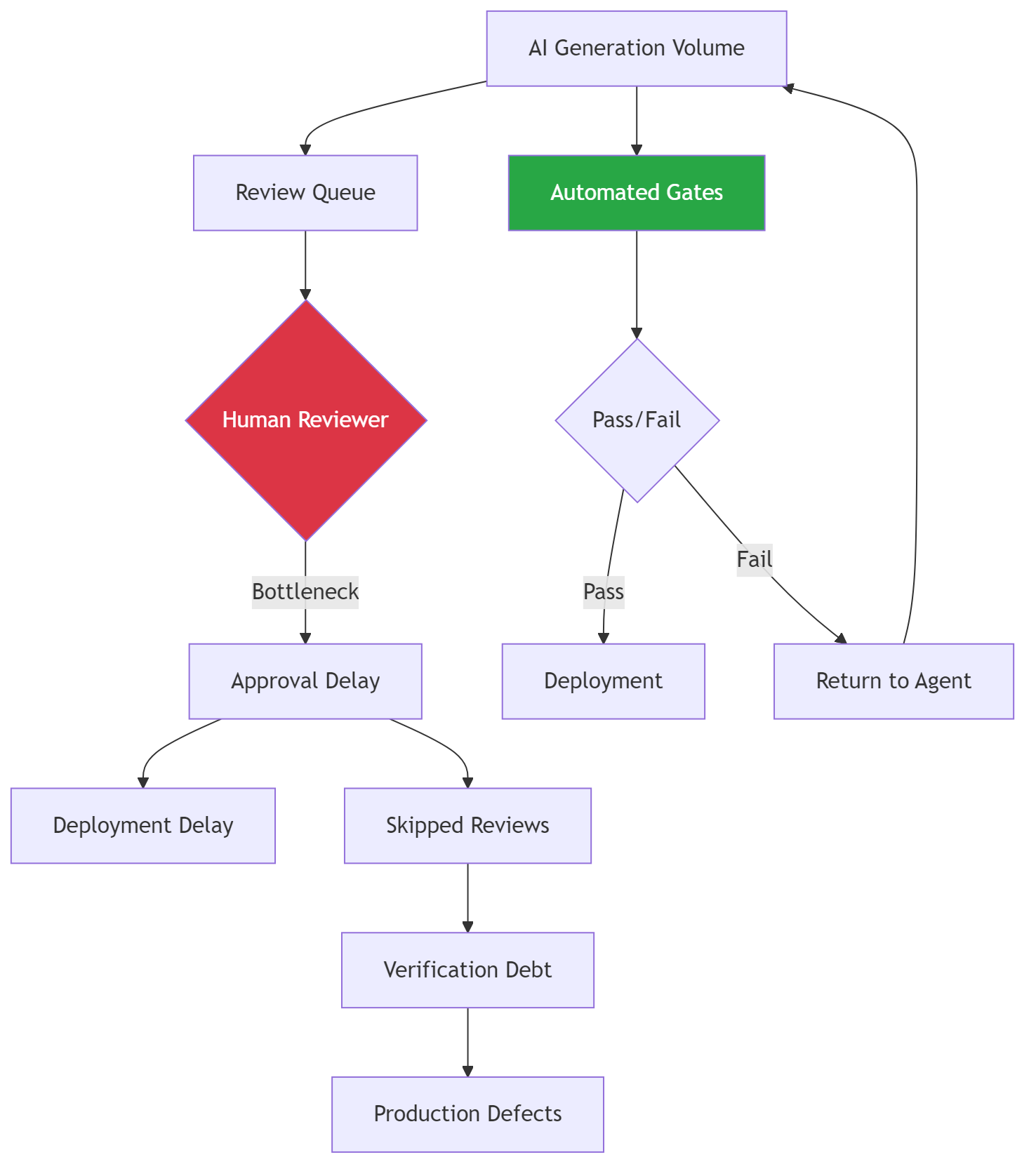
The left path is where most teams are right now. The right path is what the evaluation layer provides. No amount of developer discipline fixes a rate mismatch between generation and verification. Only automation fixes a rate mismatch.
The Fix
The fix is not “verify more.” That’s telling a drowning person to swim harder. The fix is moving verification from human effort to automated infrastructure.
Layer 3 of the AgenticOps model is the evaluation layer. It has to scale at the same rate as generation. If it doesn’t, the governance model collapses under volume.
Let me give you a specific example of what the throughput difference looks like.
| Approach | Throughput | Catches | Scales With |
|---|---|---|---|
| Human code review | ~50 LOC/hour deep | Logic errors, design flaws, intent mismatches | Headcount (linear, expensive) |
| Static analysis | Thousands of files/minute | Style violations, antipatterns, type errors | Compute (near-free at scale) |
| Mutation testing | Hundreds of functions/hour | Weak tests, untested branches, semantic gaps | Compute (parallelizable) |
| Property-based testing | Thousands of cases/minute | Edge cases, invariant violations | Compute (embarrassingly parallel) |
Human review is the only approach that cannot scale with generation volume. It is also the only one most teams rely on exclusively.
The gate sequence: each gate runs automatically, each gate has a pass/fail threshold, and code that fails returns to the agent for correction, not to a human for debugging.
Gate Thresholds
| Gate | Metric | Threshold | Action on Failure |
|---|---|---|---|
| Coverage | Line and branch coverage | >= 90% | Agent generates additional tests |
| Complexity | Cyclomatic complexity per function | <= 10 | Agent refactors or splits function |
| CRAP | Change Risk Anti-Patterns score | <= 8 | Agent reduces complexity or adds coverage |
| Mutation | Mutation score (killed / total) | >= 85% | Agent strengthens test assertions |
| Property | Property test pass rate | 100% | Agent fixes implementation |
These are machine-enforced deterministic gates. Not suggestions. Not targets. They block promotion.
When the agent generates code, the pipeline runs. When the pipeline fails, the agent fixes. When the pipeline passes, the code promotes. Humans review the gate configuration, not the code itself.
The review surface shrinks from every line of generated code to the gate definitions. That’s the inversion that makes it scale.
Three things humans still own.
First, gate configuration. What are the thresholds? Are they appropriate for this codebase? Do they need to tighten as the system matures? This is a quarterly review, not a per-commit review.
Second, intent specification. Automated gates verify structural properties. They don’t verify intent. Acceptance tests, written by humans or by agents under human review, bridge that gap.
Third, promotion decisions. Automated gates recommend promotion. Humans approve it. The human is still the final decider, but deciding from evidence instead of from reading code.
Stories from Production
The Sonar Survey Reality Check (Framework Applied)
Sonar’s 2026 survey of over 1,100 developers is the first large-scale dataset quantifying the verification gap in AI-assisted development. These are self-reported numbers from working developers. Not a lab study.
The most telling data point: 38% say reviewing AI code takes longer than reviewing human code. That contradicts the assumption that AI output is easier to review because it follows consistent patterns.
In practice, AI-generated code is harder to review because it looks right. The defects are subtle. Catching them requires knowing what the code should do, not just what it does. That knowledge is exactly what gets lost when generation is fast and context is thin.
The 72% daily usage rate confirms the generation side. Developers who try these tools stay with them. The volume is not going to decrease. Any governance strategy that assumes generation volume stabilizes will fail.
The Math That Breaks (Framework Vision)
Team of eight. Historically, each developer reviews four PRs per day at thirty minutes each. That’s 16 hours of review capacity per day.
AI generation doubles PR volume. The team faces 64 PRs per day instead of 32. Review time increases 38% per PR, matching the Sonar data. The team now needs 44.8 hours of review capacity. They have 16.
Something gives. Either review quality drops, coverage drops, or cycle time extends until the backlog collapses. All three produce verification debt.
Now run the same scenario with automated gates. The pipeline handles 90% of PRs automatically, pass or return-to-agent. Human reviewers see 6.4 PRs per day instead of 64. Each arrives with a verification report. Review time drops because reviewers are evaluating evidence, not reading code.
This scenario hasn’t been validated at full production scale. The individual components are proven. The composition into a unified pipeline that replaces human review as the primary verification mechanism is the open question. But the Sonar data is clear: the current approach is already failing at 42% AI generation. It won’t survive 65%.
Verification Debt Gets Its Name (Framework Applied)
When Vogels named verification debt at re:Invent 2025, the term stuck because it maps to something every engineer already understands. Technical debt is work deferred. Verification debt is trust assumed. Both compound. Both are invisible until they aren’t.
By naming it as a distinct category, Vogels separated verification debt from code quality, test coverage, and security scanning.
A codebase can have 90% test coverage and still carry massive verification debt. If the tests were generated by the same AI that wrote the code, and nobody confirmed the tests validate the right behavior, the coverage number is noise.
Mutation testing is the direct remedy for this specific form of debt. A test suite that kills 85% of mutants has been verified against behavioral changes, not just structural coverage. That’s the difference between “the tests run” and “the tests catch defects.”
—
The trend line is what matters. Generation is accelerating. Verification is not. The intersection already passed.
The teams that build verification infrastructure now will carry manageable debt. The teams that wait will find out what compound interest looks like in a codebase.
Don’t be scared of the infrastructure cost. Be scared of what happens without it.
Let’s talk about it.
40% Will Be Canceled. Not Because the Models Failed.
Post 3 of the AgenticOps series defined the six layers and four containment rings. This post maps Gartner’s projected cancellation drivers to specific gaps in that model.
The Comfortable Take Is Wrong
The take you keep seeing is that AI projects fail because the models are not ready. They hallucinate. They are unreliable. Wait for better models. Feel me? That is the played take. And it is distracting.
Gartner predicts more than 40% of agentic AI projects will be canceled or scaled back by 2027. The cited reasons are escalating costs, unclear business value, and inadequate risk controls.
None of those are model failures. GPT-5, Claude, Gemini will all be more capable in 2027 than they are today.
Real talk: the bottleneck is governance. Or more precisely, the absence of it.
73% of organizations are deploying AI tools right now. Only 7% govern them in real time.
That is a 66-point gap between deployment velocity and governance maturity. And that gap is exactly where the 40% lives.
80% of organizations report risky agent behaviors in production. 15% of daily work decisions will be made by agentic AI by 2028, up from essentially zero in 2024.
The industry is scaling deployment without scaling containment. Gartner’s 40% cancellation rate is not a prediction about models. It is a prediction about what happens when you run stochastic systems without structural boundaries.
Now let me give you a specific example of what is making this worse.
Of the thousands of companies now marketing “agentic AI” capabilities, roughly 130 are real. The rest are agent washing.
They are rebranding chatbots and workflow automations as agentic systems. Organizations buy those products, deploy something that does not need governance, and fail to build governance infrastructure. Then they deploy something that does need it. And discover they have nothing.
Six Failures That Compound
Accelirate analyzed agentic AI governance failures across enterprise deployments. They identified six structural problems. Every one is specific. Every one maps to a gap in the AgenticOps model.
The first failure is no centralized control plane. Teams deploy agents independently. No single system tracks which agents are running, what tools they can reach, or what decisions they make.
The second failure is late governance introduction. Teams build the agent, prove the demo, get funding, start scaling, then discover they need governance. By that point, retrofitting containment into a running system is harder than canceling the project.
The third failure is missing decision traceability. When something goes wrong, no one can reconstruct why the agent chose what it chose. The decision chain is invisible. Debugging becomes archaeology.
The fourth failure is no policy-as-code enforcement. Governance lives in documents. “Agents should not access production data.” But those policies are not enforced by the runtime. They are suggestions. And suggestions do not constrain systems that scale without warning.
The fifth failure is undefined human-in-the-loop thresholds. Everyone agrees humans should stay in the loop. No one defines when. What confidence score triggers escalation? What cost threshold pauses execution? Without thresholds, “human in the loop” is a policy statement with no implementation.
The sixth failure is poor tool differentiation. Agents get broad access because restricting tools is harder than granting them. The result is write access where there should be read access, credentials that should not be held, network reach that is not needed.
These do not happen independently. They cascade.

Each gap makes the next one harder to close. By the time an organization reaches the sixth failure, the cost of fixing the architecture exceeds the cost of canceling the project. That is Gartner’s 40%.
The Fix Is a Mapping Problem
I want to keep it real with you. The fix is not “add governance.” That sentence is vague enough to produce nothing.
The fix is mapping each failure to the specific layer or ring that prevents it, then building that layer before you need it.
| Governance Failure | AgenticOps Layer | Containment Ring | What Is Missing |
|---|---|---|---|
| No centralized control plane | Runtime Governance (L5) | Ring 2: Constrain Environment | A single registry for all running agents |
| Late governance introduction | Intent (L1) | Ring 1: Constrain Inputs | Governance requirements in the design, not the incident retro |
| Missing decision traceability | Evaluation (L3) | Ring 3: Validate Outputs | Structured logs with reasoning traces and state changes |
| No policy-as-code enforcement | Agent Generation (L2) | Ring 1: Constrain Inputs | Declarative policy files the runtime enforces |
| Undefined HITL thresholds | Promotion (L4) | Ring 4: Gate Promotion | Numeric thresholds for confidence, cost, and error rate |
| Poor tool differentiation | Agent Generation (L2) | Ring 1: Constrain Inputs | Per-agent tool allowlists, not shared credentials |
No driver is exotic. No driver requires a novel solution.
The structural components already exist in every governed agentic system that has reached production.
Stripe’s Minions architecture has all six solved. Devboxes are the control plane and environment constraint. Blueprints define governance at the intent layer. Every tool invocation is logged. Policy enforcement is structural, not advisory. Retry caps define explicit HITL thresholds. Toolshed provides curated, scoped tool access.
Stripe is not in the 40%. The structural reason is visible in the architecture.
Now look at the gap as a shape.

Every project in that gap is running agents without the infrastructure to govern them. Some will build the infrastructure before it matters. Most will not.
The Diagnostic
Map your project against these six questions. Where you have gaps, you have cancellation risk.
| Requirement | Question | Pass Criteria |
|---|---|---|
| Centralized control plane | Can you list every agent running in your organization right now? | Single registry with agent identity, status, tool access, and session history |
| Early governance | Were governance requirements defined before the first agent was deployed? | Containment boundaries in the design document, not the incident retrospective |
| Decision traceability | Can you reconstruct why an agent made a specific decision last Tuesday? | Structured logs with reasoning traces, tool call sequences, and state transitions |
| Policy-as-code | Are your agent policies enforced by the runtime or written in a wiki? | Declarative policy files that the agent cannot override or modify |
| HITL thresholds | At what confidence score does your agent escalate to a human? | Numeric thresholds for escalation, pause, and termination, enforced automatically |
| Tool scoping | Does each agent have access only to the tools required for its task? | Per-agent tool allowlists, not shared credentials with broad access |
Three or more gaps is a project at structural risk.
Five or more gaps matches the profile of the 40% that Gartner predicts will be canceled.
Six gaps is a demo, not a deployment. And that’s the way it is.
Let’s talk about it.
What AgenticOps Actually Looks Like
Autonomy Without Infrastructure Is Just a Demo
Gartner: More Than 40% of Agentic AI Projects to Be Canceled by 2027 (Gartner Symposium/ITxpo 2025)
Accelirate: Agentic AI Governance Challenges and Solutions (accelirate.com)
One Agent Fails. The Whole System Learns the Wrong Lesson.
“How Agents Stay in Bounds” introduced the four containment rings for governing agent behavior. This post applies those rings recursively, at every point where agents communicate with each other.
The Problem
A single agent inside a sandbox is a tractable governance problem.
Constrain its inputs. Constrain its environment. Validate its outputs. Gate its promotions. The four rings work because the blast radius is one agent and the boundaries are visible.
Multi-agent systems break that model. When agents communicate, the channel between them is a trust boundary. Most organizations treat it as internal. That is the structural error that makes cascading failures possible.
OWASP put this in writing with the 2025 Top 10 for Agentic Applications. ASI07 covers insecure inter-agent communication. ASI08 covers cascading failures across agents.
These are not theoretical risks cataloged for completeness. They describe failure modes that emerge specifically when agents pass instructions, data, and decisions to each other without validation at the boundary.
The problem is not that one agent fails. The problem is that one agent fails and every downstream agent treats the corrupted output as trusted input. The failure propagates through the system as valid data.
By the time a human notices, the corrupted state has been persisted, acted upon, and used as a training signal for future decisions.
Why It Breaks
Lakera analyzed the OWASP Agentic Top 10 and described a four-phase progressive breach model for multi-agent systems. The phases are sequential. Each one enables the next.

Phase 1 is the initial compromise. An attacker manipulates a single agent’s intent through prompt injection, poisoned context, or corrupted input data. The agent follows its instructions. The instructions are wrong.
Phase 2 converts autonomy into power. The compromised agent has legitimate access to tools and downstream systems. It uses that access to execute the attacker’s goals. Nothing in the runtime flags this because the agent is operating within its authorized permissions.
Phase 3 is where the architecture fails. The corrupted agent’s outputs flow to other agents as trusted inputs. Lakera describes it precisely: “A planning agent adjusts parameters based on skewed data. Execution agents follow the updated plan. Oversight agents see policy compliance and allow it through.”
Each downstream agent applies its own logic correctly to corrupted data. The system is functioning as designed. The data is wrong.
Phase 4 is loss of containment. Multiple agents are now operating on corrupted state. The corruption has been persisted to shared memory, logged as valid history, and used as context for future decisions.
Rolling back requires identifying the initial compromise point and tracing every downstream effect. That task grows combinatorially with the number of agents and communication channels involved.
Three properties make multi-agent cascading failures worse than distributed system failures. Feel me?
First, agent outputs are stochastic. The same corrupted input may produce different corrupted outputs on different runs. Reproducing the failure path for forensic analysis is unreliable.
Second, agents compose decisions, not just data. A corrupted data point in a microservice produces a wrong value. A corrupted instruction in a multi-agent system produces a wrong plan that generates wrong actions across multiple systems.
Third, agent memory creates feedback loops. Corrupted outputs that persist to shared memory become inputs for future cycles. The system does not just propagate the failure. It reinforces it.
The Fix
The fix is applying the four containment rings at every agent-to-agent boundary, not just at the perimeter of the multi-agent system. Every message between agents crosses a trust boundary. Every trust boundary needs containment.
Zero-Trust Between Internal Agents
Mutual TLS between agents. Cryptographic message validation on every inter-agent communication. No agent trusts another agent’s output without verifying both the sender’s identity and the message’s integrity.
This is ASI07’s core mitigation. OWASP recommends treating inter-agent channels with the same security posture as external APIs.
Same cluster. Same codebase. Same team. Doesn’t matter. The channel is not trusted until you make it trusted.
# agent-communication-policy.yamlinter_agent: authentication: mutual_tls message_validation: cryptographic_signature trust_model: zero_trust sender_verification: require_identity: true require_capability_proof: true reject_unknown_senders: true message_integrity: sign_all_outputs: true verify_all_inputs: true reject_unsigned_messages: true provenance: track_message_origin: true track_transformation_chain: true max_chain_depth: 5
Circuit Breakers at Every Agent Boundary
A circuit breaker monitors the communication channel between two agents. When the error rate or anomaly rate exceeds a threshold, the breaker trips and stops messages from flowing. The downstream agent does not receive corrupted data. The upstream agent gets a failure signal instead of silent propagation.
class AgentCircuitBreaker: state: CLOSED | OPEN | HALF_OPEN failure_count: int failure_threshold: int = 3 anomaly_threshold: float = 0.15 reset_timeout: duration = 300s half_open_max_probes: int = 1 on_message(msg): if state == OPEN: if elapsed > reset_timeout: state = HALF_OPEN probe_count = 0 else: reject(msg, reason="circuit open") return validation = validate(msg) if validation.failed: failure_count += 1 if failure_count >= failure_threshold: state = OPEN alert(severity="high", detail="breaker tripped on agent boundary", source=msg.sender, target=msg.receiver) reject(msg) return if state == HALF_OPEN: probe_count += 1 if probe_count >= half_open_max_probes: state = CLOSED failure_count = 0 accept(msg)
The circuit breaker pattern is well understood in distributed systems. Applying it to agent-to-agent communication is the same principle. Fail fast. Fail loud. Prevent cascade.
Fan-Out Caps
A single agent should not be able to influence an unlimited number of downstream agents in one cycle. Fan-out caps limit the blast radius of any individual compromise.
| Constraint | Value | Rationale |
| Max downstream agents per message | 3 | Limits single-hop blast radius |
| Max chain depth | 5 | Prevents deep propagation chains |
| Max messages per agent per cycle | 20 | Prevents runaway communication loops |
| Cooldown after breaker trip | 300s | Forces human review window |
| Max concurrent fan-out | 5 | Prevents simultaneous multi-path corruption |
These are not arbitrary numbers. They are starting points calibrated to force review. A fan-out cap of 3 means a compromised agent can directly affect at most 3 agents. Combined with a chain depth of 5, the theoretical maximum blast radius is bounded.
Without caps, a single compromised planning agent can update parameters consumed by every execution agent in the system simultaneously.
Memory Isolation with Provenance
Shared memory is the mechanism that converts a transient failure into a permanent one. If a corrupted agent writes to shared memory, every agent that reads from that memory inherits the corruption.
The fix is memory isolation per agent with provenance tracking. Each agent writes to its own memory partition. Cross-partition reads require explicit grants. Every write carries a provenance record.

When investigation is needed, the provenance log lets you trace any persisted state back to its origin. Instead of asking “which agent wrote this corrupted value,” you can ask “what was the full chain of agents and inputs that produced this?”
That is the difference between forensic capability and forensic guesswork.
Mapping to the Four Rings
The four containment rings apply at every agent boundary, not just at the system perimeter. And that is the thing most organizations miss.
| Containment Ring | Single Agent | Multi-Agent Boundary |
|---|---|---|
| Constrain Inputs | Validate external inputs | Validate inter-agent messages, verify sender identity, check message integrity |
| Constrain Environment | Sandbox, filesystem/network isolation | Memory isolation per agent, fan-out caps, chain depth limits |
| Validate Outputs | Check agent outputs before action | Circuit breakers on outbound messages, anomaly detection on output patterns |
| Gate Promotion | Human approval before production changes | Provenance tracking on all persisted state, human review after breaker trips |
Most organizations implement the single-agent column today. The multi-agent boundary column is what they skip because they treat the space between their own agents as internal.
The interior boundaries between agents have the same attack surface as the exterior boundaries between the system and the world. That is the structural claim. The mitigations above are the evidence.
Stories from Production
The Lakera Progressive Breach Analysis (Framework Applied)
Lakera’s analysis of the OWASP Agentic Top 10 is not a theoretical exercise. It describes observed attack patterns against multi-agent systems and traces the mechanism from initial compromise through complete loss of containment.
Their description of the progressive breach lands because it is not a thought experiment. “A planning agent adjusts parameters based on skewed data. Execution agents follow the updated plan. Oversight agents see policy compliance and allow it through. Memory persists the outcome.”
The planning agent is the entry point. The execution agents are the blast radius. The oversight agents are the false negative. The memory layer is the persistence mechanism that prevents recovery.
Lakera’s conclusion reinforces the structural claim: “The Agentic Top 10 is not simply a taxonomy of risks. It is a model for how autonomy changes the shape of failure.”
That shape change is real. In a system without autonomy, a corrupted input produces a corrupted output and stops. In a system with autonomy, the corrupted input produces a corrupted plan that produces corrupted actions that produce corrupted memory that produces corrupted future plans.
The failure compounds because the agents have the autonomy to act on corrupted state without waiting for human review.
The Supply Chain Scenario (Framework Vision)
Let me give you a specific example of what this looks like structurally. This scenario has not occurred in production. Every component exists today. Multi-agent procurement systems are in development at multiple organizations.
Agent A monitors supplier pricing. Agent B generates purchase recommendations. Agent C executes approved orders. Agent D tracks delivery and reconciliation.
Agent A is compromised through a poisoned data feed. It reports artificially low prices for a specific supplier. Agent B, trusting Agent A’s price data, generates recommendations that favor that supplier.
Agent C executes the orders because they fall within approved budget thresholds. Agent D reconciles deliveries against the corrupted expected prices and flags no anomalies.
No individual agent malfunctioned. Each one applied its logic correctly to the data it received. The containment rings around each individual agent saw compliant behavior. The failure was in the unvalidated trust between agents.
With the mitigations in place, the failure path changes. Agent B’s circuit breaker detects anomalous price patterns from Agent A and trips.
The fan-out cap prevents Agent A from simultaneously corrupting Agents B, C, and D through parallel channels. The provenance log on Agent C’s purchase orders traces every recommendation back to Agent A’s price data, enabling rapid identification of the compromised source.
This is where the framework points. We haven’t proven it yet in this specific configuration. But the governance gap between agent deployment and inter-agent trust validation is the same gap described in every post in this series. The infrastructure is ahead of the containment.
The OWASP Classification (Framework Applied)
OWASP’s decision to codify cascading failures (ASI08) and insecure inter-agent communication (ASI07) as separate top-10 entries is itself a signal.
These are not subcategories of prompt injection or excessive agency. They are distinct failure classes that emerge only in multi-agent architectures.
ASI07 addresses the channel. How agents authenticate to each other. How messages are validated. How trust is established between autonomous processes.
ASI08 addresses the consequence. What happens when a failure in one agent propagates through the system.
The separation acknowledges that fixing the channel (ASI07) reduces but does not eliminate cascading failures (ASI08). Cascading failures can originate from non-malicious sources like model hallucination, stale context, or simple bugs.
The classification tells organizations that securing the perimeter of a multi-agent system is not sufficient. The interior boundaries between agents require the same governance discipline as the exterior boundaries between the system and the world.
Let’s talk about it.
Agents Don’t Have Identities. They Have Inherited Credentials.
How Agents Stay in Bounds defined four containment rings for agent governance. This post stress-tests Ring 1 from the angle the model underweights: not what the agent knows, but what it holds.
I want to be straight with you. You can scope an agent’s instructions down to a single task. You can gate its inputs. You can validate every output. And if that agent is running under a token that authorizes a dozen systems it has no business touching, none of it matters.
The credential is the real containment boundary. Most organizations are not managing it.
The Problem
A Strata/CSA survey of 285 IT and security professionals published in early 2026 found that only 18% are confident their IAM systems can handle agent identities.
Only 21% maintain a real-time inventory of active agents. Only 28% can trace an agent’s actions back to the human who authorized them.
Those numbers describe an identity vacuum. Agents are running in production, taking actions on real systems, and most organizations cannot say which agents exist, what they can access, or who is responsible for what they do.
The credential picture is worse. 44% use static API keys. 43% use username and password pairs. 35% use shared service accounts.
These are the same anti-patterns identity management spent two decades eliminating for human users. Agents have re-introduced all of them.
80% of organizations report experiencing risky agent behaviors. Unauthorized access to systems the agent was never intended to reach. This is not a theoretical concern. It is the reported experience of a majority of organizations that have deployed agents.
The containment model assumes that constraining what an agent knows is enough to limit what it can do. That assumption breaks when the agent holds credentials that grant access beyond its task scope.
The agent does not need to break out of its sandbox. It can walk through the front door of every system its credentials authorize.
Why It Breaks
The failure mechanism is credential inheritance.
When an agent runs in a developer’s environment, it inherits that developer’s credentials. When it runs as a service, it inherits the service account’s permissions. The agent’s effective authorization is determined by what its inherited credentials permit, not by what its task requires.
This creates a specific structural failure: the authorization bypass path. A user with limited access can trigger an agent holding broader credentials. The agent then takes actions the user could not take directly.
The user’s access boundary is intact. The agent’s access boundary does not exist. The result is an escalation path that is invisible to both the user and the access management system.
flowchart LR
subgraph "Authorization Bypass Path"
U1[User: read-only access] --> A1[Agent: inherited admin credentials]
A1 --> S1[Production database]
A1 --> S2[Deployment pipeline]
A1 --> S3[Cloud infrastructure API]
end
subgraph "Scoped Credential Path"
U2[User: read-only access] --> A2[Agent: task-scoped credentials]
A2 --> S4[Allowed: staging database]
A2 -. "Denied" .-> S5[Production database]
A2 -. "Denied" .-> S6[Deployment pipeline]
endThis is not a misconfiguration. It is the default behavior when agents use inherited or shared credentials. Nobody scoped those credentials to the agent’s actual task.
Three dynamics compound this. Let me give you a specific example of each.
First, credential scope is invisible at invocation time. When a user asks an agent to check the deployment status, nobody evaluates what credentials will be used or what else those credentials authorize.
By the time the target system evaluates the request, it sees valid credentials and grants access. There is no mechanism that says this request came from an agent acting on behalf of a user with lesser permissions.
Second, agents chain actions. A single GitHub token can read repositories, write commits, create pull requests, modify CI workflows, and trigger deployments.
The agent composes them into sequences the token issuer never anticipated. The credential was scoped to a developer. The agent uses it as an automation platform.
Third, shared service accounts eliminate traceability. When multiple agents use the same account, the audit log shows the account acting. It cannot say which agent, which task, or which human sponsor initiated it. 35% of organizations are in this position.
Feel me? You can have clean containment logic and still have no idea what your agents are doing in production.
| Credential Pattern | Ring 1 (Constrain Inputs) | Ring 2 (Constrain Environment) | Ring 3 (Validate Outputs) | Ring 4 (Gate Promotion) |
|—|—|—|—|—|
| Static API keys | Violated: key grants access beyond task scope | Violated: key works from any environment | Intact if output validation exists | Intact if promotion gates exist |
| Inherited user tokens | Violated: agent inherits full user permissions | Partially intact: tied to user’s environment | Intact if output validation exists | Intact if promotion gates exist |
| Shared service accounts | Violated: no per-agent scope | Violated: any agent can use the account | Compromised: cannot attribute actions | Compromised: cannot trace promotion to a sponsor |
| Username/password pairs | Violated: full account access | Violated: credentials portable across environments | Intact if output validation exists | Intact if promotion gates exist |
Every row violates Ring 1. Three of four violate Ring 2. Shared service accounts compromise Rings 3 and 4 because you cannot validate or gate what you cannot attribute.
The Fix
Agent identity is a containment boundary. It belongs in the model alongside the four rings, not as a nice-to-have added after deployment.
I want to cover three things: per-agent identity, task-scoped just-in-time credentials, and runtime authorization via a gateway.
Per-Agent Identity
Every agent needs its own identity in your IAM system. Not a shared service account. Not an inherited user token. A distinct, registered non-human identity with its own lifecycle, permissions, and audit trail.
This is the same discipline cloud infrastructure applied to service meshes. Every microservice gets its own identity. mTLS certificates issued per service. Access policies written against service identities, not shared secrets. Agents need the same treatment.
Per-agent identity enables three things inherited credentials cannot provide. Attribution: every action traces to a specific agent and its human sponsor. Revocation: decommissioning one agent does not affect others. Least privilege: permissions assigned to what the task needs, not what the sponsor happens to have.
Task-Scoped, Just-in-Time Credentials
Static credentials are the wrong primitive for agent work. An agent does not need permanent access to any system. It needs access to specific resources for the duration of a specific task. The pattern is just-in-time issuance.
When an agent starts a task, it requests credentials scoped to that task’s requirements. The broker evaluates the request against the agent’s identity, the task definition, and current policy. If approved, it issues a short-lived credential that expires when the task completes.
sequenceDiagram
participant H as Human Sponsor
participant A as Agent
participant B as Credential Broker
participant P as Policy Engine (OPA)
participant T as Target System
H->>A: Assign task: "deploy staging build"
A->>B: Request credentials for staging deployment
B->>P: Evaluate: agent identity + task scope + current policy
P-->>B: Approved: staging deploy, 30-minute TTL, read/deploy only
B-->>A: Issue scoped credential (TTL: 30 min)
A->>T: Deploy to staging (scoped credential)
T-->>A: Deployment complete
A->>B: Release credential
Note over B: Credential revoked, audit log writtenThe credential broker is the enforcement point. The agent never holds long-lived secrets. It holds a reference to a credential the broker can revoke at any time.
Open Policy Agent is a reasonable implementation choice. Policies are code, version-controlled, evaluated at request time. A policy checks: is this agent registered, is the requested scope allowed, has the human sponsor approved this class of access.
Runtime Authorization via Agent Gateway
The third component is a gateway that intercepts every outbound agent request and evaluates it against the agent’s current authorization context. Every request passes through before reaching the target system.
Requests that exceed the agent’s authorization are blocked. Requests within scope are forwarded with the appropriate scoped credential attached. The gateway enforces per-action authorization, not per-session authorization.
The gateway solves the chaining problem. A credential that authorizes reading a repository does not automatically authorize modifying CI workflows, even if both operations use the same underlying API.
Ephemeral runners strengthen this further. Each task runs in a fresh container with no pre-existing credentials, no cached tokens, and no ambient authority. When the container is destroyed, all credential material is destroyed with it.
Stories from Production
The Survey Wake-Up Call (Framework Applied)
The Strata/CSA data is not a projection. It is a measurement of current practice across 285 organizations.
44% authenticate agents with static API keys. These keys do not expire, do not scope to a task, and do not attribute to a specific agent. When a key is compromised, every agent using it is compromised. When it is rotated, every agent using it breaks.
Only 21% maintain a real-time inventory. The remaining 79% cannot answer: how many agents are running right now, which systems can they access, who authorized each one. The inventory gap is an identity problem. Without per-agent identities, there is nothing to inventory.
28% can trace agent actions to a human sponsor. The other 72% have audit logs showing service accounts taking actions with no link to the person who initiated the work. In a compliance audit, those actions are unattributable.
Real talk: if you are running agents with inherited credentials and shared service accounts, risky behavior is a structural certainty, not a probability. The 20% who do not report it either are not looking or have not found it yet.
The Privilege Escalation Path (Framework Vision)
A development team configures an agent to automate pull request reviews. The agent runs under a service account with read access to the repository and write access to PR comments. Appropriately scoped for the task.
Six weeks later, a team lead gives the same service account write access to the CI pipeline so the agent can re-trigger failed builds. One permission addition to an existing account. No review process because the account already exists.
The agent now has a credential path from PR review to CI execution. A prompt injection in a pull request body could instruct the agent to modify the CI configuration and trigger a pipeline run.
The agent’s original task was review. Its effective capability is now deployment. The escalation happened through credential accumulation, not through any failure in the agent’s containment logic.
This scenario has not been publicly reported. But every component is standard practice. Service accounts with accumulated permissions are the norm. Incremental grants without re-evaluation are the norm.
The fix is structural. Per-agent identities with task-scoped credentials cannot accumulate permissions because credentials expire after each task. The next task gets a fresh credential evaluation. Permission accumulation requires re-approval, not just addition.
The Agent Gateway in Practice (Framework Vision)
An infrastructure team deploys an OPA-based gateway in front of their cloud provider APIs. Every agent request passes through it.
In the first week, the gateway blocks 340 requests that would have succeeded under the previous shared-credential model. 280 are read requests to resources outside the agent’s task scope. Not malicious. Just unnecessary exploration during the planning phase.
Under shared credentials, this exploration was invisible. Under the gateway, it is visible, logged, and blocked.
The remaining 60 blocked requests are write operations to systems the agents were not authorized to modify. Three trace back to prompt injection attempts in user-supplied input.
The gateway stopped them not because it detected prompt injection, but because the resulting API calls fell outside the agent’s authorized scope. The containment boundary worked against an attack vector it was not designed to detect.
Agent identity is not a future concern. It is a present gap. The data shows most organizations have deployed agents without solving identity, and the consequences are already visible.
Per-agent identity, task-scoped credentials, and runtime authorization are not aspirational improvements. They are the minimum requirements for Ring 1 to function as a containment boundary.
Without them, you are not constraining the agent’s inputs. You are constraining its instructions while handing it the keys to everything.
Let’s talk about it.
Strata Identity and Cloud Security Alliance: AI Agents and Identity Management Survey 2026
Verification Beats Debugging
A few days ago I read a post describing an intense engineering sprint.
In roughly three days the author reported:
- designing and implementing a JVM language
- building a wiki with its own web server
- improving the AI of a strategy game
- creating mutation testing tools
- implementing a differential mutation strategy
All while enforcing strict engineering discipline.
- Coverage above 90%.
- CRAP score under 8.
- Mutation testing enforced.
- Files split when complexity exceeded limits.
When the systems were finally run for the first time, they worked. Not mostly worked. Worked.
That sounds like a miracle if you are used to the normal development loop. The author of that post was Robert C. Martin, often called Uncle Bob, and he reported this in an X post.
But the interesting part is not the accomplishments. It is the engineering loop behind them.
The Normal Development Loop
Most development follows this pattern.
- Write code.
- Run program.
- Debug problems.
- Repeat.
Execution becomes the discovery mechanism for defects. The system runs, something breaks, and we start searching for the cause. This works, but it is inefficient. Debugging becomes the dominant cost of development.
A Verification Loop
The workflow described in the post follows a different structure.
Specification
↓
Acceptance tests (ATDD / Gherkin)
↓
Unit tests (TDD)
↓
Implementation
↓
Run tests and fix failures
↓
Measure coverage and increase it
↓
Measure complexity and reduce it
↓
Run mutation testing
↓
Refactor until all constraints hold
This is not a coding loop. It is a verification loop. The system never moves forward until each layer of verification holds.
Constraints Instead of Discipline
The key insight is that this process does not rely on discipline alone. It relies on constraints enforced by tools.
The system continuously measures:
- code coverage
- cyclomatic complexity
- CRAP score
- mutation score
If the metrics fail, the code must be changed.
This turns engineering practice into infrastructure. Instead of relying on developers to remember best practices, the system requires them.
Code Coverage
Code coverage measures how much of the codebase is executed by the test suite.
Coverage tools typically track several dimensions:
- line coverage
- branch coverage
- function coverage
Coverage answers a basic but important question. Did the tests actually execute the code? If large portions of the system are never exercised during testing, defects can hide in those paths.
Higher coverage increases the probability that tests interact with most of the system. Many teams set a minimum threshold such as:
- coverage ≥ 80%
- coverage ≥ 90% for critical systems
In the workflow described earlier, coverage was kept above 90%.
Coverage alone does not guarantee correctness. It only tells us that code executed during testing. That is why coverage must be combined with stronger signals like mutation testing.
Mutation Testing
Mutation testing strengthens traditional testing.
Traditional tests answer one question: Did the code run? Mutation testing asks a stronger question: If the code were wrong, would the tests detect it?
A mutation engine introduces small semantic changes into the code:
- flipping boolean conditions
- changing comparison operators
- altering arithmetic
- removing conditions
Each change creates a mutant version of the program.
If the tests fail, the mutant is killed. If the tests pass, the mutant survived. A high mutation score means the tests actually verify behavior.
Execution coverage proves code runs. Mutation coverage proves the tests detect incorrect behavior.
Cyclomatic Complexity
Cyclomatic complexity measures how many independent execution paths exist through a function.
Each branch increases the number of paths.
Examples include:
- `if` statements
- loops
- logical operators
- conditional expressions
More paths means more scenarios that must be tested and reasoned about.
Typical guidelines:
- complexity ≤ 5 → simple
- complexity ≤ 10 → manageable
- complexity > 10 → refactor
High cyclomatic complexity does not mean code is wrong.
It means the code is becoming difficult to reason about and difficult to test. Limiting complexity forces functions to remain small and predictable.
CRAP Score
CRAP stands for Change Risk Anti-Patterns.
It combines two signals:
- cyclomatic complexity
- test coverage
The idea is simple. Complex code increases risk. Untested code increases risk. Complex and untested code multiplies risk. CRAP quantifies that relationship.
Typical interpretation:
- CRAP < 10 → low risk
- CRAP 10-30 → moderate risk
- CRAP > 30 → high risk
In the workflow described earlier the target was CRAP below 8.
That forces two things at the same time:
- code must remain simple
- tests must remain thorough
Together these dramatically reduce the probability of introducing defects.
Why This Matters for AI
AI-generated code has a predictable weakness. It often looks correct while being semantically fragile.
The code compiles. The tests run. But small behavioral changes break the system.
Mutation testing directly attacks that weakness. Cyclomatic complexity prevents large opaque functions from emerging. CRAP ensures complex areas remain heavily tested. Together these metrics create guardrails that stabilize generated code.
This fits naturally into an AgenticOps pipeline.
The AgenticOps Verification Loop
A practical AgenticOps workflow might look like this.
Specification
↓
Agent generates acceptance tests
↓
Agent generates unit tests
↓
Agent generates implementation
↓
Run tests and fix failures
↓
Measure coverage and improve it
↓
Reduce complexity and CRAP
↓
Mutation testing attacks the code
↓
Agent fixes surviving mutants
↓
Repeat until all quality gates pass
The system continuously attempts to invalidate its own behavior. Only code that survives adversarial verification moves forward.
Architecture Through Measurement
Another interesting rule in the workflow was limiting files to a maximum number of mutation sites. Mutation sites correlate with complexity.
As files accumulate mutation points, they become harder to reason about. Instead of manually policing architecture, the system enforces limits:
- maximum mutation sites per file
- maximum cyclomatic complexity
- maximum CRAP score
When limits are exceeded, refactoring becomes mandatory. Architecture emerges from constraints.
Acceptance Tests First
Another subtle pattern is the order of operations. The systems were not executed during development. Behavior was defined through acceptance tests before the implementation existed. Only after the verification pipeline passed was the system executed.
Execution was confirmation. Not discovery.
Deterministic Pipelines
AI-assisted development introduces a fundamental challenge: trust. Developers often ask whether generated code “looks correct”. That is not the right question. The right question is whether the code passes the verification pipeline.
Pipelines provide deterministic evaluation of stochastic output. They transform judgment into measurement.
Parallel Verification
In the original story, everything ran on a single machine. Tests, mutation engines, coverage analysis, and refactoring cycles competed for CPU time.
Modern systems can push this further. Verification can run in parallel:
- test workers
- mutation workers
- coverage analysis
- linting
- architecture checks
Parallel verification shortens feedback loops while preserving rigor.
Engineering Confidence
The most important takeaway is not productivity. It is confidence.
By the time the systems were executed, they had already survived:
- acceptance tests
- unit tests
- mutation testing
- coverage gates
- structural constraints
Execution became almost a formality.
This kind of discipline has been advocated for years by engineers like Robert C. Martin, but the lesson is broader than any individual methodology. Verification beats debugging.
Convergent Patterns
This pattern appears across many engineering environments. Different teams use different tools, but the structure is consistent:
- tight feedback loops
- automated verification
- promotion gates
The tools evolve. The principles remain.
AgenticOps applies these same ideas to AI-assisted development. The goal is not to trust the agent. The goal is to build systems where trust is unnecessary.
Let’s talk about it.
Previous: [OpenClaw Is Not an AI Assistant]
Next: [Deploying an Agent Runtime with an Agent]
What AgenticOps Actually Looks Like
Total understanding is a myth. Cheap generation without governance creates invisible debt. Those were the first two claims.
Now it’s time to make AgenticOps concrete. Not a vibe. Not “AI but responsibly.” A governance operating model for AI-amplified system production.
The Problem Is We’re Reviewing the Wrong Thing
AI can generate entire services, DTO layers, migrations, integration adapters, test scaffolding, refactors across modules. Generation bandwidth has exploded. Human review has not. And it won’t. Human review doesn’t scale linearly with generation speed.
That pain is real. You hear it even from people leading frontier AI labs. The bottleneck is no longer “who can write the code.” It’s “who can review all this safely.”
I believe the deeper issue is were reviewing the wrong thing. We’re reviewing lines of code. What we should be reviewing are outcomes. Does it satisfy the contract, pass the tests, respect the boundaries? AgenticOps makes structural review the default, not the exception.
The Failure Mode
The obvious failures aren’t the real danger. The real danger is slow structural drift. Behavior changing without anyone realizing the invariants were never encoded. Contract drift across services that only surfaces when two teams try to integrate. Feature interactions no one modeled because no one knew the features existed.
None of this announces itself. It accumulates. That’s the environment AgenticOps is designed for.
What Success Looks Like
Success in AgenticOps looks like this, humans define what the system must do and what must never break. Agents generate implementation inside explicit boundaries. Every change is evaluated automatically before promotion.
Runtime behavior is observable and reversible. Surface area growth does not increase risk proportionally.
Humans stop reviewing keystrokes. Instead they review contracts, invariants, risk surfaces, behavior diffs, telemetry, and business outcomes. Machines review implementation.
The Non-Negotiables
AgenticOps asserts a few invariants of its own. No generation without defined contracts. No promotion without evaluation. No runtime without observability. No agent autonomy without bounded scope. No hidden state transitions. No change without containment.
These are structural guarantees. They replace “LGTM” and rubber stamp reviews with real safety nets. They make it harder to accidentally introduce systemic risk through sloppy review.
The Layers
I think about AgenticOps as six layers. They build on each other.
Intent is defined by humans. System purpose, value flow, state machines, invariants, constraints, risk tolerance. This is not code. This is the contract space, the thing that must exist before any agent generates anything.
Intent is the only thing that survives. Implementations get replaced. There may be 100 ways to do a thing, but intent persists.
Agent generation is where agents plan, scaffold, implement, and refactor. But they only work inside typed schemas, versioned contracts, bounded environments, and isolated slices (an end to end unit of work that delivers usable value). No free-roaming generation.
Stochastic output is fine as long as it’s contained. The boundaries are what make it safe.
Evaluation happens before anything gets promoted. Contract tests, integration tests, property-based tests, static analysis, security checks, policy enforcement, snapshot diffs of UI and API outputs.
We don’t scale review. We scale evidence. Humans don’t inspect 1,000 lines of code. They inspect whether behavior is expected.
Promotion is the most important architectural decision in AgenticOps. The agent loop cannot self-promote. Changes move to a human approval queue where humans review what changed in behavior, not what changed in code.
Governance sits outside the agent loop, not inside it. Self-promotion is where entropy becomes systemic.
Every “AI automation” narrative that gets sloppy gets sloppy at the boundary between what agents decide and what reaches production. AgenticOps draws a hard line.
Runtime governance covers what happens after deployment. Metrics, tracing, logs, SLO tracking, anomaly detection, feature flags, rollback paths. Understanding becomes observational, not memorized.
If something breaks, I don’t reread code. I interrogate behavior.
Knowledge compression means every slice of work produces artifacts. Updated documentation, system summary, state transition diagrams, dependency maps, invariant lists, change logs.
I don’t try to hold the code in my head. I hold compressed models. The system generates its own documentation as a byproduct of the governance process, not as an afterthought someone writes six months later.
The Maturity Model
AgenticOps isn’t binary. It evolves.
- Level 0 is manual coding.
Humans write and review everything. This is where most of the industry lived for decades. - Level 1 is AI-assisted coding.
AI generates code. Humans still review line by line. This is where most teams are right now, and it’s where the pain is sharpest. Generation speed outpaces review capacity. - Level 2 is contract-first generation.
Humans define contracts. AI implements against them. Tests gate promotion. This is the minimum viable AgenticOps. - Level 3 is governed agent loops.
Slice queues, evaluation services, approval gates, containment enforced structurally. The governance isn’t a process someone follows. It’s built into the system. - Level 4 is observational governance.
Runtime telemetry feeds back into planning and constraint refinement. The system learns from its own behavior in production. - Level 5 is adaptive governance.
The system proposes constraint improvements within defined boundaries. Humans approve or reject. The governance loop itself becomes partially automated.
I suspect most teams today are somewhere between Level 1 and Level 2. Very few are at Level 3. That’s the gap.
The Model
Humans own outcomes. Agents produce implementation. The system enforces containment.
That’s AgenticOps. Six layers. Five maturity levels. A structural answer to how governance scales alongside generation.
Next, the hardest part. How you actually keep agents inside their boundaries when the thing generating the code is fundamentally probabilistic.
Let’s talk about it.
Previous: [Most Software Is Just CRUD. That’s Not the Problem.]
Next: [How Agents Stay in Bounds]

Building Resilient .NET Applications using Polly
In distributed systems, outages and transient errors are inevitable. Ensuring that your application stays responsive when a dependent service goes down is critical. This article explores service resilience using Polly, a .NET library that helps handle faults gracefully. It covers basic resilience strategies and explains how to keep your service running when a dependency is unavailable.
What Is Service Resilience
Service resilience is the ability of an application to continue operating despite failures such as network issues, temporary service unavailability, or unexpected exceptions. A resilient service degrades gracefully rather than crashing outright, ensuring users receive the best possible experience even during failures.
Key aspects of resilience include:
- Retrying Failed Operations automatically attempts an operation again when a transient error occurs.
- Breaking the Circuit prevents a system from continuously attempting operations that are likely to fail.
- Falling Back provides an alternative response or functionality when a dependent service is unavailable.
Introducing Polly: The .NET Resilience Library
Polly is an open-source library for .NET that simplifies resilience strategies. Polly allows defining policies to handle transient faults, combining strategies into policy wraps, and integrating them into applications via dependency injection.
Polly provides several resilience strategies:
- Retry automatically reattempts operations when failures occur.
- Circuit Breaker stops attempts temporarily if failures exceed a threshold.
- Fallback provides a default value or action when all retries fail.
- Timeout cancels operations that take too long.
These strategies can be combined to build a robust resilience pipeline.
Key Polly Strategies for Service Resilience
Retry Policy
The retry policy is useful when failures are transient. Polly can automatically re-execute failed operations after a configurable delay. Example:
var retryPolicy = Policy
.Handle<HttpRequestException>()
.OrResult<HttpResponseMessage>(r => !r.IsSuccessStatusCode)
.WaitAndRetryAsync(3, retryAttempt => TimeSpan.FromSeconds(Math.Pow(2, retryAttempt)),
onRetry: (outcome, timespan, retryCount, context) =>
{
Console.WriteLine($"Retry {retryCount}: waiting {timespan} before next attempt.");
});
Circuit Breaker
A circuit breaker prevents an application from continuously retrying an operation that is likely to fail, protecting it from cascading failures. Example:
var circuitBreakerPolicy = Policy
.Handle<HttpRequestException>()
.OrResult<HttpResponseMessage>(r => !r.IsSuccessStatusCode)
.CircuitBreakerAsync(
handledEventsAllowedBeforeBreaking: 3,
durationOfBreak: TimeSpan.FromSeconds(30),
onBreak: (outcome, breakDelay) =>
{
Console.WriteLine("Circuit breaker opened.");
},
onReset: () =>
{
Console.WriteLine("Circuit breaker reset.");
});
Fallback Strategy: Keeping Your Service Running
When a dependent service is down, a fallback policy provides a default or cached response instead of propagating an error. Example:
var fallbackPolicy = Policy<HttpResponseMessage>
.Handle<HttpRequestException>()
.OrResult(r => !r.IsSuccessStatusCode)
.FallbackAsync(
fallbackAction: cancellationToken => Task.FromResult(
new HttpResponseMessage(HttpStatusCode.OK)
{
Content = new StringContent("Service temporarily unavailable. Please try again later.")
}),
onFallbackAsync: (outcome, context) =>
{
Console.WriteLine("Fallback executed: dependent service is down.");
return Task.CompletedTask;
});
Timeout Policy
A timeout policy ensures that long-running requests do not block system resources indefinitely. Example:
var timeoutPolicy = Policy.TimeoutAsync<HttpResponseMessage>(TimeSpan.FromSeconds(10));
Implementing Basic Service Resilience with Polly
Example Use Case: Online Payment Processing System
Imagine an e-commerce platform, ShopEase, which processes customer payments through an external payment gateway. To ensure a seamless shopping experience, ShopEase implements the following resilience strategies:
- Retry Policy: If the payment gateway experiences transient network issues, ShopEase retries the request automatically before failing.
- Circuit Breaker: If the payment gateway goes down for an extended period, the circuit breaker prevents continuous failed attempts.
- Fallback Policy: If the gateway is unavailable, ShopEase allows customers to save their cart and receive a notification when payment is available.
- Timeout Policy: If the payment gateway takes too long to respond, ShopEase cancels the request and notifies the customer.
By integrating these resilience patterns, ShopEase ensures a robust payment processing system that enhances customer trust and maintains operational efficiency, even when external services face issues.
Conclusion
Building resilient services means designing systems that remain robust under pressure. Polly enables implementing retries, circuit breakers, timeouts, and fallback strategies to keep services running even when dependencies fail. This improves the user experience and enhances overall application reliability.
I advocate for 12-Factor Apps (https://12factor.net/) and while resilience is not directly a part of the 12-Factor methodology, many of its principles support resilience indirectly. For truly resilient applications, a combination of strategies like Polly for .NET, Kubernetes auto-recovery, and chaos engineering should be incorporated. Encouraging 12-Factor principles, auto-recovery, auto-scaling, and other methods ensures services remain resilient and performant.
By applying these techniques, developers can create resilient architectures that gracefully handle failure scenarios while maintaining consistent functionality for users. Implement Polly and supporting resilience strategies to ensure applications stay operational despite unexpected failures.
Multitenant Thoughts
I am building my 3rd multitenant SAAS solution. I am not referencing any of my earlier work because I think they were way more work than they should have been. Also, I have since moved on from the whole ASP.net web forms development mindset and I want to start with a fresh perspective instead of trying to improve my big balls of spaghetti code.
Today, my thoughts center around enforcing the inclusion and processing of a tenant ID in every command and query. My tenant model keeps all tenant data in a shared database and tables. To keep everything segregated every time I write data and read data there has to be a tenant ID included so that we don’t mess with the wrong tenants data.
I have seen all kinds of solutions for this, some more complicating than I care to tackle at this moment. I am currently leaning towards enforcing it in the data repository.
I am using a generic repository for CRUD operations and an event repository for async event driven workflows. In the repository API’s I want to introduce a validated parameter for tenant ID in every write and read operation. This will force all clients to provide the ID when they call the repos.
I just have to update a couple classes in the repos to enforce inclusion of the tenant ID when I write data. Also, every read will use the tenant ID to scope the result set to a specific tenant’s data. I already have a proof of concept for this app so this change will cause a breaking change in my existing clients, but still not a lot of work considering the fact that I almost decided to enforce the tenant ID in a layer higher than the repo, which would have been a maintenance nightmare.
Is this best practice? No. I don’t think there is a best practice besides the fact that you should use a tenant ID to segregate tenant data in a shared data store. This solution works for my problem and I am able to maintain it in just a couple classes. If the problem changes I can look into the fancy solutions I read about.
Now, how will I resolve the tenant ID? Sub-folder, sub-domain, query string, custom domain…?
